Python 数据结构--排序
各种排序的时间复杂度和空间复杂度
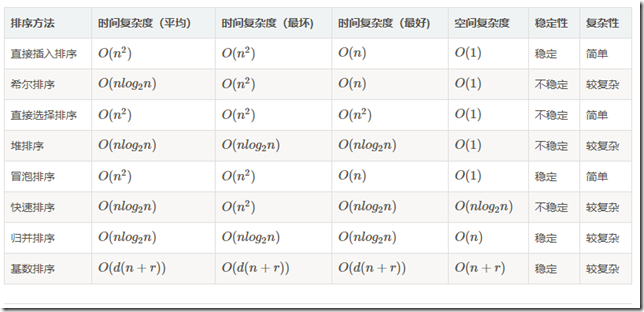
以下
冒泡排序,选择排序,插入排序,合并排序,快速排序,希尔排序
1 冒泡排序(Bubble Sort)
冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。冒泡排序对n个项目需要O(n^2)的比较次数,且可以原地排序。尽管这个算法是最简单了解和实现的排序算法之一,但它对于包含大量的元素的数列排序是很没有效率的。
python支持对两个数字同时交换, a, b = b, a。就可以直接交换a和b的值了。

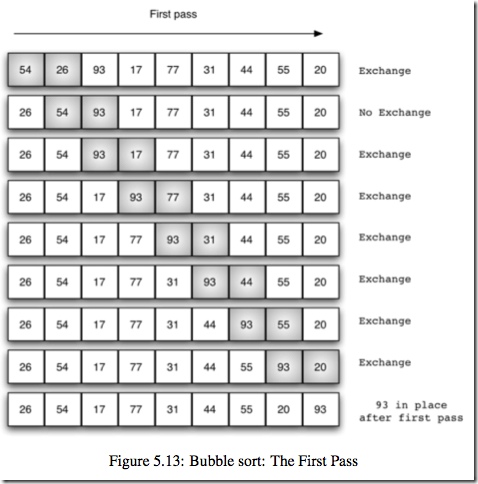
def bubble_sort(a_list):
exchange = True
pass_num = len(a_list)-1
while pass_num > 0 and exchange:
exchange = False
for i in range(pass_num):
if a_list[i] > a_list[i+1]:
exchange = True
a_list[i], a_list[i+1] = a_list[i+1], a_list[i]
pass_num = pass_num-1
if __name__ == '__main__':
a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
bubble_sort(a_list)
print a_list
2 选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
选择排序的主要优点与数据移动有关。如果某个元素位于正确的最终位置上,则它不会被移动。选择排序每次交换一对元素,它们当中至少有一个将被移到其最终位置上,因此对n个元素的表进行排序总共进行至多n-1次交换。在所有的完全依靠交换去移动元素的排序方法中,选择排序属于非常好的一种。时间复杂度O(n^2)

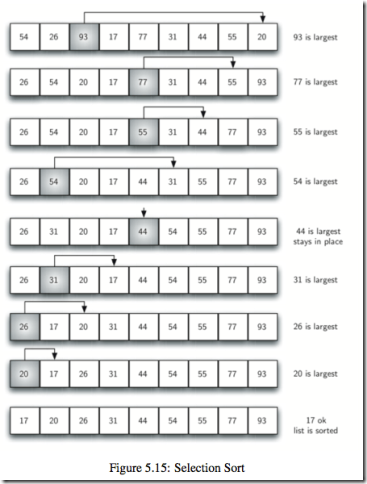
def selection_sort(a_list):
for full_slot in range(len(a_list)-1, 0, -1):
pos_max = 0
for location in range(1, full_slot+1):
if a_list[location] > a_list[pos_max]:
pos_max = location
a_list[full_slot], a_list[pos_max] = a_list[pos_max], a_list[full_slot] if __name__ == '__main__':
a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
selection_sort(a_list)
print a_list
3 插入排序
插入排序(Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
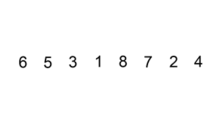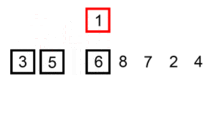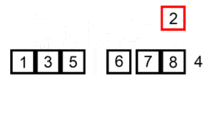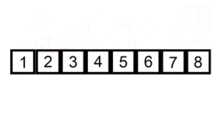


def insertion_sort(a_list):
for index in range(1, len(a_list)):
current = a_list[index]
position = index
while position > 0 and a_list[position-1] > current:
a_list[position] = a_list[position-1]
position = position -1
a_list[position] = current
a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
insertion_sort(a_list)
print a_list
4 合并排序
典型的是二路合并排序,将原始数据集分成两部分(不一定能够均分),分别对它们进行排序,然后将排序后的子数据集进行合并,这是典型的分治法策略。时间复杂度O(nlogn)
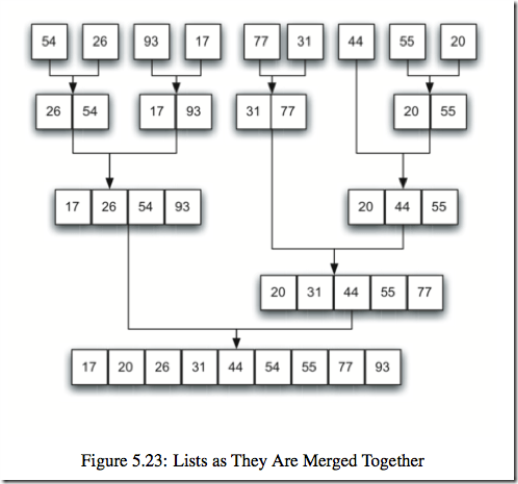
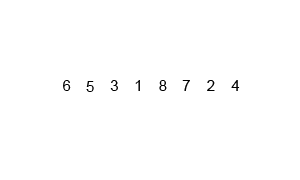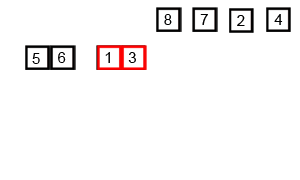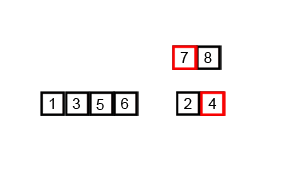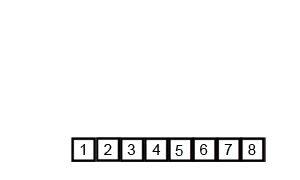
def merge_sort(a_list):
print "Splitting", a_list
if len(a_list) > 1:
mid = len(a_list) //2
left_half = a_list[:mid]
right_half = a_list[mid:]
merge_sort(left_half)
merge_sort(right_half)
i = 0
j = 0
k = 0
while i < len(left_half) and j < len(right_half):
