Sql Server——查询(二)
上次写了查询里的一些简单的查询方法,如果说上次的是初级查询,那这次的就是高级查询了。
今天主要是聚合函数、分组查询、连接查询、联合查询。在我看来前三个挺简单的,稍微难理解点的也就最后一个,为什么呢?因为在一个查询里面会用到多个查询语句,这样看起来就复杂些,也就难点。
聚合函数
在平时,聚合函数使用率最多的也就那么几个,其它的你有兴趣也可以去了解。
求最大值:max()
求最小值:min()
求总和:sum()
求平均值:avg()
求行数:count()
用法:select 聚合函数 from 表名 如:select count(*) from stuInfo ---->求stuInfo表中的总人数,因为一个人是一行数据,总的行数就是总人数,* 号和前面一样代表所有列,当然,* 号也可以改为要求的列名;如 求一个班的男生总人数: select count(*) from stuInfo where sex='男' ---->这里只需在后面加个where子句就可以了。
注意:聚合函数后面的括号里写的是要求的列名,聚合函数不能和列名一起使用,如 select max(score), stuId(这是一个列名) from stuInfo 这样的写法就是错误的。
分组查询
分组查询需要用到 group by 子句。
如: select count(*) as 人数, sex as 性别 from stuInfo group by sex ----->查询出班上男女人数总数。 查询男女人数分别为多少,我们就可以将数据分为男或女两组,group by 后面写的就是依据什么分组的列名(也就是说根据什么分组我们就写它的列名就可以了)。
再来一个栗子:
查询班上每个人及格的科目数量 首先我们要知道,我们需要的数据是分数大于60的,也就是说,分数小于60的数据我们就要将它过滤掉。 过滤后的数据就是及格的,然后再对它进行分组求和就可以了。
select count(*) as 及格数量, stuid as 学号 from stuInfo
where socre>60 --过滤数据,注意:where子句只能写在group by子句前面且后面不能跟聚合函数
group by stuid --根据学号对现有数据进行分组,求的是每个人的,所以要以学号来分组
最后来个难点的栗子:
