pycharm下打开、执行并调试scrapy爬虫程序
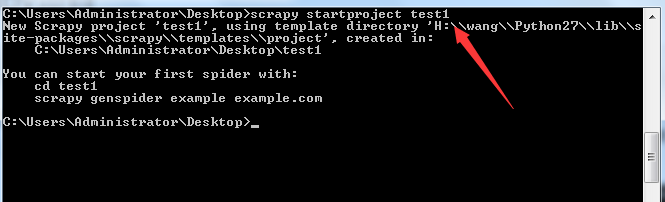
首先得有一个Scrapy项目,我在Desktop上新建一个Scrapy的项目叫test,在Desktop目录打开命令行,键入命令:
scrapy startproject test1
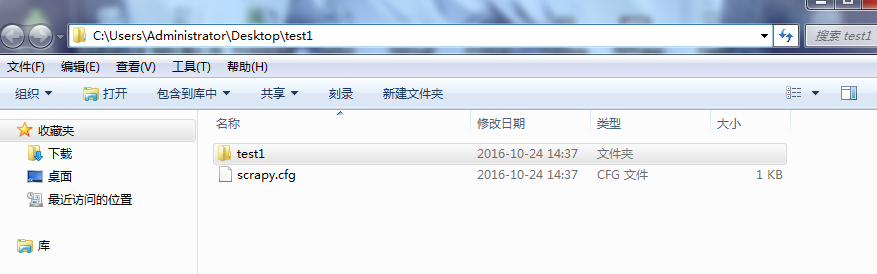
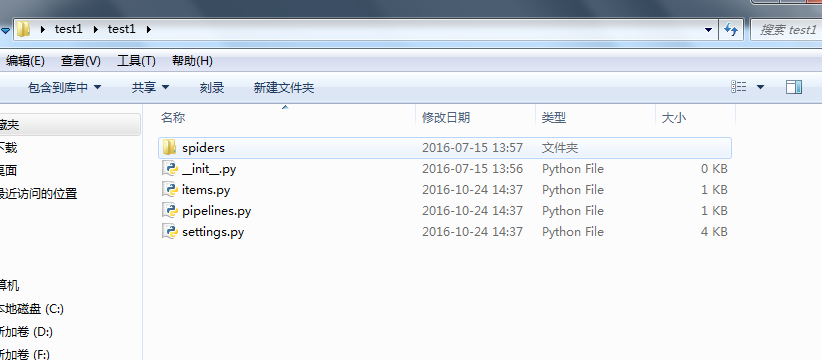
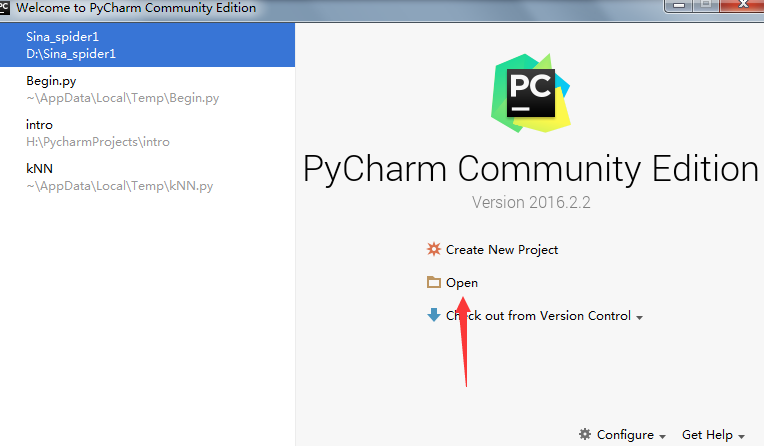