if left_half[i] < right_half[j]:
a_list[k] = left_half[i]
i = i+1
else:
a_list[k] = right_half[j]
j = j+1
k = k+1
while i < len(left_half):
a_list[k] = left_half[i]
i = i+1
k = k+1
while j < len(right_half):
a_list[k] = right_half[j]
j = j+1
k = k+1
print "Merging", a_list a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20]
merge_sort(a_list)
print a_list
5 快速排序
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
def quick_sort(a_list):
quick_sort_helper(a_list, 0, len(a_list)-1) def quick_sort_helper(a_list, first, last):
if first < last:
split_point = partition(a_list, first, last)
quick_sort_helper(a_list, first, split_point - 1)
quick_sort_helper(a_list, split_point + 1, last) def partition(a_list, first, last):
pivot_value = a_list[first]
left_mark = first +1
right_mark = last
done = False
while not done:
while left_mark <= right_mark and a_list[left_mark] <= pivot_value:
left_mark = left_mark +1
while a_list[right_mark] >= pivot_value and right_mark >= left_mark:
right_mark = right_mark-1
if right_mark < left_mark:
done = True
else:
temp = a_list[left_mark]
a_list[left_mark] = a_list[right_mark]
a_list[right_mark] = temp
temp = a_list[first]
a_list[first] =a_list[right_mark]
a_list[right_mark] =temp
return right_mark a_list = [54, 26, 93, 17, 77, 31, 44, 50, 20]
quick_sort(a_list)
print a_list
6 希尔排序
类似合并排序和插入排序的结合体,二路合并排序将原来的数组分成左右两部分,希尔排序则将数组按照一定的间隔分成几部分,每部分采用插入排序来排序,有意思的是这样做了之后,元素很多情况下就差不多在它应该呆的位置,所以效率不一定比插入排序差。
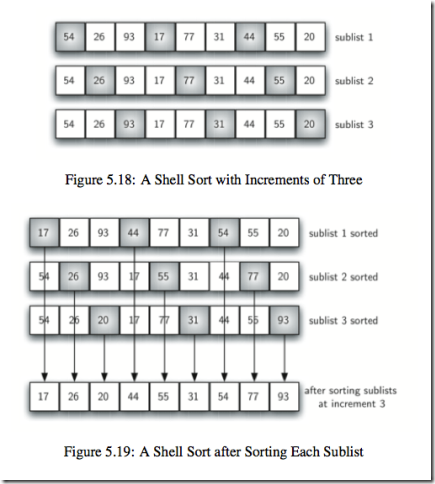
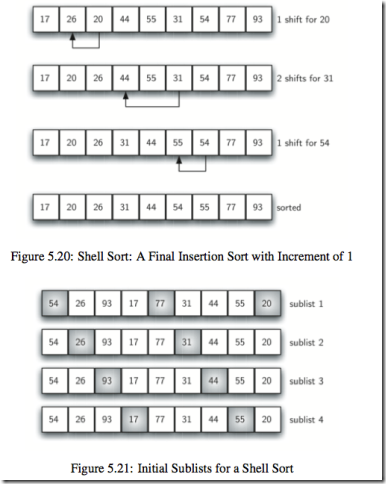
def shell_sort(a_list):
#how many sublists, also how many elements in a sublist
sublist_count = len(a_list) // 2
while sublist_count > 0:
for start_position in range(sublist_count):
gap_insertion_sort(a_list, start_position, sublist_count)
print("After increments of size", sublist_count, "The list is", a_list)
sublist_count = sublist_count // 2 def gap_insertion_sort(a_list, start, gap):
#start+gap is the second element in this sublist
for i in range(start + gap, len(a_list), gap):
current_value = a_list[i]
position = i
while position >= gap and a_list[position - gap] > current_value:
a_list[position] = a_list[position - gap] #move backward
position = position - gap
a_list[position] = current_value a_list = [54, 26, 93, 17, 77, 31, 44, 55, 20, 88]
shell_sort(a_list)
print(a_list)
Python 数据结构--排序的更多相关文章
- python数据结构与算法
最近忙着准备各种笔试的东西,主要看什么数据结构啊,算法啦,balahbalah啊,以前一直就没看过这些,就挑了本简单的<啊哈算法>入门,不过里面的数据结构和算法都是用C语言写的,而自己对p ...
