webpack中bundler源码编写2
const fs = require('fs'); // 帮助我们获取一些文件的信息
const path = require('path'); // 打包的时候需要绝对路径,借助path这个模块
const parser = require('@babel/parser'); // 帮助我们分析代码,引入的文件
const traverse = require('@babel/traverse').default;// 因为是export出来的内容,必须加一个default属性才可以
const babel = require('@babel/core'); // babel的核心模块,转化代码,转化成浏览器认识的代码
// 分析模块
const moduleAnalyser = (filename) => {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8');
// 利用parser.parse获取到ast,抽象语法树
const ast = parser.parse(content, {
sourceType: 'module' // 说明是es module的引入方式
});
// 利用traverse对代码进行一个分析
const dependencies = {};
traverse(ast, {
// 只要抽象语法树有ImportDeclaration就会进入这个方法,node是节点
ImportDeclaration({ node }){
// 拿到filename对应的文件夹路径
const dirname = path.dirname(filename);
// 对这个文件夹的路径进行一个转化,将引入的模块转化成相对于bundler的相对路径
const newFile = './' + path.join(dirname, node.source.value);
// 为了方便,把相对路径,绝对路径都存上,key是相对路径,value是绝对路径
dependencies[node.source.value] = newFile;
}
});
// 这个方法可以将抽象语法树转化成浏览器可以运行代码。
const { code } = babel.transformFromAst(ast, null, {
presets: ['@babel/preset-env'] // 把es6语法翻译成es5语法
});
// 返回入口文件和相对应的依赖,都可以分析出来了。
return {
filename,
dependencies,
code
}
}
// 依赖图谱函数,将所有分析好的模块放在这里
const makeDependenciesGraph = (entry) => {
const entryModule = moduleAnalyser(entry);
const graphArray = [entryModule];
// 循环入口文件
for(let i = 0; i < graphArray.length; i++) {
const item = graphArray[i];
const { dependencies } = item;
// 如果该模块有依赖文件,那么就对相应的依赖文件继续进行分析
if(dependencies) {
for(let j in dependencies) {
graphArray.push(moduleAnalyser(dependencies[j]));
}
}
}
// 打印出来,发现所有模块都分析好了。
console.log(graphArray);
}
const graphInfo = makeDependenciesGraph('./src/index.js');
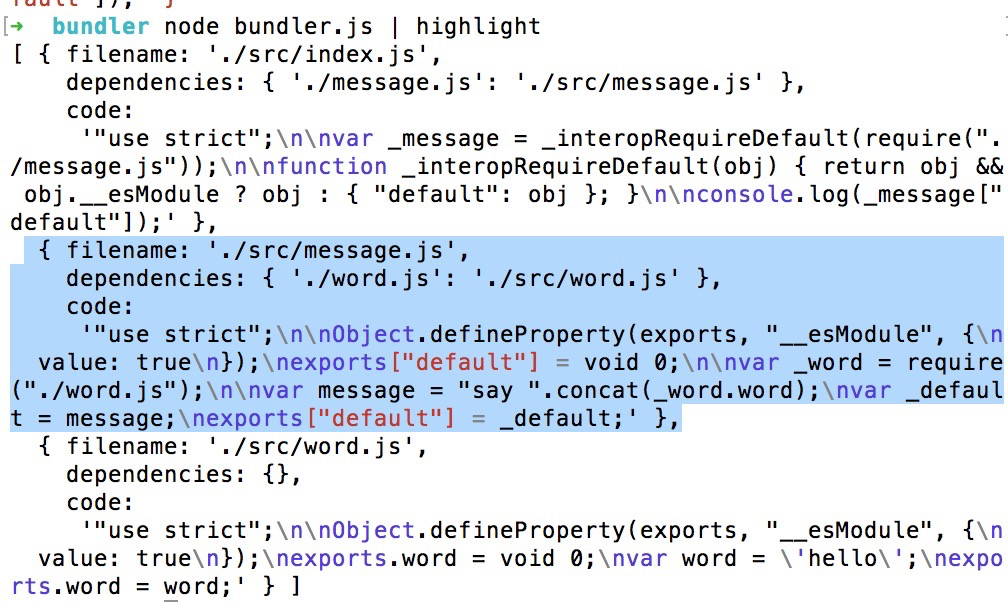
运行node bundler.js | highlight。发现所有模块的文件,依赖和翻译的代码都分析好了打印出来。这个就是我们的依赖图谱。
// 依赖图谱函数,将所有分析好的模块放在这里
const makeDependenciesGraph = (entry) => {
const entryModule = moduleAnalyser(entry);
const graphArray = [entryModule];
// 循环入口文件
for(let i = 0; i < graphArray.length; i++) {
const item = graphArray[i];
const { dependencies } = item;
// 如果该模块有依赖文件,那么就对相应的依赖文件继续进行分析
if(dependencies) {
for(let j in dependencies) {
graphArray.push(moduleAnalyser(dependencies[j]));
}
}
}
const graph = {};
graphArray.forEach(item => {
graph[item.filename] = {
dependencies: item.dependencies,
code: item.code
}
})
console.log(graph);
}

这个时候数组就编程了一个对象。
const fs = require('fs'); // 帮助我们获取一些文件的信息
const path = require('path'); // 打包的时候需要绝对路径,借助path这个模块
const parser = require('@babel/parser'); // 帮助我们分析代码,引入的文件
const traverse = require('@babel/traverse').default;// 因为是export出来的内容,必须加一个default属性才可以
const babel = require('@babel/core'); // babel的核心模块,转化代码,转化成浏览器认识的代码
// 分析模块
const moduleAnalyser = (filename) => {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8');
// 利用parser.parse获取到ast,抽象语法树
const ast = parser.parse(content, {
sourceType: 'module' // 说明是es module的引入方式
});
// 利用traverse对代码进行一个分析
const dependencies = {};
traverse(ast, {
// 只要抽象语法树有ImportDeclaration就会进入这个方法,node是节点
ImportDeclaration({ node }){
// 拿到filename对应的文件夹路径
const dirname = path.dirname(filename);
// 对这个文件夹的路径进行一个转化,将引入的模块转化成相对于bundler的相对路径
const newFile = './' + path.join(dirname, node.source.value);
// 为了方便,把相对路径,绝对路径都存上,key是相对路径,value是绝对路径
dependencies[node.source.value] = newFile;
}
});
// 这个方法可以将抽象语法树转化成浏览器可以运行代码。
const { code } = babel.transformFromAst(ast, null, {
