Trie-Tree
最近写了一些关于字典树的题目,这里做个简单的整理。
字典树,又叫单词查找树,顾名思义就是查单词的(不仅仅o),和词典一样。不同的是词典是用纸做的,而字典树是用树形结构构建的。
她用来快速检索你要的内容,对于统计和大量字符串的排序是很好用的。她的好处就是让你尽可能的减少那么过分多且没必要的比较,提供高效的检索。Trie的核心是空间换时间,没错,开销不少,这可能是个缺点吧。
首先,她的根结点仅仅是个根结点,什么都没有,可以看做是一本词典的封面,想要查询单词,先得打开封面(进入根结点)。
进入根结点后立马会看到a-z共26个结点,没错,这是给你选择的地方,根据你要查询的单词的首字母选择对应的结点(每个结点对应唯一一个字符),进入即可。
重复上述步骤,就可以得到你想要的结果(你要查询的字符串就是路径到叶子结点的总和)。
查找过程,你不会发现有重复的字母,也就是你不会在两条不同的路径上找到同一个字符串,每个节点的所有子节点包含的字符都不相同。这就是Trie的三个特性。
她的存放就如这样:
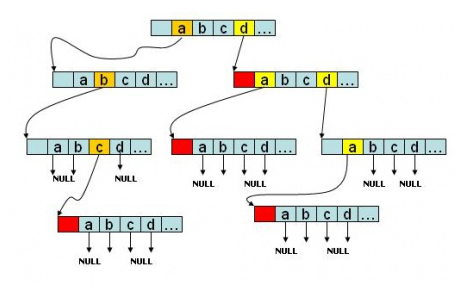
当然,最上面的上面还有个根结点。最左边就是我查找abc这个字符串的过程,中间一个对应为da,最右边为dda。很明显,这个Trie只有三个字符串,只要你想,空间够大,你完全可以存放一本英文大词典~~~。(开销不少哈哈哈)
好了,聊聊怎么建树吧。
Trie树一般有建立和查询两个基本操作,删除的操作挺少见的(目前还没见过,可能是见识短吧~)。
建树的过程其实很简单,首先,树的每个结点并不是简简单单的字符,而是包含了26个字符,还有一个指针域,指向下一个字符。
struct node
{
int cnt;
char c[];//结点所对应的字符
struct node *next[];
node ()
{
cnt = ;
memset(next,,sizeof(next));
}
};
node * root = NULL;//根结点初始为NULL
其中变量cnt有个作用,即表明让前结点是否为一个字符串的最后一个结点。不然这样一棵Trie树会无限循环建立下去,一个单词总有个长度的。
void BuildTrie(char *s,char *temp)
{
node *p = root;//p指向根结点
node *tmp = NULL;
int l = strlen(s);//计算创建单词的长度
for(int i = ;i < l ;i ++)//对每个字符处理
{
if(p->next[s[i]-'a'] == NULL)//如果p结点的指针对应的单词的字符为空,就要创建她
{//如 我要创建字符串为 china,而我发现当前只有个c,后面应该有的h却是空的,所以建立h
tmp = new node;//tmp为空
p->next[s[i]-'a'] = tmp;//p:目前的结点 如c,那么她的下一个字符指针指向tmp)
//tmp所对应的 字符就是h,为什么呢? 因为这个 “s[i]-'a'”,h-‘a’所对应的数组下标就是h
}
p = p->next[s[i]-'a'];//p更新为当前的结点即转移到h结点,继续上述过程
}
p->cnt = ;//到了最后一个a结点,将a的cnt置为1,表示这个单词结束了,按照这个路径下来查到的一定是china
strcpy(p->c,temp);//最后的叶子结点可以放你想查询到的最终结果,即你找到china所应该的信息
//如翻译 ,如果你找了china,那么我在最后放一个“中国”
}
在知道了怎么建树后,查询其实也差不多了,和建树很相似的过程。
void Query(char *s)
{
node *p = root;
int l = strlen(s);
for(int i = ;i< l ;i++)
{
if(p->next[s[i]-'a'] == NULL)
{
printf("404\n");
return ;
}
p = p->next[s[i]-'a'];
}
printf("%s\n",p->c);//打印最终查询结果
return ;
}
这里要说一句,这里的查询时间和树没多大关系,而是和所查找单词的长度有关(好像说了句废话-,-)。因为她有个亲戚叫二叉查找树,她也可以用来查单词,但是查找时间和树中结点数有关,复杂度为O(lon2n),而对于一个不是很长很长的字符串s来说,Trie只要比较strlen(s)次,而二叉查找树要比较log2(26^strlen(s))次,效率呢自己带个数看看就一目了然了~
当然,Trie不经可以用来检索单词,还能统计词频率(加计数),计算最长公共前缀,当然还能用来A题
Trie-Tree的更多相关文章
- 关于Trie Tree简单实现
最近突然有兴致hiho一下了,实现了下trie tree,感觉而言,还是挺有意思的,个人觉得这货不光可以用来查单词吧,其实也可以用来替代Hash,反正查找,插入复杂度都挺低的,哈哈,啥都不懂,瞎扯.. ...