- Python数据结构与算法--算法分析
在计算机科学中,算法分析(Analysis of algorithm)是分析执行一个给定算法需要消耗的计算资源数量(例如计算时间,存储器使用等)的过程.算法的效率或复杂度在理论上表示为一个函数.其定义 ...
- python拓扑排序
发现自己并没有真的理解拓扑排序和多重继承,再次学习了下 拓扑排序要满足如下两个条件 每个顶点出现且只出现一次. 若A在序列中排在B的前面,则在图中不存在从B到A的路径. 拓扑排序算法 任何无回路的顶点 ...
- python常见排序算法解析
python——常见排序算法解析 算法是程序员的灵魂. 下面的博文是我整理的感觉还不错的算法实现 原理的理解是最重要的,我会常回来看看,并坚持每天刷leetcode 本篇主要实现九(八)大排序算法 ...
- 第四百一十五节,python常用排序算法学习
第四百一十五节,python常用排序算法学习 常用排序 名称 复杂度 说明 备注 冒泡排序Bubble Sort O(N*N) 将待排序的元素看作是竖着排列的“气泡”,较小的元素比较轻,从而要往上浮 ...
- python数据结构之直接插入排序
python数据结构之直接插入排序 #-*-encoding:utf-8-*- ''' 直接插入排序: 从序列的第二个元素开始,依次与前一个元素比较,如果该元素比前一个元素大, 那么交换这两个元素.该 ...
- Python - 数据结构 - 第十五天
Python 数据结构 本章节我们主要结合前面所学的知识点来介绍Python数据结构. 列表 Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和 ...
- python 经典排序算法
python 经典排序算法 排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存.常见的内部排序算 ...
- 送你一个Python 数据排序的好方法
摘要:学习 Pandas排序方法是开始或练习使用 Python进行基本数据分析的好方法.最常见的数据分析是使用电子表格.SQL或pandas 完成的.使用 Pandas 的一大优点是它可以处理大量数据 ...
随机推荐
- windows远程以及文件共享方法总结
文件共享部分 紧接着下一步[允许使用空密码] 参考这个链接 https://jingyan.baidu.com/article/7f766dafa8c5ee4100e1d071.html 在我们使用w ...
- CCF-CSP 201312-5 I'm stuck !
I'm stuck 试题编号: 201312-5 试题名称: I’m stuck! 时间限制: 1.0s 内存限制: 256.0MB 问题描述: 问题描述 给定一个R行C列的地图,地图的每一个方格可能 ...
- java判断时间为上午,中午,下午,晚上,凌晨
public static void main(String[] args) { Date date = new Date(); SimpleDateFormat df = new SimpleDat ...
- jq回车触发绑定点击事件
//jq绑定回车事件触发点击事件<script> $(function(){ $(document).keyup(function(event){ if(event.keyCode ==1 ...
- rac 关库 启库
关库顺序 先关闭数据库 然后关闭节点资源 [root@rac1 ~]# srvctl stop database -d prod[root@rac1 ~]# srvctl stop inst ...
- [CodeForces - 447D] D - DZY Loves Modification
D - DZY Loves Modification As we know, DZY loves playing games. One day DZY decided to play with a n ...
- 将本地分支push到远程分支
git push origin [localbranch]:[remotebranch]
- [转]JVM内存模型
最近排查一个线上java服务常驻内存异常高的问题,大概现象是:java堆Xmx配置了8G,但运行一段时间后常驻内存RES从5G逐渐增长到13G #补图#,导致机器开始swap从而服务整体变慢.由于Xm ...
- Python之简单的用户登录和注册
# -*- coding: utf-8 -*- # @Time : 2018/7/26 20:16 # @Author : Adam # @File : exam2.py # @Project: ke ...
- ssh免输入密码登录
ssh免输入密码登录 ubuntu下生成ssh密钥参见. https://confluence.atlassian.com/display/BITBUCKET/Use+the+SSH+prot ...