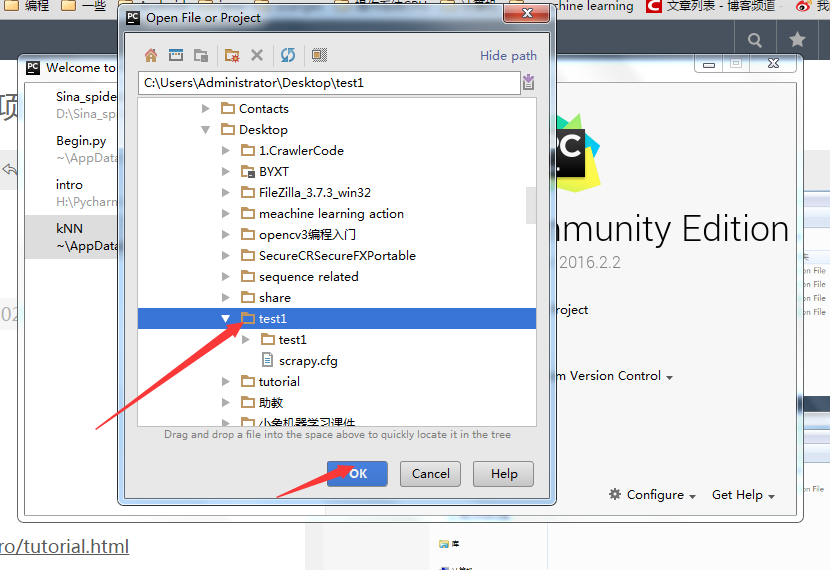
目录结构如下:打开Pycharm,选择open
选择项目,ok
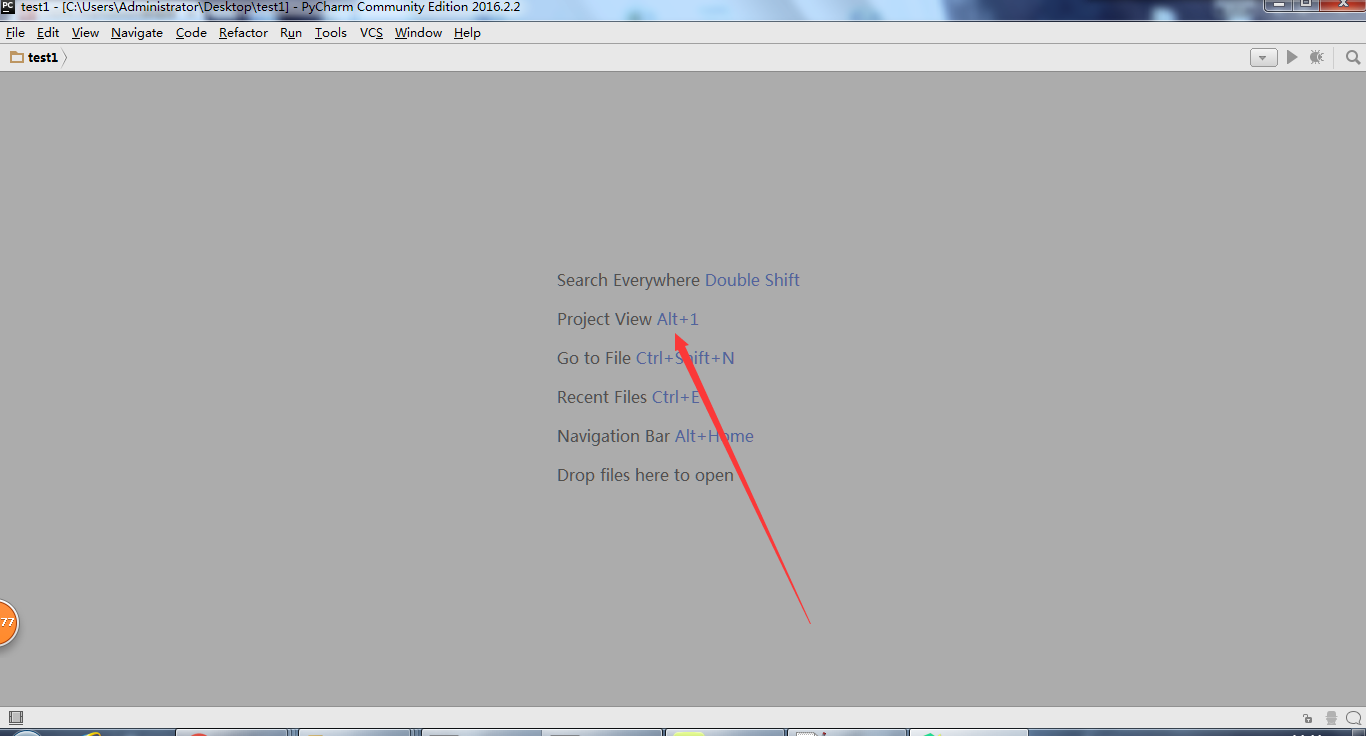
打开如下界面之后,按alt + 1, 打开project 面板
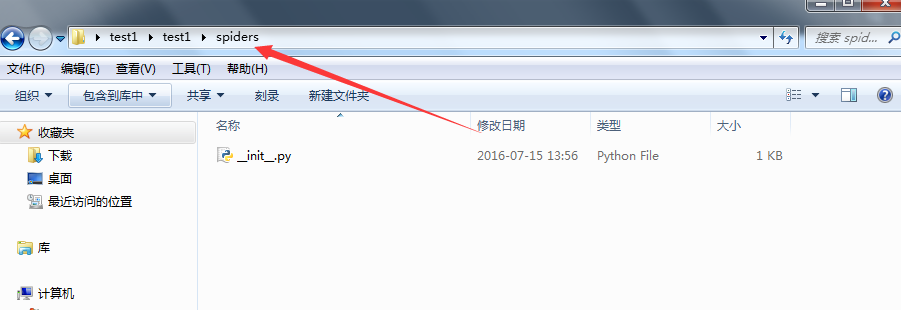
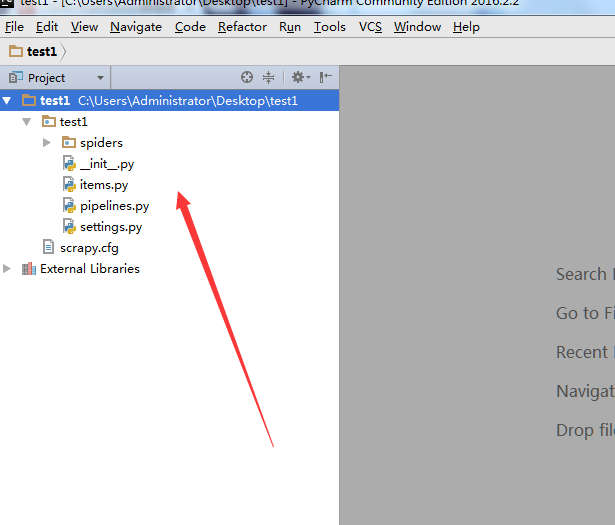
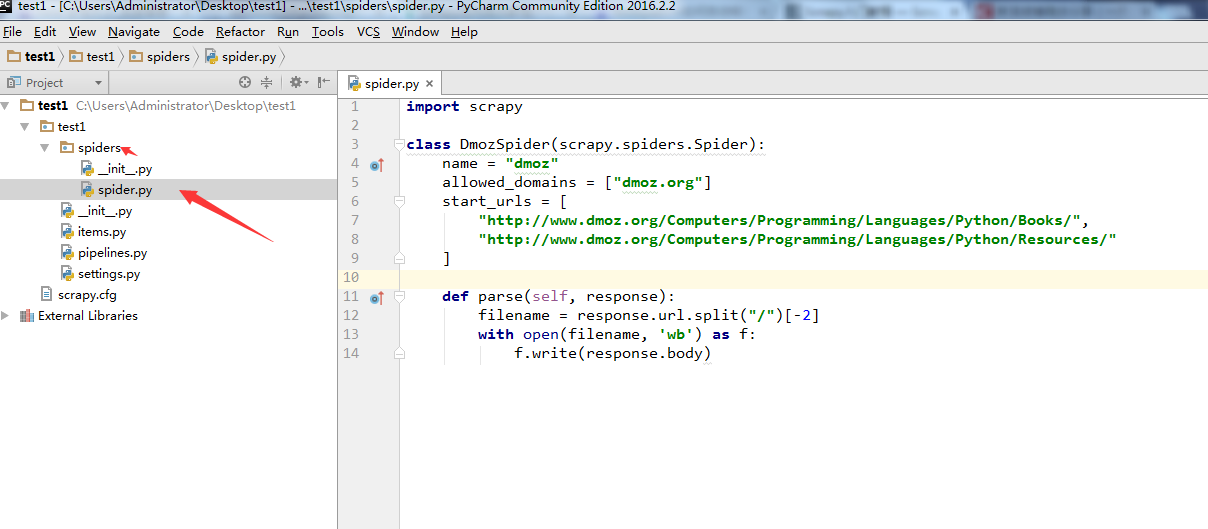
在test1/spiders/,文件夹下,新建一个爬虫spider.py, 注意代码中的
