hadoop的安装和配置(二)伪分布模式
博主会用三篇文章为大家详细的说明hadoop的三种模式:
伪分布模式
伪分布式模式:
这篇为大家带来hadoop的伪分布模式:
从最简单的方面来说,伪分布模式就是在本地模式上修改配置文件:
core-site.xml;hdfs-site.xml;mapred-site.xml;yarn-site.xml4
备注:本地模式见hadoop的安装与配置——第一章:本地模式
思路简介
|——————————|
| ①:ssh免密登陆 |
| ②:修改配置文件 |
| ③:格式化hadoop |
| ④:启动hadoop |
|——————————|
一:ssh的免密登陆
生成id_rsa和id_rsa.pub
[root@localhost hadoop]# ssh-keygen -t rsa
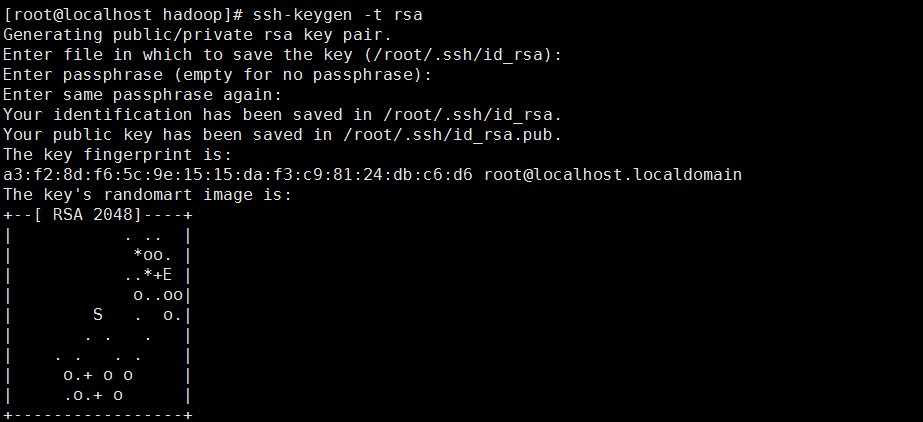
进入/root/.ssh下:将id_rsa.pub的信息发在authorized_keys下:
[root@localhost hadoop]# cd /root/.ssh/
[root@localhost .ssh]# cat id_rsa.pub >> authorized_keys
[root@localhost .ssh]# ls
authorized_keys id_rsa id_rsa.pub known_hosts

二:关于配置文件的主要内容
core-site.xml:指定hadoop的主节点master
hdfs-site.xml:指定hadoop中的文件副本数
mapred-site.xml:指定mapreduce的资源管理
yarn-site.xml:——————————————
配置文件可以从hadoop的官方文档中下载,有详细解释,这里为了减少对大家的干扰,就直接选取了部分:
[root@localhost hadoop]# cd /usr/local/hadoop/etc/hadoop/
[root@localhost hadoop]# pwd
/usr/local/hadoop/etc/hadoop
[root@localhost hadoop]# ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml
core-site.xml httpfs-site.xml mapred-site.xml.template
hadoop-env.cmd kms-acls.xml slaves
hadoop-env.sh kms-env.sh ssl-client.xml.example
hadoop-metrics2.properties kms-log4j.properties ssl-server.xml.example
hadoop-metrics.properties kms-site.xml yarn-env.cmd
hadoop-policy.xml log4j.properties yarn-env.sh