- 字典树(Trie Tree)
终于要开始更新我的ACM学习之路了,不过没想到却是因为一次Java大作业,有趣,%yuan老师. 字典树是一种很简单的树形结构,主要用来进行词频统计,在算法竞赛中有时也会碰到. 字典树的基本思路是,通 ...
- 笔试算法题(39):Trie树(Trie Tree or Prefix Tree)
议题:TRIE树 (Trie Tree or Prefix Tree): 分析: 又称字典树或者前缀树,一种用于快速检索的多叉树结构:英文字母的Trie树为26叉树,数字的Trie树为10叉树:All ...
- Phone List POJ 3630 Trie Tree 字典树
Phone List Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 29416 Accepted: 8774 Descr ...
- Trie tree实践
1.Trie树 Trie树即字典树或前缀树, 2.实践 代码实践如下: package cn.edu.buaa.trie; import java.util.HashSet; /** * @autho ...
- 字典树(Trie Tree)
在图示中,键标注在节点中,值标注在节点之下.每一个完整的英文单词对应一个特定的整数.Trie 可以看作是一个确定有限状态自动机,尽管边上的符号一般是隐含在分支的顺序中的.键不需要被显式地保存在节点中. ...
- hdu3724Encoded Barcodes(Trie tree)
题目请戳这里 题目大意:给n个字符串,给m个询问,每个询问给k个条形码.每个条形码由8个小码组成,每个小码有相应的宽度,已知一个条形码的宽度只有2种,宽的表示1,窄的表示0.并且宽的宽度是窄的宽度的2 ...
- trie tree(字典树)
hihocoder题目(http://hihocoder.com/problemset):#1014 trie树 #include <iostream> using namespace s ...
- Find the Clones Trie Tree
Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 8306 Accepted: 3130 Description Doubl ...
- 字典树Trie Tree
又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种.典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计.它的优点是:利用字符串的公共前缀 ...
随机推荐
- PHP无限级树形结构算法(递归和引用)
测试数组 $array = [ [, , 'name' => '这是主类'], [, , 'name' => '这是主类'], [, , 'name' => '父级为1子类'], [ ...
- LC 918. Maximum Sum Circular Subarray
Given a circular array C of integers represented by A, find the maximum possible sum of a non-empty ...
- 使用libxml2创建和解析xml文件
毕业设计需要用到xml文件来组织和存放数据, 对于Linux环境下,有libxml2可供使用. 经过一段时间查询文档和网站, 基本掌握创建xml文档和解析xml的操作, 简单做一下记录. 创建xml ...
- nginx在windows系统中如何启动、重启、停止
nginx在windows系统中如何启动.重启.停止 查看nginx的版本号:nginx -v 启动nginx:start nginx 快速停止或关闭nginx:nginx -s stop 正常停 ...
- win7电脑删除保存的凭据
win7电脑删除保存的凭据: 控制面板-> 用户账户 -> 管理您的凭据
- PAT 甲级 1050 String Subtraction (20 分) (简单送分,getline(cin,s)的使用)
1050 String Subtraction (20 分) Given two strings S1 and S2, S=S1−S2 is defined to be t ...
- Go项目部署到服务器
-bash: ./main: cannot execute binary file 将 go build main.go 生成的文件上传到服务器后,./main 运行后出新的报错 env GOOS=l ...
- iOS-UINavigationController多控制器管理
UINavigationController 7.8.1 添加子控制器进栈 UINavigationController *nav = [[UINavigationController alloc] ...
- 异地协作,A地上传jar包到B地服务器上传速率慢
在A地使用ftp服务器,再登录B地的目标服务器,使用ftp命令从ftp服务器下载文件,速度快点,下载带宽比上传带宽要大一点 https://blog.csdn.net/df0128/article/d ...
- spacemacs:emacs和vim结合,大杀器。vim党转emacs
结合本人基础,做下述结论.不一定准确. 基础: 1. vim操作和高级操作,熟悉.使用的spf13-vim. 2. emacs以前学过,但是按键太累,相比vim简直难受. 3. emacs命令 ...