AM--消息队列
kafka rocketMq零拷贝对比
https://cloud.tencent.com/developer/news/333695
还有Linux目录下的基本原理
RocketMQ Kafka Consumer消费消息过程,使用了零拷贝,零拷贝包含以下两种方式
1. 使用 mmap + write 方式
RocketMQ 选择了这种方式,mmap+write 方式,因为有小块数据传输的需求,效果会比 sendfile 更好。但是RocketMQ控制mmap映射的内存分配与释放的地方非常复杂,稍有不慎就会出问题。
优点:即使频繁调用,使用小块文件传输,效率也很高。
缺点:不能很好的利用 DMA 方式,会比 sendfile 多消耗 CPU,内存安全性控制复杂,需要避免 JVM Crash问题。
2. 使用 sendfile 方式
优点:可以利用 DMA 方式,消耗 CPU 较少,大块文件传输效率高,无内存安全性问题。
缺点:小块文件效率低于 mmap 方式,只能是 BIO 方式传输,不能使用 NIO。
sendfile:FileChannel.transferTo()只有源为FileChannel才支持transfer这种高效的复制方式,其他如SocketChannel都不支持transfer模式。当然,目的Channel没有这种限制。所以一般可以做FileChannel->FileChannel和FileChannel->SocketChannel的transfer。
KAFKA的索引文件使用mmap+write 方式,data文件使用sendfile 。
下面这个问题就是RocketMQ使用mmap后的潜在问题:

下面是详细介绍这两种零拷贝方式:
mmap 文件映射
通常情况下,我们可以使用和去访问文件,除此之外,Linux 还提供了系统调用,它可以将文件映射到进程的地址空间,这样程序就可以通过访问内存的方式去访问文件了。那么与和相比,使用去访问文件能带来什么好处呢?
使用一个明显的好处就是减少一次 I/O 拷贝,譬如说,当我们使用读取文件时,通常的做法是这样:
这个过程实际上发生了两次 I/O 拷贝,第一次是将磁盘中的文件内容拷贝到 OS 的文件系统缓冲区,第二次是将 OS 缓冲区的数据拷贝到用户缓冲区。而使用读取文件时,只会发生第一次拷贝操作,也就是将文件内容拷贝到 OS 文件系统缓冲区,完成这个拷贝操作之后,还会执行其它一些复杂的操作,例如将相应的 OS 缓冲区映射到进程的地址空间。
尽管可以减少一次 I/O 拷贝,但由于的实现很复杂,调用将会带来额外的开销,因此在一些情况下,没有使用的必要:
访问小文件时,直接使用或将更加高效。
单个进程对文件执行顺序访问时(sequential access),使用几乎不会带来性能上的提升。譬如说,使用顺序读取文件时,文件系统会使用 read-ahead 的方式提前将文件内容缓存到文件系统的缓冲区,因此使用将很大程度上可以命中缓存。
那么,在什么情况下使用去访问文件会更高效呢?
对文件执行随机访问时,如果使用或,则意味着较低的 cache 命中率。这种情况下使用通常将更高效。
多个进程同时访问同一个文件时(无论是顺序访问还是随机访问),如果使用,那么 OS 缓冲区的文件内容可以在多个进程之间共享,从操作系统角度来看,使用可以大大节省内存。
sendfile()
Web Server 处理静态页面请求时,通常是从磁盘中读取网页的内容,然后发送给客户端:
下图是传统的读写文件流程:

正如我们前面说到的,使用读取文件时,将发生两次 I/O 拷贝。然而,数据发送的过程也发生了两次 I/O 拷贝,第一次是将用户缓冲区的数据写入内核的 socket 发送缓冲区,成功写入之后会返回,在返回之后,内核会将 socket 发送缓冲区的数据拷贝到网卡驱动。可以看到,整个过程发生了四次 I/O 拷贝操作。
然而除了考虑 I/O 拷贝带来的开销,我们还要考虑系统 context switch 带来的开销,当程序调用时,系统会从用户态切换到内核态,而当返回时,又会导致系统从内核态切换到用户态,所以调用发生两次 context switch,同理,调用也会发生两次 context switch。
Linux 提供了用来减少我们前面提到的 I/O 拷贝和 context switch 的次数:

