数据结构与算法(1)----->排序
这一版块,把必备的数据结构和算法做一个总结!包括排序、队列、链表、二叉树、排组合,动态规划......。
总结的过程包括理论部分,练题目可以自己去leetcode/牛客网刷起来~
第一篇文章讲排序~
1. 经典的排序算法
分为时间复杂度为 O(n的平方)的: 冒泡排序、选择排序、插入排序;
时间复杂度为 O( n 乘 log N)的: 归并排序、快速排序、堆排序、希尔排序
时间复杂度为 O(n)的排序算法:计数排序算法、基数排序算法;
1.1 冒泡排序
冒泡排序的时间复杂度为 O(n的平方)。
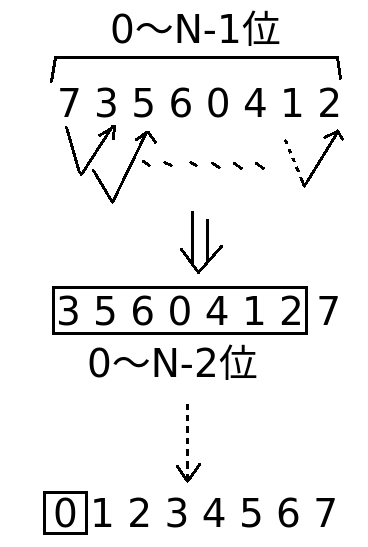
例如一个数组: 7 3 5 6 0 4 1 2
冒泡排序思路:(对比下图来看)
- 第一次交换区间是0~N-1,第一和第二个数字进行比较,大的数字放在后面;接着第二第三个数字进行比较,同样,大的放在后面。如此,依次进行交换,直到换到最后一个数N-1。这样,最大的数字就到了N-1位置;
- 第二次交换的区间变为0~N-2(最后一个数字不需要再移动了),比较方法类似步骤一;最后,第二大的数字到达了N-2的位置;
- 依次交换,直到最后一次交换区间变为0,整个数组此时已经变得有序,结束。
图画得有点丑,将就着看吧~
1.2 选择排序
选择排序的时间复杂度为 O(n的平方)。
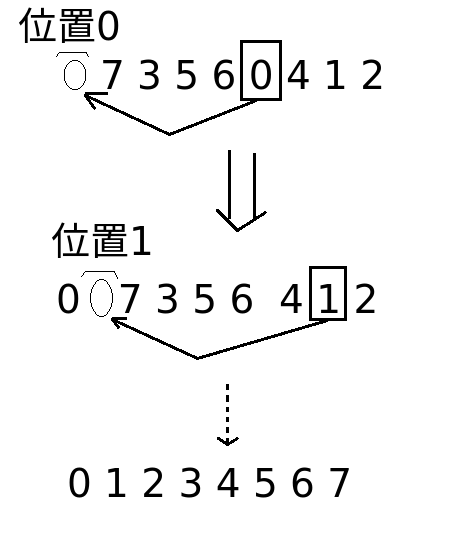
例如一个数组: 7 3 5 6 0 4 1 2
选择排序思路:
- 第一次在区间0~N-1中,选出数组的最小值放到位置0上;
- 第二次在在区间1~N-1中,选出最小值放到位置1上;
- 依次选择,直到最后选择到最后的数值,放到N-1位置上;结束。
这个图画得好看点儿了吧~
1.3 插入排序
插入排序的时间复杂度为 O(n的平方)。
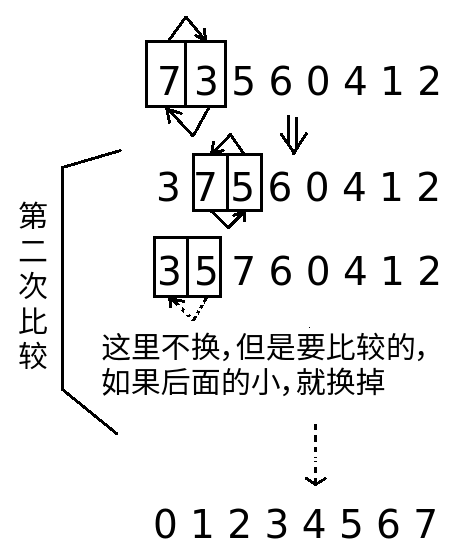
例如一个数组: 7 3 5 6 0 4 1 2
插入排序思路:
- 第一次,对第0和第1位置上的数字进行比较小放左边(前),大的方右边(后);
- 第二次,对第1位置和第2位置进行比较,选出较小值放到位置1上,较大值也就到了第2位置;这个时候需要对第1位置和第2位置再次进行比较,最小的放到最前;
- 依次比较下去,直到最后比较到最后的第N-1位置的数值和第N-2位置大的数值比较,较小的依次与前面的各个位置比较置换,比较到第0和第1位置之后结束。
画图好麻烦啊!!