name="dmoz"。这个名字后面会用到。在test1目录和scrapy.cfg同级目录下面,新建一个begin.py文件(便于理解可以写成main.py),注意箭头2所指的名字和第5步中的
name='dmoz'名字是一样的。
from scrapy import cmdline
cmdline.execute("scrapy crawl dmoz".split())- 1
- 2
- 3
- 1
- 2
- 3
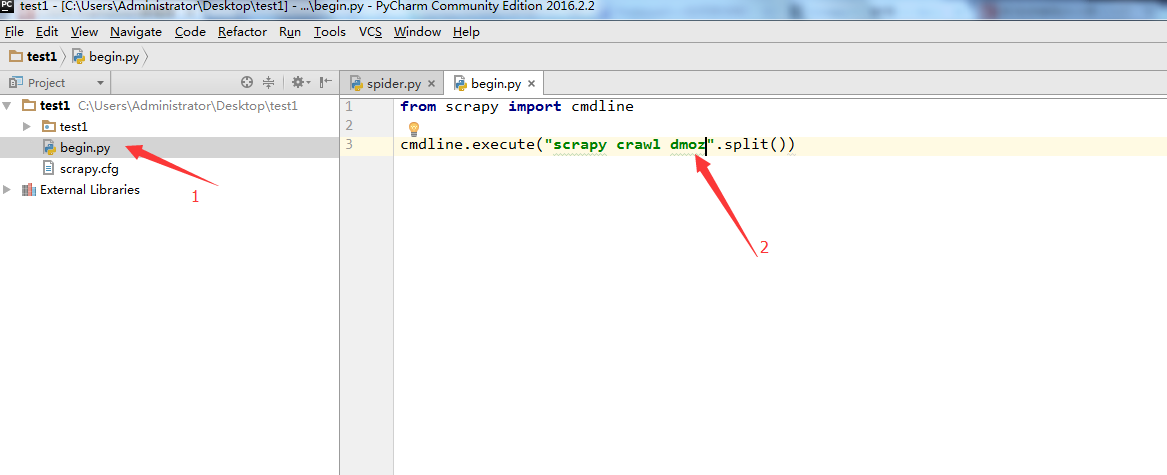
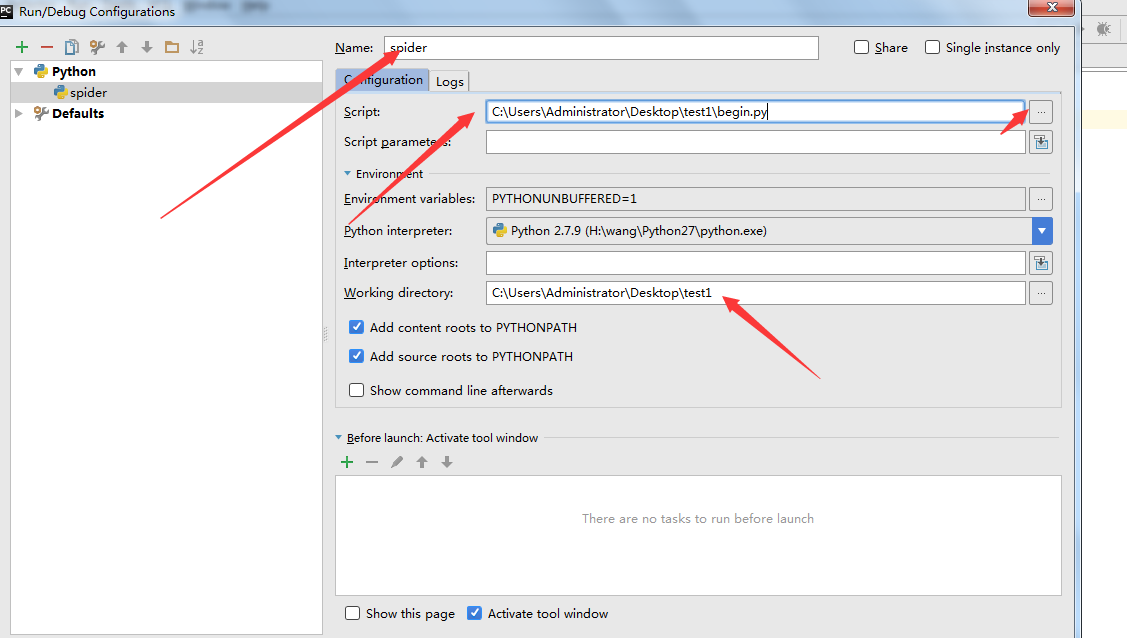
