【基本知识】Flume基本环境搭建以及原理
系统:CentOS6.5
JDK:1.8.0_144
Flume:flume-ng-1.6.0-cdh5.12.0
一、什么是Flume
flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
flume的特点:
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
flume的可靠性 :
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Besteffort(数据发送到接收方后,不会进行确认)。
flume的可恢复性:
还是靠Channel。推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
二、Flume工作原理
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。以下是Flume的一些核心概念:
(1)Events:一个数据单元,带有一个可选的消息头,可以是日志记录、avro 对象等。
(2)Agent:JVM中一个独立的Flume进程,每台机器运行一个Agent,但一个Agent可以包含多个Source、Channel、Sink组件。
(3)Client:运行于一个独立线程,用于生产数据并将其发送给Agent。
(4)Source:用来消费传递到该组件的Event,从Client收集数据,传递给Channel。
(5)Channel:中转Event的一个临时存储,保存Source组件传递过来的Event,其实就是连接 Source 和 Sink ,有点像一个消息队列。
(6)Sink:从Channel收集数据,运行在一个独立线程。
Flume以Agent为最小的独立运行单位,一个Agent就是一个JVM。单Agent由Source、Sink和Channel三大组件构成,如下图所示:

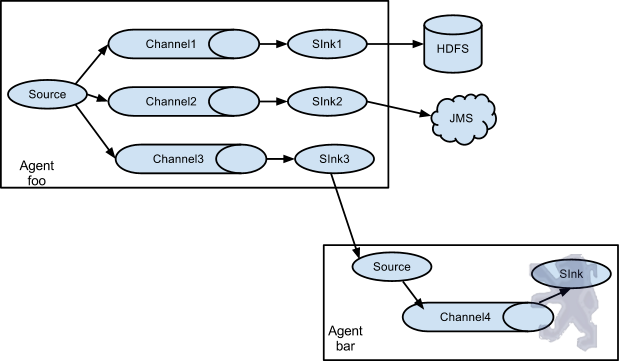
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source、Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上;Sink可以把日志写入HDFS、HBase、ES甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说多个Agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes,这也正是NB之处。如图所示:
图1

图2
三、下载安装
1.需要JDK1.6+
2.下载版本分为CDH和Apache版本,如果是个人机器集群安装,建议使用CDH版本,CDH的各组件的版本号要对应
CDH5各组件下载地址:http://archive.cloudera.com/cdh5/cdh/5/
3.将下载的包解压出来之后就已经完成了50%,剩下的内容就需要修改一些配置文件
4.设置环境变量
vim ~/.bash_profile
FLUME_HOME="/opt/module/flume" export PATH=$PATH:$FLUME_HOME/bin
source ~/.bash_profile
验证
/opt/module/flume/bin/flume-ng version

四、修改配置文件
# 指定Agent的组件名称 sunny.sources = so1 sunny.channels = ch1 sunny.sinks = si1 # 指定Flume source要监听的路径(logs/flume目录要提前建立好) sunny.sources.so1.type = spooldir sunny.sources.so1.spoolDir = /usr/sunny/logs/flume # 指定Flume sink sunny.sinks.si1.type = logger # 绑定source和sink到channel上 sunny.sinks.si1.channel = ch1 sunny.sources.so1.channels = ch1 # 指定Flume channel sunny.channels.ch1.type = memory sunny.channels.ch1.capacity = 1000 sunny.channels.ch1.transactionCapacity = 100
五、启动
cd /opt/module/flume/ bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name sunny -Dflume.root.logger=INFO,console
| 参数 | 作用 | 举例 |
|---|---|---|
| –conf 或 -c | 指定配置文件夹,包含flume-env.sh和log4j的配置文件 | –conf conf |
| –conf-file 或 -f | 配置文件地址 | –conf-file conf/flume.conf |
| –name 或 -n | agent名称 | –name a1 |
| -z | zookeeper连接字符串 | -z zkhost:2181,zkhost1:2181 |
| -p | zookeeper中的存储路径前缀 | -p /flume |
然后另开一个客户端,新增一个日志文件,编辑内容
cd /usr/sunny/logs/flume vim test.log
在开启的客户端就可以看到内容