1.4 归并排序
归并排序的时间复杂度为 O( n 乘 log N)。
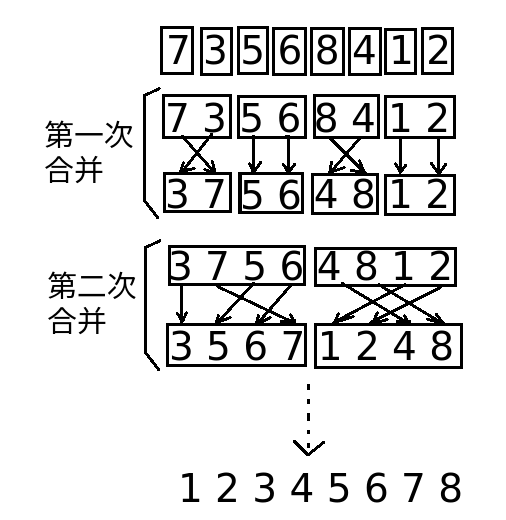
例如一个数组: 7 3 5 6 8 4 1 2
归并排序思路:
- 第一次,把划分成为N个小区间;相邻两两区间进行合并,得到N/2个有序区间
- 第二次,把相邻的区间再次合并,得到N/4个有序区间;
- 依次类推,直到把最后两个有序区间合并成一个区间,结束;
如图:
1.5 快速排序(划重点!!!很重要)
快速排序的时间复杂度为 O( n 乘 log N)。
例如一个数组: 7 3 5 6 0 4 1 2
快速排序思路:
- 随机选择数组中的一个元素,把小于等于该数的元素统一放在数组的左边,大于该数的元素放在数组的右边;
- 分别对左右两个部分,再次采用快排思路,随机在期间找一个元素,同样,大于的右侧,小于等于的放在左侧;
- 依次递归下去,完成排序。
画图好麻烦啊!!

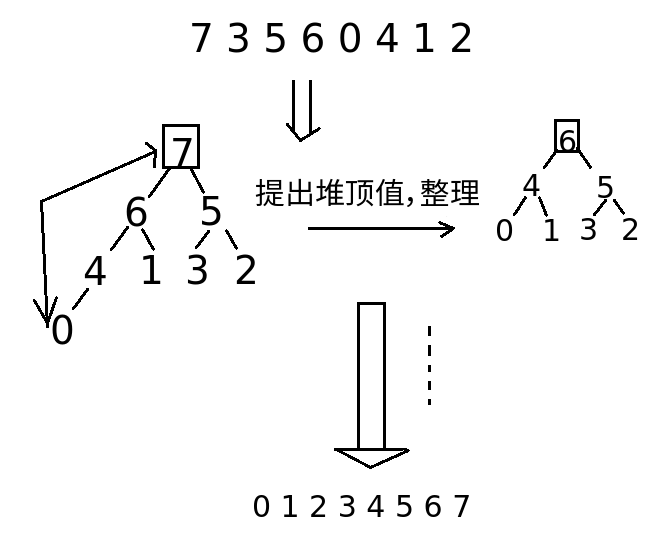
1.6 堆排序
堆排序的时间复杂度为 O( n 乘 log N)。
例如一个数组: 7 3 5 6 0 4 1 2
堆排序思路:
- 将堆写成由大到小的堆分支;堆顶为最大值
- 将堆顶元素提出,堆顶元素放到右侧,脱离堆;
- 将新的堆(N-1个元素)进行调整,重复步骤1、2,直到完成最后一个元素,结束。
画图好麻烦啊!!