上面我们说了where子句不能写在group by 子句后面,那如果我们要先分组后再来求和呢? 比如求班上人及格数量小于3门的人,这里我们就要先用where子句将分数小于60的数据过滤掉,再根据学号对每个人进行分组,分组后我们还要筛选出及格数量小于3门的。既然不能使用where子句,那我们可以使用having子句,专门解决这一问题。
Sql语句为:select count(*) as 数量, stuId as 学号 from stuInfo
where score>60 --过滤不及格的数据
group by stuId --根据学号进行分组
having count(*)<3 --筛选出分组后行数小于3的,也就是及格数量小于3的
having 用于group by 子句后,而且可以跟聚合函数
where子句用于分组前的筛选,不能跟聚合函数;having子句用于分组后的筛选,可以跟聚合函数。
连接查询
我们知道,在数据库中规定一个表只能描述一件事情,那在查询中我们需要查询多个表的内容怎么办呢?这时我们就可以使用连接查询。
连接查询有:内连接、外连接、交叉连接
内连接:(inner join) 查询两个表公共部分
1.等值连接 “=”
select * from 表名一 inner join 表名二 on 表名一.主键=表名二.外键
举个栗子,如下面两张表,现在将它们连接起来
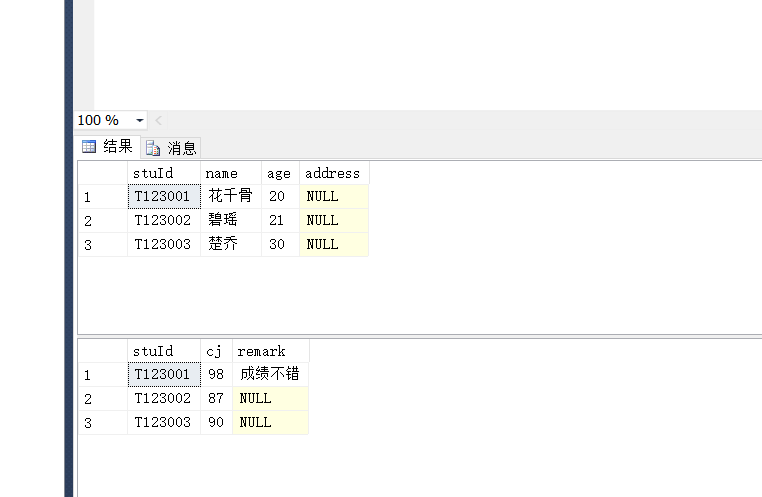
通过等值连接后就是这样
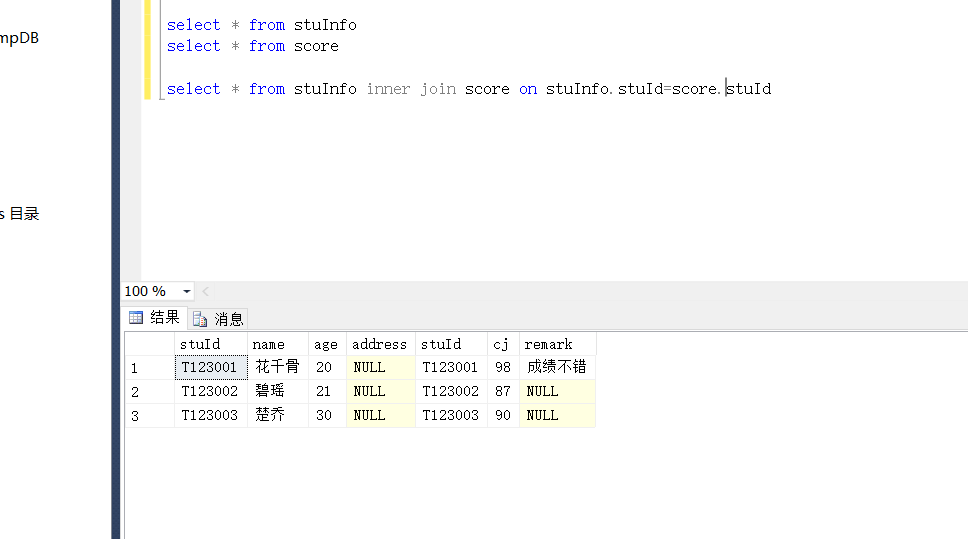
不等连接
概念:在连接条件中使用除等于号之外运算符(>、<、<>、>=、<=、!>和!<)
看看效果吧
<>

>

<
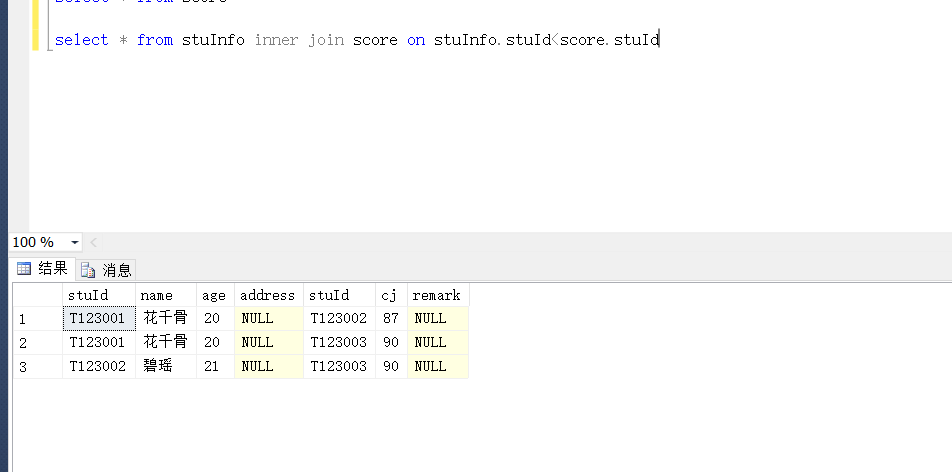
这里就举这几个栗子了,剩下的就你自己去试了。
刚刚已经说了,内连接显示的是两个表的公共部分,即使是空值它也会以NULL代替显示。
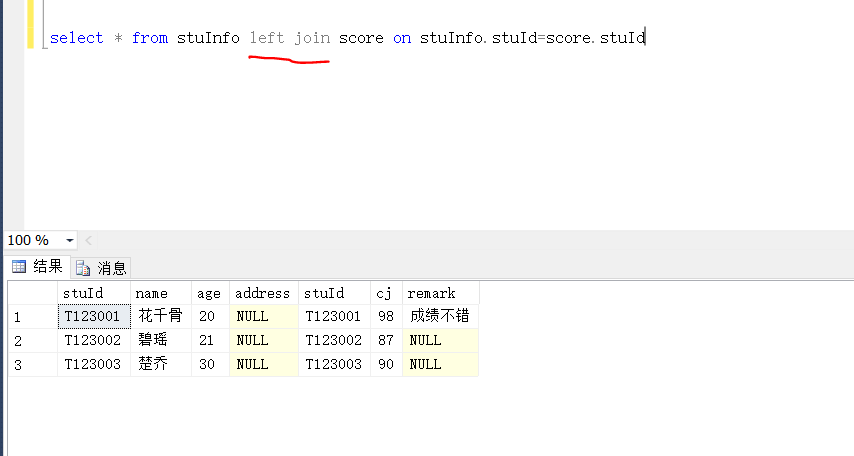
外连接
左连接: 返回左表中的所有行,如果左表中行在右表中没有匹配行,则结果中右表中的列返回空值。
语法上只是大同小异,把inner改为left就可以了
还是上面两个表:
右连接: 恰与左连接相反,返回右表中的所有行,如果右表中行在左表中没有匹配行,则结果中左表中的列返回空值。