六、其他source
1.Avro
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel that buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
// 运行FlumeAgent,监听本机的44444端口 $ flume-ng agent -c conf -f example/netcat.conf -n a1 -Dflume.root.logger=INFO,console
// 打开另一终端,通过telnet登录localhost的44444,输入测试数据 $ telnet localhost 44444
2.Spool
Spool用于监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点:拷贝到spool目录下的文件不可以再打开编辑、spool目录下不可包含相应的子目录。具体示例如下:
// 创建两个Flume配置文件 $ cd app/cdh/flume-1.6.0-cdh5.7.1 $ cp conf/flume-conf.properties.template example/spool1.conf $ cp conf/flume-conf.properties.template example/spool2.conf
// 配置spool1.conf用于监控目录avro_data的文件,将文件内容发送到本地60000端口 $ vim example/spool1.conf # Namethe components local1.sources= r1 local1.sinks= k1 local1.channels= c1 # Source local1.sources.r1.type= spooldir local1.sources.r1.spoolDir= /home/hadoop/avro_data # Sink local1.sinks.k1.type= avro local1.sinks.k1.hostname= localhost local1.sinks.k1.port= 60000 #Channel local1.channels.c1.type= memory # Bindthe source and sink to the channel local1.sources.r1.channels= c1 local1.sinks.k1.channel= c1
// 配置spool2.conf用于从本地60000端口获取数据并写入HDFS # Namethe components a1.sources= r1 a1.sinks= k1 a1.channels= c1 # Source a1.sources.r1.type= avro a1.sources.r1.channels= c1 a1.sources.r1.bind= localhost a1.sources.r1.port= 60000 # Sink a1.sinks.k1.type= hdfs a1.sinks.k1.hdfs.path= hdfs://localhost:9000/user/wcbdd/flumeData a1.sinks.k1.rollInterval= 0 a1.sinks.k1.hdfs.writeFormat= Text a1.sinks.k1.hdfs.fileType= DataStream # Channel a1.channels.c1.type= memory a1.channels.c1.capacity= 10000 # Bind the source and sink to the channel a1.sources.r1.channels= c1 a1.sinks.k1.channel= c1
// 分别打开两个终端,运行如下命令启动两个Flume Agent $ flume-ng agent -c conf -f example/spool2.conf -n a1 $ flume-ng agent -c conf -f example/spool1.conf -n local1
// 查看本地文件系统中需要监控的avro_data目录内容 $ cd avro_data $ cat avro_data.txt
Flume内置了大量的Source,其中Avro Source、Thrift Source、Spooling Directory Source、Kafka Source具有较好的性能和较广泛的使用场景。下面是Source的一些参考资料:

(1)*******

(2)*******

(3)*******

(4)*******

(5)*******

(6)*******

(7)*******

(8)*******

七、Flume所支持的Sources、Channels、Sinks
| Sources | Channels | Sinks |
|---|---|---|
|
|
|
【基本知识】Flume基本环境搭建以及原理的更多相关文章
- HTML5 移动应用开发环境搭建及原理分析
开发环境搭建: 一.Android 开发平台搭建 安装java jdk:\\10.194.151.132\Mewfile\tmp\ADT 配置java jdk 1) 新建系统变量,JAVA_HOME ...
- 3.移动端自动化测试-appium环境搭建(原理)
appium自动化原理: 需要服务端(appium启动),手机端(adb连接设备),脚本端(pycharm)就可以进行 自己总结下: 手机和脚本连接:1.adb连接,2靠脚本导入驱动. 脚本和服务端连 ...
- 04.flume+kafka环境搭建
1.flume下载 安装 测试 1.1 官网下载,通过xshell从winser2012传到cent0s的/opt/flume目录中,使用rz命令 1.2 解压安装 tar -zxvf apache- ...
- iOS自动化环境搭建——macaca
macaca-java for ios 自动化环境搭建 基础原理解析:https://testerhome.com/topics/6608 一.环境搭建 1.安装eclipse; -----Java开 ...
- Docker学习之——Node.js+MongoDB+Nginx环境搭建(一)
最近在学习Node.js相关知识,在环境搭建上耗费了不少功夫,故此把这个过程写下来同大家分享一下,今天我先来介绍一下Docker,有很多人都写过相关知识,还有一些教程,在此我只想写一下,我的学习过程中 ...
- springmvc工作原理和环境搭建
SpringMVC工作原理 上面的是springMVC的工作原理图: 1.客户端发出一个http请求给web服务器,web服务器对http请求进行解析,如果匹配DispatcherServle ...
- Android编程: 环境搭建、基本知识
学习的内容两个方面:环境搭建.基本知识 ====环境搭建==== 1.下载 android studio(http://developer.android.com/sdk/index.html) 2. ...
- 基于Selenium2+Java的UI自动化(1) - 原理和环境搭建
一.Selenium2的原理 Selenium1是thoughtworks公司的一个产品经理,为了解决重复烦躁的验收工作,写的一个自动化测试工具,其原理是用JS注入的方 式来模拟人工的操作,但是由于J ...
- Flume环境搭建_五种案例
Flume环境搭建_五种案例 http://flume.apache.org/FlumeUserGuide.html A simple example Here, we give an example ...
随机推荐
- linux文件目录管理命令
1.touch命令 touch命令用于创建空白文件或设置文件的时间,格式为“touch [选项] [文件]”. touch test命令可以创建出一个名为test的空白文本文件 touch命令的参数 ...
- 谈谈html中一些比较"偏门"的知识(map&area;iframe;label)
说明:这里所说的"偏门"只是相对于本人而言,记录在此,加深印象.也希望有需要的朋友能获得些许收获! 1.空元素(void):没有内容的元素. 常见的有:<br>,< ...
- yii2 rules验证规则,ajax验证手机号码是否唯一
<?php namespace frontend\models; use Yii; use yii\base\Model; /** * Signup form */ class SignupFo ...
- Python 7 -- 文件存储数据
上一节总结了一个基本web应用的代码,这一节主要讲用户访问的数据记录在log文件中,并显示在页面上. 这节步骤: 按以下目录建好相应的文件夹及内容 webapp|----vsearch4web.py ...
- tensorflow学习5----变量管理
---恢复内容开始--- 前面,读书笔记用加入正则化损失模型效果带来的提升要相对显著. 变量管理: 目的:当神经网络的结构更加复杂,参数更多的时候,就需要一个更好的方式来管理神经网络中的参数. 解决方 ...
- golang学习笔记13 Golang 类型转换整理 go语言string、int、int64、float64、complex 互相转换
golang学习笔记13 Golang 类型转换整理 go语言string.int.int64.float64.complex 互相转换 #string到intint,err:=strconv.Ato ...
- linux yum配置本地iso镜像
1.本地源配置:cdiso.repo 将iso镜像文件中所有内容复制到/public/software/cdrom 中,节点将本地yum指向此处. [root@node19 ~]# vim /etc/ ...
- Hybrid App中原生页面 VS H5页面(分享)
本文部分转自 http://www.jianshu.com/p/00ff5664e000 现有3类主流APP,分别为:Web App.Hybrid App(混合模式移动应用,Hybrid有“混合的” ...
- BATJ等大厂最全经典面试题分享
金九银十,又到了面试求职高峰期,最近有很多网友都在求大厂面试题.正好我之前电脑里面有这方面的整理,于是就发上来分享给大家. 这些题目是网友去百度.蚂蚁金服.小米.乐视.美团.58.猎豹.360.新浪. ...
- sql server还原注意事项
使用Sql Server 2000的数据库备份文件还原Sql Server 2000的数据库和还原Sql Server 2005的数据库区别:1.在还原至Sql 2000时是必须新建数据库并对其还原, ...