7. 上面把文件搞定了,下面要配置一下pycharm了。点击Run->Edit Configurations
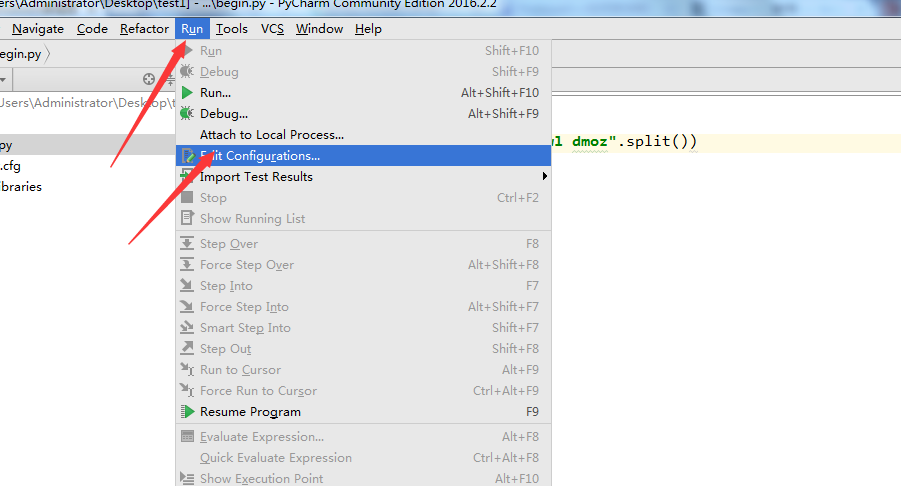
8. 新建一个运行的python模块
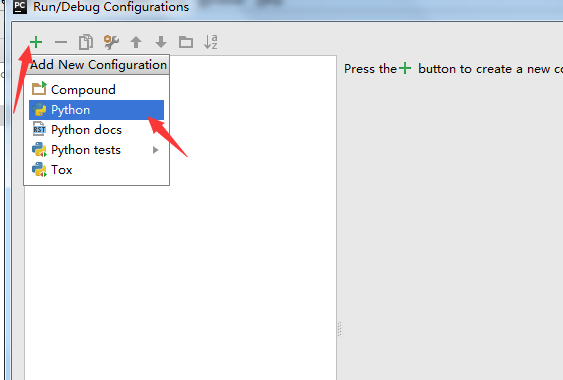
9. Name:改成spider; script:选择刚才新建的那个begin.py文件;Working Direciton:改成自己的工作目录
10. 至此,大功告成了,点击下图,右上角的按钮就能运行了。
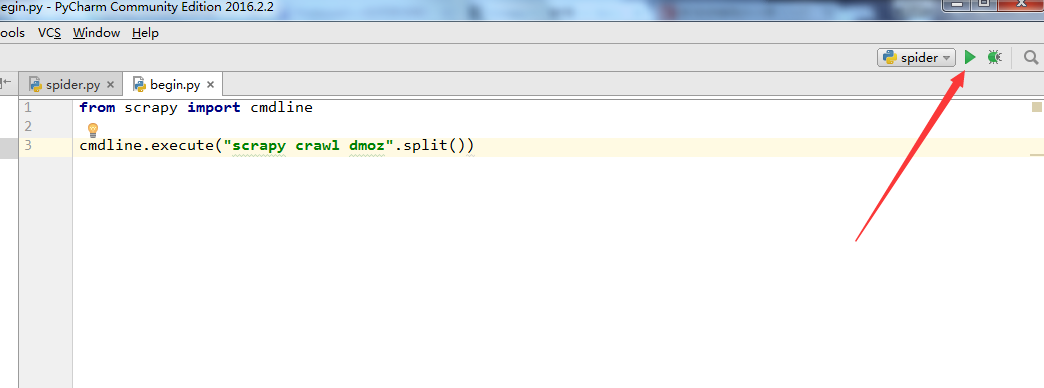
调试
可以在其他代码中设置断点,就可以debug运行


转载1:http://www.jianshu.com/p/f85120fcbca0
转载2:http://blog.csdn.net/wangsidadehao/article/details/52911746
pycharm下打开、执行并调试scrapy爬虫程序的更多相关文章
- liunx系统下crontab定时启动Scrapy爬虫程序
定时启动爬虫 # 查看命令得绝对路径 # which scrapy # cd到爬虫得项目目录下 + scrapy命令得绝对路径 + 启动命令 */5 * * * * cd /opt/mafengwo/ ...