只需把inner改为right就可以了,这里我就不详细介绍了。
全连接:返回左表和右表中的所有行。当某行在另一表中没有匹配行,则另一表中的列返回空值
只需把inner改为full就可以了。
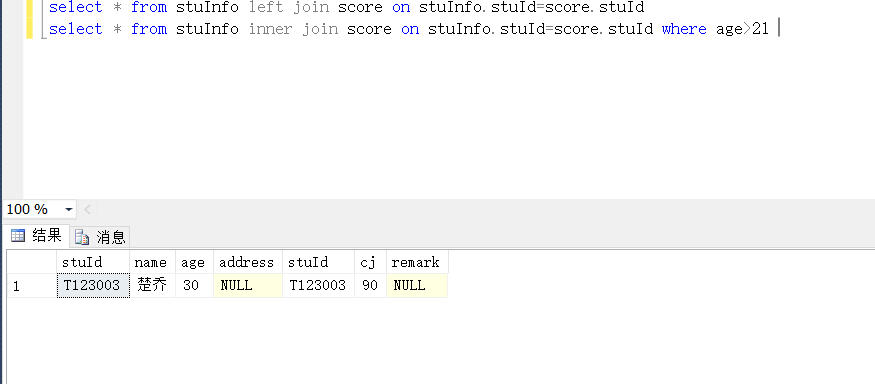
最后就是联合查询,联合查询就是多个查询语句配合使用,写在一个Sql语句里面。
如:查询年龄大于21岁的,我们只需加个where子句进行筛选就可以了。
上面的文章也许你看不懂,但你可以加我QQ 1289747698 和我在线讨论哦!Welcome。
Sql Server——查询(二)的更多相关文章
- SQL Server查询性能优化——堆表、碎片与索引(二)
本文是对 SQL Server查询性能优化——堆表.碎片与索引(一)的一些总结. 第一:先对 SQL Server查询性能优化——堆表.碎片与索引(一)中的例一的SET STATISTICS IO之 ...
- SQL Server查询性能优化——覆盖索引(二)
在SQL Server 查询性能优化——覆盖索引(一)中讲了覆盖索引的一些理论. 本文将具体讲一下使用不同索引对查询性能的影响. 下面通过实例,来查看不同的索引结构,如聚集索引.非聚集索引.组合索引等 ...
- [转] 利用SET STATISTICS IO和SET STATISTICS TIME 优化SQL Server查询性能
首先需要说明的是这篇文章的内容并不是如何调节SQL Server查询性能的(有关这方面的内容能写一本书),而是如何在SQL Server查询性能的调节中利用SET STATISTICS IO和SET ...
- SQL SERVER 查询性能优化——分析事务与锁(五)
SQL SERVER 查询性能优化——分析事务与锁(一) SQL SERVER 查询性能优化——分析事务与锁(二) SQL SERVER 查询性能优化——分析事务与锁(三) 上接SQL SERVER ...
- SQL Server 查询性能优化 相关文章
来自: SQL Server 查询性能优化——堆表.碎片与索引(一) SQL Server 查询性能优化——堆表.碎片与索引(二) SQL Server 查询性能优化——覆盖索引(一) SQL Ser ...