1.7 希尔排序
希尔排序的时间复杂度为 O( n 乘 log N)。希尔排序是插入排序的一种改良做法。
插入排序前面已经介绍过了,可以知道,插入排序是1位一位往前比较的(步长为1)。而希尔排序初始步长为 >1,遍历结束之后步长减少1,直到最后步长为1时遍历完成,这样结束。
例如一个数组: 7 3 5 6 0 4 1 2
希尔排序思路:
- 假设初始步长为3(自己设置的),从第四位元素和第一位元素进行比较,大小为逆序则交换两者位置,大小为顺序则保留原位置;
- 接着比较第5位和第2位(5往前跑步长3啊),同理,大小为逆序则交换两者位置,大小为顺序则保留原位置;
- 依次类推,完成这一轮次的比较;
- 接着降低步长变为2,同样的方法
- 最后步长为1,遍历完成后结束排序。
下面这个图做的是步长为3的,降低步长方法一致,这里不画了~

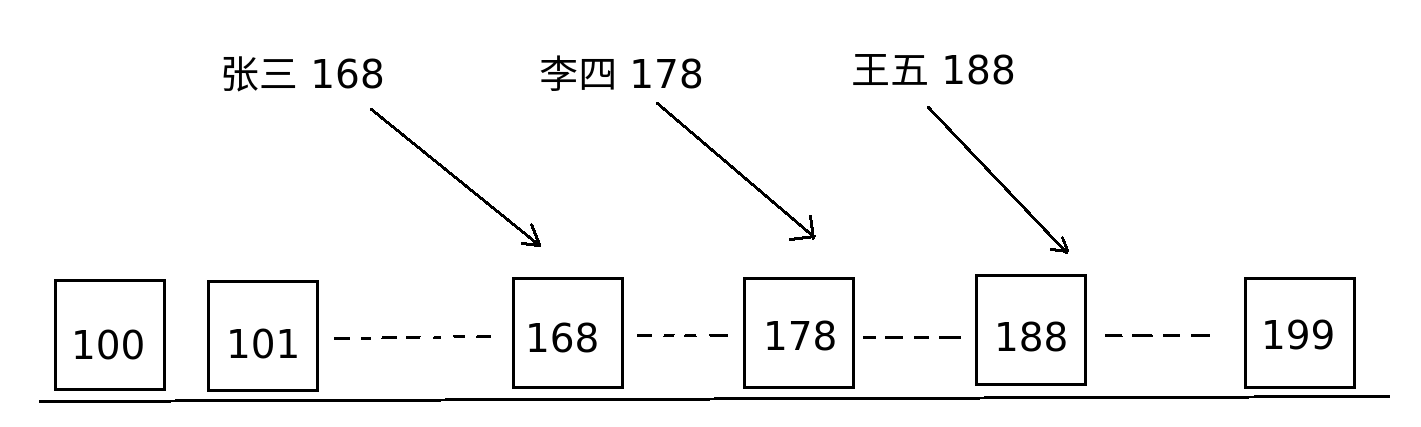
1.8 计数排序(源于桶排序思想)
时间复杂度为O(N)。举个例子说明他的思想。
例如:对 张三(168) 李四(178) 王五(188) 的身高排序;
其思路是,建立N个桶,比如100,101,102,...,199(共100个桶),接着将张三,李四,王五放入自己对应的桶中。最后,依次将100~199桶中的数倒出来,也就得到了他们的身高顺序了。
看图:
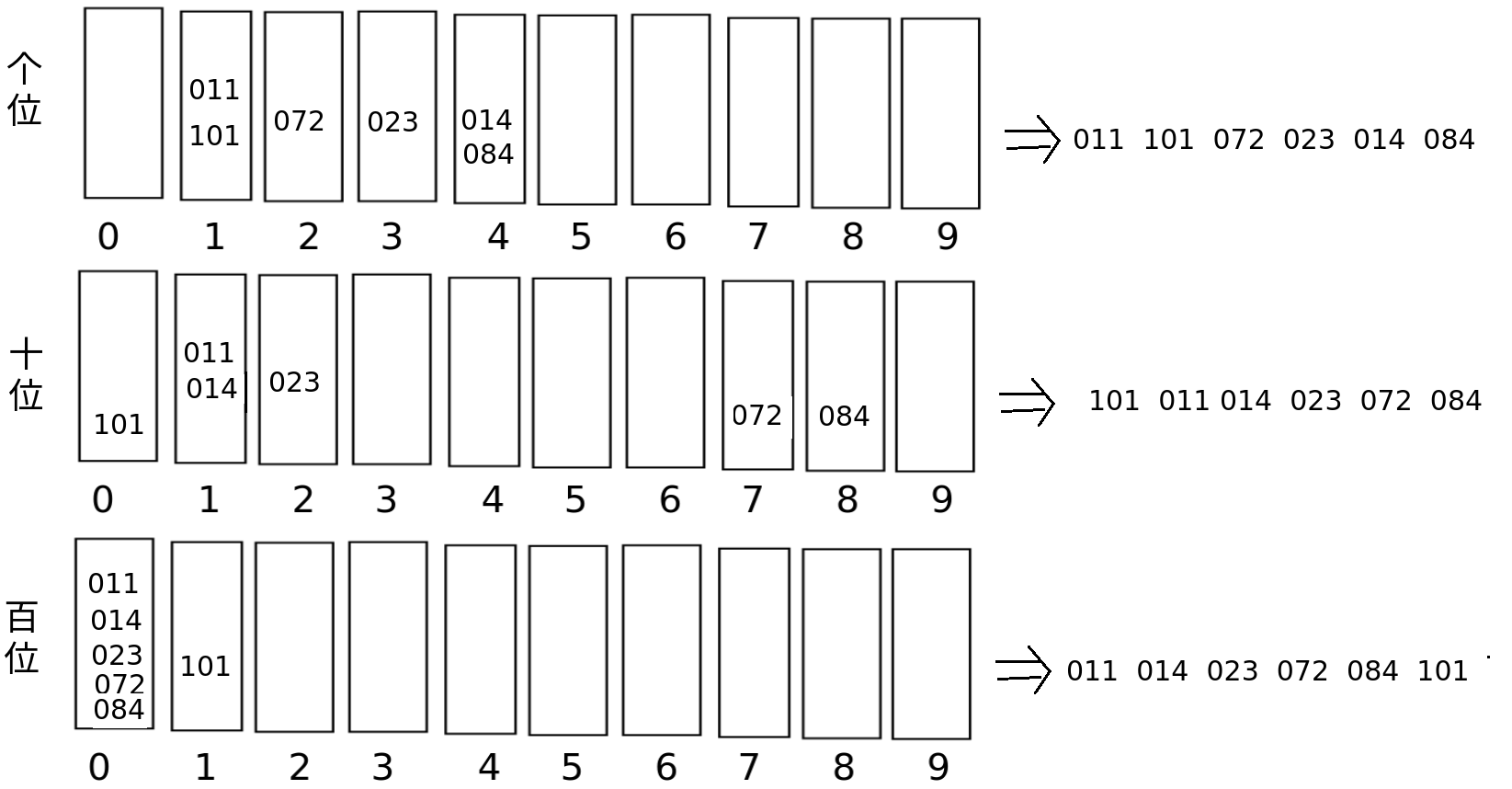
1.9 基数排序 (源于桶排序思想)
数组元素本身,先按照个位进行排序,放入0~9号桶中;再按照十位排序,放到桶中,依次上升百位...