presets: ['@babel/preset-env'] // 把es6语法翻译成es5语法
});
// 返回入口文件和相对应的依赖,都可以分析出来了。
return {
filename,
dependencies,
code
}
}
// 依赖图谱函数,将所有分析好的模块放在这里
const makeDependenciesGraph = (entry) => {
const entryModule = moduleAnalyser(entry);
const graphArray = [entryModule];
// 循环入口文件
for(let i = 0; i < graphArray.length; i++) {
const item = graphArray[i];
const { dependencies } = item;
// 如果该模块有依赖文件,那么就对相应的依赖文件继续进行分析
if(Object.getOwnPropertyNames(dependencies).length) {
for(let j in dependencies) {
graphArray.push(moduleAnalyser(dependencies[j]));
}
}
}
const graph = {};
graphArray.forEach(item => {
graph[item.filename] = {
dependencies: item.dependencies,
code: item.code
}
})
return graph;
}
const graphInfo = makeDependenciesGraph('./src/index.js');
console.log(graphInfo);
接下来我们就只要借助dependenciesGraph来生成真正可以在浏览器运行的代码。
const fs = require('fs'); // 帮助我们获取一些文件的信息
const path = require('path'); // 打包的时候需要绝对路径,借助path这个模块
const parser = require('@babel/parser'); // 帮助我们分析代码,引入的文件
const traverse = require('@babel/traverse').default;// 因为是export出来的内容,必须加一个default属性才可以
const babel = require('@babel/core'); // babel的核心模块,转化代码,转化成浏览器认识的代码
// 分析模块
const moduleAnalyser = (filename) => {
// 读取文件内容
const content = fs.readFileSync(filename, 'utf-8');
// 利用parser.parse获取到ast,抽象语法树
const ast = parser.parse(content, {
sourceType: 'module' // 说明是es module的引入方式
});
// 利用traverse对代码进行一个分析
const dependencies = {};
traverse(ast, {
// 只要抽象语法树有ImportDeclaration就会进入这个方法,node是节点
ImportDeclaration({ node }){
// 拿到filename对应的文件夹路径
const dirname = path.dirname(filename);
// 对这个文件夹的路径进行一个转化,将引入的模块转化成相对于bundler的相对路径
const newFile = './' + path.join(dirname, node.source.value);
// 为了方便,把相对路径,绝对路径都存上,key是相对路径,value是绝对路径
dependencies[node.source.value] = newFile;
}
});
// 这个方法可以将抽象语法树转化成浏览器可以运行代码。
const { code } = babel.transformFromAst(ast, null, {
presets: ['@babel/preset-env'] // 把es6语法翻译成es5语法
});
// 返回入口文件和相对应的依赖,都可以分析出来了。
return {
filename,
dependencies,
code
}
}
// 依赖图谱函数,将所有分析好的模块放在这里
const makeDependenciesGraph = (entry) => {
const entryModule = moduleAnalyser(entry);
const graphArray = [entryModule];
// 循环入口文件
for(let i = 0; i < graphArray.length; i++) {
const item = graphArray[i];
const { dependencies } = item;
// 如果该模块有依赖文件,那么就对相应的依赖文件继续进行分析
if(Object.getOwnPropertyNames(dependencies).length) {
for(let j in dependencies) {
graphArray.push(moduleAnalyser(dependencies[j]));
}
}
}
const graph = {};
graphArray.forEach(item => {
graph[item.filename] = {
dependencies: item.dependencies,
code: item.code
}
})
return graph;
}
// 这个函数结合dependenciesGraph来生成最后的代码
const generateCode = (entry) => {
// 拿到生成的 graph对象
const graph = JSON.stringify(makeDependenciesGraph(entry));
/**
* 1、避免污染全局,放在大的闭包里面
* 2、我们看到graph里面的源码有require,export这样的关键字,这个浏览器也是看不懂的,
* 所以如果想去直接去执行每个模块的代码,会报错的。所以首先需要在里面构建require
* 3、localRequire是相对路径转化的函数
*/
return `
(function(graph){
function require(module){
function localRequire(relativePath){
return require(graph[module].dependencies[relativePath])
}
var exports = {};
(function(require, exports, code){
eval(code);
})(localRequire, exports, graph[module].code);
return exports;
};
require('${entry}')
})(${graph});
`;
}
const code = generateCode('./src/index.js');
console.log(code);
webpack中bundler源码编写2的更多相关文章
- webpack中bundler源码编写
新建一个项目,再新建一个src文件夹,里面有三个文件,word.js,message.js,index.js word.js export const word = 'hello'; message. ...