- python2.7下同步华为云照片的爬虫程序实现
1.背景 随着华为手机的销量加大,华为云的捆绑服务使用量也越来越广泛,华为云支持自动同步照片.通讯录.记事本等,用着确实也挺方便的,云服务带来方便的同时,也带来了数据管理风险.华为目前只提供一个www ...
- scrapy爬虫程序xpath中文编码报错
2017-03-23 问题描述: #选择出节点中“时间”二字 <h2>时间</h2> item["file_urls"]= response.xpath(& ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- 关于Scrapy爬虫项目运行和调试的小技巧(上篇)
扫除运行Scrapy爬虫程序的bug之后,现在便可以开始进行编写爬虫逻辑了.在正式开始爬虫编写之前,在这里介绍四种小技巧,可以方便我们操纵和调试爬虫. 一.建立main.py文件,直接在Pycharm ...
- 关于Scrapy爬虫项目运行和调试的小技巧(下篇)
前几天给大家分享了关于Scrapy爬虫项目运行和调试的小技巧上篇,没来得及上车的小伙伴可以戳超链接看一下.今天小编继续沿着上篇的思路往下延伸,给大家分享更为实用的Scrapy项目调试技巧. 三.设置网 ...
- scrapy爬虫,cmd中执行日志中显示了爬取的内容,但是运行时隐藏日志后(运行命令后添加--nolog),就没有输出结果了
cmd下执行scrapy爬虫程序,不报错也没有输出,解决方案 想要执行parse能够在cmd看到parse函数的执行结果: 解决方法: settings.py 中设置 ROBOTSTXT_OBEY ...
- pycharm下运行和调试scrapy项目
1. 新建项目 默认在本地已经新建了一个scrapy爬虫项目 2. 打开项目 点击open à 选择刚刚那个本地的scrapy项目meijutt100 3. 项目结构 各个py文件的作用不作介绍,不懂 ...
- python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中 现在我们需要在SETTING.PY设置我们的爬虫文件 再添加PIPELINE 注释掉的原因是爬虫执行完后,和本地存 ...
随机推荐
- MPI 环境搭建问题-运行程序闪退
安装后smpd无法运行,进程中没有smpd.exe.注册过程也完成了.运行自带的测试程序cpi.exe,提示:Error: No smpd passphrase specified through t ...
- Android天坑ImageView控件上下留白原因与解决
ImageView控件上下留白 如下,误以为是padding的问题.搜索无果 后来发现是需要添加android:adjustViewBounds="true",调整ImageVie ...
- 2、Keepalived提供日志与双主模型演示
Keepalived实例演示: 利用keepalived流动一个VIP,在提供LVS的高可用以及实现对LVS后端的real server做健康状态检测,最后实现高可用nginx. HA Clust ...
- hdu 3829 Cat VS Dog 二分图匹配 最大点独立集
Cat VS Dog Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 125536/65536 K (Java/Others) Prob ...
- Missing artifact com.oracle:ojdbc6:jar:10.2.0.4.0问题解决 ojdbc包pom.xml出错
遇到的问题:ojdbc.jar包出错 原因:因为oracle的ojdbc.jar是收费的,所以maven的中央仓库中没有这个资源,只能通过配置本地库才能加载到项目中去. 解决办法: (前提是安装好了m ...
- cmd中mvn命令,出现No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK?
在cmd里执行mvn命令,出错 查看mvn -v 发现mvn运行在jre上,更改高级设置.我的电脑-->属性-->高级系统设置-->环境变量 更改完之后,再次查看 mvn -v 搞定 ...
- 学习笔记4-pathon的range()函数和list()函数
使用python的人都知道range()函数很方便,今天再用到他的时候发现了很多以前看到过但是忘记的细节.这里记录一下range(),复习下list的slide,最后分析一个好玩儿的冒泡程序. 这里记 ...
- new int
new int, 在申请内存,定义int变量:new int (100),在申请内存,定义int变量,并初始化为100:new int[100] , 在申请内存,定义int数组变量.
- MySQL processlist/kill
1.show full processlist 显示MySQL所有正在执行的进程,用于查看当前的MySQL运行情况,避免死锁等导致的异常情况. 主要的列: Id:进程Id User:登录账号 Host ...
- traceback模块——获取详细的异常信息
try: 1/0 except Exception,e: print e 输出结果是integer division or modulo by zero,只知道是报了这个错,但是却不知道在哪个文件哪个 ...