hdfs-site.xml mapred-env.cmd yarn-site.xml
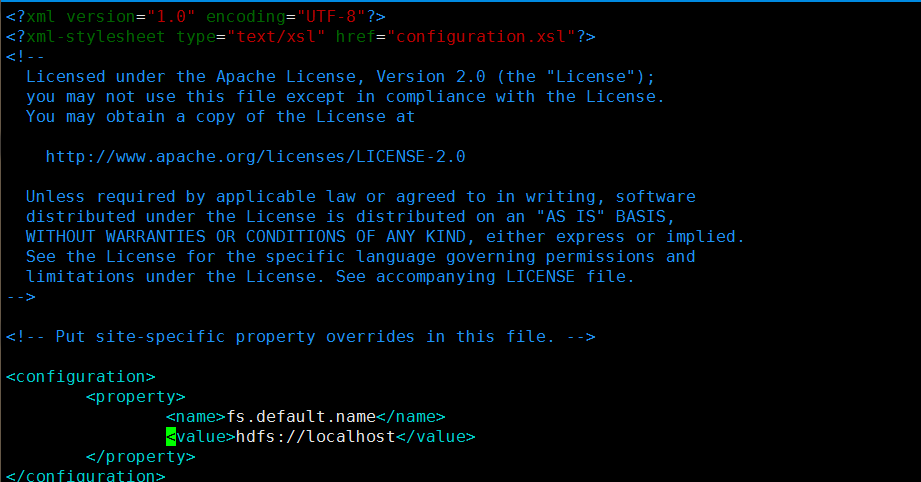
core-site.xml配置修改:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost</value>(主节点为本机localhost)
</property>
</configuration>
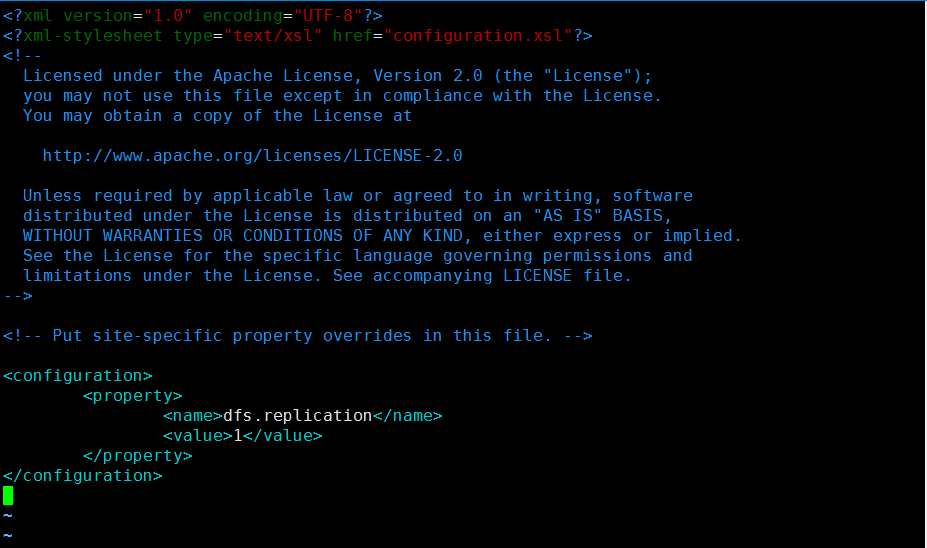
hdfs-site.xml配置修改:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>(伪分布模式)
</property>
</configuration>
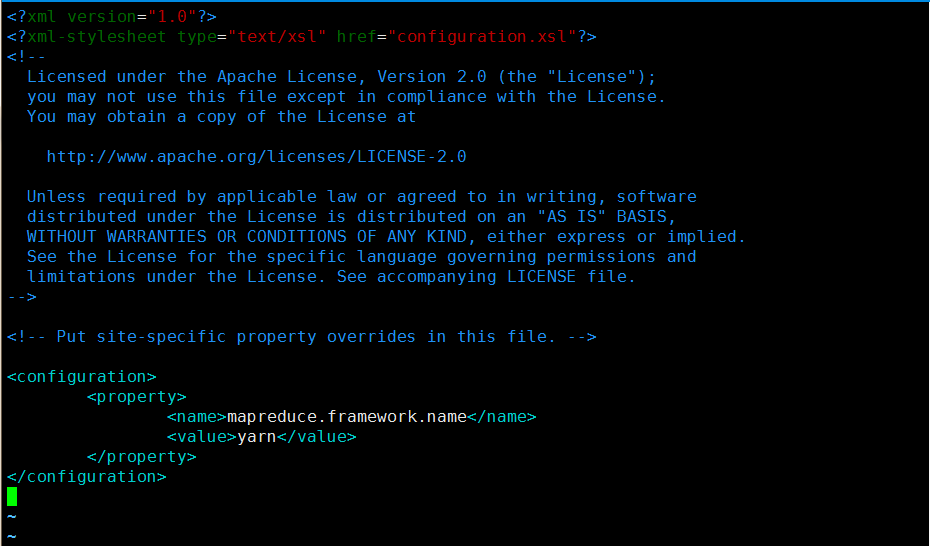
mapred-site.xml配置修改:
备注:
若没有mapred-site.xml,选择以下方法复制
[root@localhost hadoop]# cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>(选择yarn来mapreduce)
</property>
</configuration>
yarn-site.xml配置修改:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
三:格式化hadoop
hadoop namenode -format
格式化一次就好了
四:启动hadoop
start-all.sh
备注:关闭hadoop:stop-all.sh
想要知道hadoop是否配置成功,那么就使用jps来查询一下进程吧!
我们知道hadoop主要分为存储和计算,所以我们主要查询一下存储和计算的进程是否启动:
[root@localhost hadoop]# jps
31105 NodeManager(从)(计算)
30675 SecondaryNameNode(主-副本)(计算)
31139 Jps
30822 ResourceManager(主)(计算)
30510 DataNode(从)(存储)
30382 NameNode(主)(存储)

有不清楚的地方欢迎大家提问,有问题欢迎大家给出方法!
2017-12-26 15:32:06
本文版权声明:
本文作者:魁·帝小仙
博文主页地址:http://www.cnblogs.com/dxxblog/
欢迎对小博主的博客内容批评指点,如果问题,可评论或邮件联系(2335228250@qq.com)
欢迎转载,转载请在文章页面明显位置给出原文链接,谢谢
hadoop的安装和配置(二)伪分布模式的更多相关文章
- Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境)
一.准备 1.1创建hadoop用户 $ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell $ sudo pass ...