- php中foreach源码分析(编译原理)
php中foreach源码分析(编译原理) 一.总结 编译原理(lex and yacc)的知识 二.php中foreach源码分析 foreach是PHP中很常用的一个用作数组循环的控制语句.因为它 ...
- vue打包时,assets目录 和static目录下文件的处理区别(nodeModule中插件源码修改后,打包后的文件应放在static目录)
为了回答这个问题,我们首先需要了解Webpack如何处理静态资产.在 *.vue 组件中,所有模板和CSS都会被 vue-html-loader 及 css-loader 解析,并查找资源URL.例如 ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- 【原】 Spark中Worker源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Worker源码分析(一)http://www.cnblogs.com/yourarebest/p/5300202.html 4.receive方法, r ...
- Django缓存机制--rest_framework中节流源码使用的就是django提供的缓存api
一.配置缓存 https://www.jb51.net/article/124434.htm 二.缓存全站.页面.局部 三.自我控制的简单缓存API API 接口为:django.core.c ...
- 深入理解 Node.js 中 EventEmitter源码分析(3.0.0版本)
events模块对外提供了一个 EventEmitter 对象,即:events.EventEmitter. EventEmitter 是NodeJS的核心模块events中的类,用于对NodeJS中 ...
- 从 sourcemap 中获取源码
使用 paazmaya/shuji: Reverse engineering JavaScript and CSS sources from sourcemaps 可以从 sourcemap 中获取源 ...
随机推荐
- JS和vue文本框输入改变p标签的内容测试
文本框输入,p标签的内容自动变成文本框的内容,如下是三种方法的测试: 方法1:JS里的onchange,当文本框内容改变事件,该事件里写的方法是,获取p标签本身,然后获取文本框的值,赋值给变量,最后给 ...
- 【Leetcode_easy】942. DI String Match
problem 942. DI String Match 参考 1. Leetcode_easy_942. DI String Match; 完
- docker中的fastdfs
准备环节)(本文遗漏当初出现的一个问题由于是docker装的fastdfs所以tracker storage client,nginx,nginx module都在同一个容器中只需要修改配置 特别注意 ...
- ROW_NUMBER()函数使用详解
原文地址:https://blog.csdn.net/qq_30908543/article/details/74108348 注:mysql貌似不适用,本人测试未成功,mysql实现方式可参考:ht ...
- Python机器学习基础教程-第2章-监督学习之K近邻
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- 【面试题】如何删除 ArrayList 中奇数位置的元素?
如何删除 ArrayList 中奇数位置的元素? 面试题携程 import java.util.ArrayList; import java.util.Iterator; import java.ut ...
- Quartz.Net—配置化
Schedule配置 线程数量 如果一个Schedule中有很多任务,这样默认的10个线程就不够用了. 有很多种方法配置线程的个数. 工厂构造函数 webfonfig quartzconfig 环境变 ...
- php实现映射
目录 映射 实现 链表实现: 二叉树实现 复杂度分析 映射 映射,或者射影,在数学及相关的领域经常等同于函数.基于此,部分映射就相当于部分函数,而完全映射相当于完全函数. 映射(Map)是用于存取键值 ...
- fputcsv 导出excel,解决内存、性能、乱码、科学计数法问题
在PHP的日常开发中,时常会需要导出 excel ,一般我们会使用 PHPExcel ,性能强大,但是在数据量大的时候,phpexcel 性能差.内存溢出等各种不可控问题就会出现.因此,如果对导出样式 ...
- TCP,SYN,FIN扫描
1.TCP扫描相对来说是速度比较慢的一种,为什么会慢呢?因为这种方法在扫描的时候会从本地主机的一个端口向目标主机的一个端口发出一个连接请求报文段,而目标主机在收到这个这个请求报文后: 有回复: 若同意 ...