- 利用SET STATISTICS IO和SET STATISTICS TIME 优化SQL Server查询性能
首先需要说明的是这篇文章的内容并不是如何调节SQL Server查询性能的(有关这方面的内容能写一本书),而是如何在SQL Server查询性能的调节中利用SET STATISTICS IO和SET ...
- SET STATISTICS IO和SET STATISTICS TIME 在SQL Server查询性能优化中的作用
近段时间以来,一直在探究SQL Server查询性能的问题,当然也漫无目的的查找了很多资料,也从网上的大神们的文章中学到了很多,在这里,向各位大神致敬.正是受大神们无私奉献精神的影响,所以小弟也作为回 ...
- 数据库表设计时一对一关系存在的必要性 数据库一对一、一对多、多对多设计 面试逻辑题3.31 sql server 查询某个表被哪些存储过程调用 DataTable根据字段去重 .Net Core Cors中间件解析 分析MySQL中哪些情况下数据库索引会失效
数据库表设计时一对一关系存在的必要性 2017年07月24日 10:01:07 阅读数:694 在表设计过程中,我无意中觉得一对一关系觉得好没道理,直接放到一张表中不就可以了吗?真是说,网上信息什么都 ...
- 如何找出你性能最差的SQL Server查询
我经常会被反复问到这样的问题:”我有一个性能很差的SQL Server.我如何找出最差性能的查询?“.因此在今天的文章里会给你一些让你很容易找到问题答案的信息向导. 问SQL Server! SQL ...
随机推荐
- python基础教程(十一)
迭代器 本节进行迭代器的讨论.只讨论一个特殊方法---- __iter__ ,这个方法是迭代器规则的基础. 迭代器规则 迭代的意思是重复做一些事很多次---就像在循环中做的那样.__iter__ 方 ...
- chrome开发工具指南(十一)
检查资源 使用 Application 面板的 Frames 窗格可以按框架组织资源. 您也可以在 Sources 面板中停用 Group by folder 选项,按框架查看资源. 要按网域和文件夹 ...
- POJ 1236 tarjan
Network of Schools Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 19613 Accepted: 77 ...
- Linux Centos 6.9中SSH默认端口修改的坑
关于Linux Centos6.5的SSH默认端口修改的博客有一大堆,我在这里就不啰嗦了,但是面对Centos 6.9,就会发现有一个巨坑: 修改iptables之后执行下面的命令后: # servi ...
- CCIE-交换路由复习笔记
交换 考点: 1.trunk link(基础) 2.vtp 3.vlan 4.stp rstp mstp 5.hsrp vrrp glbp 6.ec Trunk link: 修改封装模式 802.1q ...
- CCNA+NP学习笔记—交换网络篇
本章关于企业网络的最底层--交换层,难度较低,主要为以后三层的路由做铺垫.所有笔记的分类顺序为:序章→交换层→路由层→运营商,体现了从企业网到互联网的学习顺序. 注:思科设备命令行通常不分大小写!以后 ...
- Java课程设计——博客作业教学数据分析系统(201521123082 黄华林)
Java课程设计--博客作业教学数据分析系统(201521123082 黄华林) 一.团队课程设计博客链接 博客作业教学数据分析系统(From:网络五条狗) 二.个人负责模块或任务说明 1.网络爬虫 ...
- 201521123075 《Java程序设计》第8周学习总结
1. 本周学习总结 2. 书面作业 本次作业题集集合 1.List中指定元素的删除(题目4-1) 1.1 实验总结 进行删除操作的时候最好从末尾开始删除.如果从开头开始删除,会使每个元素的对应位置发生 ...
- 201521123032 《Java程序设计》第1周学习总结
#1. 本周学习总结 下载熟悉eclipse,了解java的入门.用notepad++和eclipse编写Java程序.复习到了十进制转化为二进制,八进制与十六进制. #2. 书面作业 ##2.1为什 ...
- 多线程面试题系列(14):读者写者问题继 读写锁SRWLock
在第十一篇文章中我们使用事件和一个记录读者个数的变量来解决读者写者问题.问题虽然得到了解决,但代码有点复杂.本篇将介绍一种新方法--读写锁SRWLock来解决这一问题.读写锁在对资源进行保护的同时,还 ...