- Ubuntu下伪分布式模式Hadoop的安装及配置
1.Hadoop运行模式Hadoop有三种运行模式,分别如下:单机(非分布式)模式伪分布式(用不同进程模仿分布式运行中的各类节点)模式完全分布式模式注:前两种可以在单机运行,最后一种用于真实的集群环境 ...
- hadoop的安装和配置(三)完全分布式模式
博主会用三篇文章为大家详细说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 完全分布式模式: 前面已经说了本地模式和伪分布模式,这两种在hadoop的应用中并不用于实际,因为几乎没人会 ...
- Linux中Hadoop的安装与配置
一.准备 1,配通网络 ping www.baidu.com 之前安装虚拟机时配过 2,关闭防火墙 systemctl stop firewalld systemctl disable firewal ...
- ubuntu在虚拟机下的安装 ~~~ Hadoop的安装及配置 ~~~ Hdfs中eclipse的安装
前言 Hadoop是基于Java语言开发的,具有很好跨平台的特性.Hadoop的所要求系统环境适用于Windows,Linux,Mac系统,我们推荐选择使用Linux或Mac系统.而Linux系统则 ...
- Hadoop(2)-CentOS下的jdk和hadoop的安装与配置
准备工作 下载jdk8和hadoop2.7.2 使用sftp的方式传到hadoop100上的/opt/software目录中 配置环境 如果安装虚拟机时选择了open java,请先卸载 rpm -q ...
- Hadoop的安装与配置(虚拟机中的伪分布模式)
1引言 hadoop如今已经成为大数据处理中不可缺少的关键技术,在如今大数据爆炸的时代,hadoop给我们处理海量数据提供了强有力的技术支撑.因此,了解hadoop的原理与应用方法是必要的技术知识. ...
- 网站用户行为分析——Hadoop的安装与配置(单机和伪分布式)
Hadoop安装方式 Hadoop的安装方式有三种,分别是单机模式,伪分布式模式,伪分布式模式,分布式模式. 单机模式:Hadoop默认模式为非分布式模式(本地模式),无需进行其他配置即可运行.非分布 ...
- hadoop的安装和配置(一)本地模式
博主会用三篇文章来为大家详细的说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 本地模式: 思路走向 |--------------------| | ①:配置Java环境 | | ...
随机推荐
- 使用AOP记录应用调用链开销
最近系统出现了一次线上的性能问题,本来以为目前的QPS应该是不会出现任何问题的,结果微服务还是比较容易因为某个点的问题导致雪崩的...出了性能问题就要做分析,正统的思路是要不断进行压测用JProfil ...
- 家居环境监測系统设计(PC上位机版)(手机APP版待定)
下面是我的毕业设计:家居环境监測系统设计(PC上位机临时版.手机app版待定).本系统採用STC12C5A60S2单片机.结合传感器.分别对空气湿度.空气温度.气压.海拔.进水温度.出水温度.光照强度 ...
- 几条jQuery代码片段助力Web开发效率提升
平滑滚动至页面顶部 以下是jQuery最为常见的一种实现效果:点击一条链接以平滑滚动至页面顶部.虽然没什么新鲜感可言,但每位开发者几乎都用得上. $("a[href='#top']" ...
- Python笔记·第七章—— IO(文件)处理
一.文件处理简介 计算机系统分为:计算机硬件,操作系统,应用程序三部分. 我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知 ...
- Winform开发框架中工作流模块的业务表单开发
在我们开发工作流的时候,往往需要设计到具体业务表单信息的编辑,有些是采用动态编辑的,有些则是在开发过程中处理的,各有各的优点,动态编辑的则方便维护各种各样的表单,但是数据的绑定及处理则比较麻烦,而自定 ...
- Hadoop2.4.1伪分布式安装
本教程的前提是已经在VMware虚拟机上安装了centos6.5,centos的安装过程这里不再赘述 一.准备Linux环境 1.点击VMware快捷方式,右键打开文件所在位置 -> 双击vmn ...
- springboot命令启动
gradle打jar包命令 jar { doFirst { def jarFiles = ''; configurations.compile.collect { jarFiles += it.nam ...
- springboot 入门四-时间类型处理
springboot 自带了jackson来处理时间,但不支持jdk8 LocalDate.LocalDateTime的转换. 对于Calendar.Date二种日期,转换方式有二种: 一.统一app ...
- cell的复用机制
以下全部都是转载自别人的博客:http://blog.sina.com.cn/s/blog_9c3c519b01016aqu.html 转自:http://www.2cto.com/kf/201207 ...
- ES6常用语法
ECMAScript 6(以下简称ES6)是JavaScript语言的下一代标准.因为当前版本的ES6是在2015年发布的,所以又称ECMAScript 2015. 也就是说,ES6就是ES2015. ...