例如: 对 011 014 023 072 084 101 进行排序
2. 经典排序算法空间复杂度、稳定性
空间复杂度:
| 空间复杂度 | 算法 |
| O(1) | 插入排序、选择排序、冒泡排序、堆排序、希尔排序 |
| O(log N) | 快速排序 |
| O(N) | 归并排序 |
| O(M) | 计数排序、基数排序 |
稳定性:(是否破坏相邻性,破坏则不稳定)
| 稳定的排序算法 | 插入排序、冒泡排序、归并排序、计数排序、基数排序、桶排序 |
| 不稳定的排序算法 | 希尔排序、选择排序、快速排序、堆排序 |
数据结构与算法(1)----->排序的更多相关文章
- javascript数据结构与算法--高级排序算法
javascript数据结构与算法--高级排序算法 高级排序算法是处理大型数据集的最高效排序算法,它是处理的数据集可以达到上百万个元素,而不仅仅是几百个或者几千个.现在我们来学习下2种高级排序算法-- ...
- 在Object-C中学习数据结构与算法之排序算法
笔者在学习数据结构与算法时,尝试着将排序算法以动画的形式呈现出来更加方便理解记忆,本文配合Demo 在Object-C中学习数据结构与算法之排序算法阅读更佳. 目录 选择排序 冒泡排序 插入排序 快速 ...
- javascript数据结构与算法--高级排序算法(快速排序法,希尔排序法)
javascript数据结构与算法--高级排序算法(快速排序法,希尔排序法) 一.快速排序算法 /* * 这个函数首先检查数组的长度是否为0.如果是,那么这个数组就不需要任何排序,函数直接返回. * ...
- javascript数据结构与算法--基本排序算法(冒泡、选择、排序)及效率比较
javascript数据结构与算法--基本排序算法(冒泡.选择.排序)及效率比较 一.数组测试平台. javascript数据结构与算法--基本排序(封装基本数组的操作),封装常规数组操作的函数,比如 ...
- python 数据结构与算法之排序(冒泡,选择,插入)
目录 数据结构与算法之排序(冒泡,选择,插入) 为什么学习数据结构与算法: 数据结构与算法: 算法: 数据结构 冒泡排序法 选择排序法 插入排序法 数据结构与算法之排序(冒泡,选择,插入) 为什么学习 ...
- Java数据结构和算法 - 高级排序
希尔排序 Q: 什么是希尔排序? A: 希尔排序因计算机科学家Donald L.Shell而得名,他在1959年发现了希尔排序算法. A: 希尔排序基于插入排序,但是增加了一个新的特性,大大地提高了插 ...
- Java数据结构和算法 - 简单排序
Q: 冒泡排序? A: 1) 比较相邻的元素.如果第一个比第二个大,就交换它们两个; 2) 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对.在这一点,最后的元素应该会是最大的数; 3) 针 ...
- 数据结构与算法——常用排序算法及其Java实现
冒泡排序 原理:依次比较相邻的两个数,将小数放在前面(左边),大数放在后面(右边),就像冒泡一样具体操作:第一趟,首先比较第1个和第2个数,将小数放前,大数放后.然后比较第2个数和第3个数,将小数放前 ...
- 数据结构与算法系列——排序(4)_Shell希尔排序
1. 工作原理(定义) 希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本.但希尔排序是非稳定排序算法. 希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入 ...
- javascript数据结构与算法--基本排序算法分析
javascript中的基本排序算法 对计算机中存储的数据执行的两种最常见操作是排序和检索,排序和检索算法对于前端开发尤其重要,对此我会对这两种算法做深入的研究,而不会和书上一样只是会贴代码而已,下面 ...
随机推荐
- Windows zip安装MySQL
1. mysqld初始化时my.ini的第二个默认位置是%windir%/my.ini rem 1.查看此变量对应的目录,在此目录下编辑 my.ini,mysqld会自动找到 echo %WINDIR ...
- Xamarin.Android 引导页
http://blog.csdn.net/qq1326702940/article/details/78665588 https://www.cnblogs.com/catcher1994/p/555 ...
- admin
执行顺序 : Admin 执行admin.py,导入models 第一次进来的时候,先创建admin.site对象(如果下次再有引入,不会重新创建) 拿到对象后执行该对象下的register()方法 ...
- RAID常用级别的比较
[转]RAID常用级别的比较 特点 硬盘及容量 性能及安全 典型应用 raid 0 用于平行存储,即条带.其原理是把连续的数据分成几份,然后分散存储到阵列中的各个硬盘上.任何一个磁盘故障,都将导致数据 ...
- Python新式类与经典类的区别
1.新式类与经典类 在Python 2及以前的版本中,由任意内置类型派生出的类(只要一个内置类型位于类树的某个位置),都属于“新式类”,都会获得所有“新式类”的特性:反之,即不由任意内置类型派生出的类 ...
- 阻止form空表单提交----JavaScript
网上看到很不错的阻止form空表单提交 第一种方法 <div class="warp"> <h2>登录到pfan空间</h2> <p> ...
- TPYBoard v102的GPIO使用用法
引脚介绍 引脚是控制I/O引脚的基本对象.它可以设置引脚输入.输出等的方式或者获取和设置数字逻辑电平的.对于模拟控制引脚,请参见ADC类.TPYBoard一共有68根针脚,26个3.3V,VIN接口: ...
- onoffswitch-checkbox
@foreach (EmailSubscription es in Model) { if(true){ <div class="onoffswitch"> ...
- SuperSocket入门(四)-命令行协议
前面已经了解了supersocket的一些基本的属性及相关的方法,下面就进入重点的学习内容,通信协议.在没有看官方的文档之前,对于协议的理解首先想到的是TCP和UDP协议.TCP 和 UDP ...
- Hyperledger Fabric 1.0 从零开始(十二)——fabric-sdk-java应用【补充】
在 Hyperledger Fabric 1.0 从零开始(十二)--fabric-sdk-java应用 中我已经把官方sdk具体改良办法,即使用办法发出来了,所有的类及文件都是完整的,在文章的结尾也 ...