使用发送文件时,实际发生了三次 I/O 拷贝,第一次是将磁盘中的文件内容拷贝到 OS 的文件系统缓冲区,第二次是将 OS 缓冲区的数据拷贝到 socket 的发送缓冲区,最后一次是将 socket 发送缓冲区的数据发送到网卡驱动。可以看到,与使用和发送文件相比,使用减少了一次 I/O 拷贝和两次 context switch。
如果使用的网卡支持 scatter-gather 特性,那么还可以再减少一次 I/O 拷贝:

这种情况下,使用发送文件只会发生两次 I/O 拷贝,第一次是将磁盘中的文件拷贝到 OS 的文件系统缓冲区,而第二次是将 OS 缓冲区的数据直接拷贝到网卡驱动。可以使用下面的命令查看网卡是否支持 scatter-gather 特性。
如何保证消费的可靠性传输?
1.kafka
其实这个可靠性传输,每种MQ都要从三个角度来分析:生产者弄丢数据、消息队列弄丢数据、消费者弄丢数据
这里先引一张kafka Replication的数据流向图
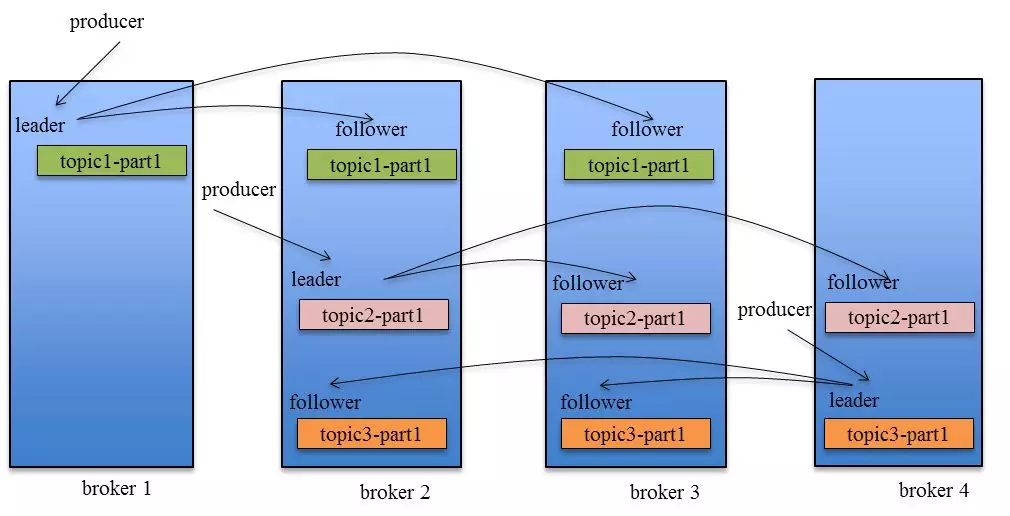
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少(也即该Partition有多少个Replica),Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader中pull数据。
针对上述情况,得出如下分析
(1)生产者丢数据
在kafka生产中,基本都有一个leader和多个follwer。follwer会去同步leader的信息。因此,为了避免生产者丢数据,做如下两点配置
第一个配置要在producer端设置acks=all。这个配置保证了,follwer同步完成后,才认为消息发送成功。
在producer端设置retries=MAX,一旦写入失败,这无限重试
(2)消息队列丢数据
针对消息队列丢数据的情况,无外乎就是,数据还没同步,leader就挂了,这时zookpeer会将其他的follwer切换为leader,那数据就丢失了。针对这种情况,应该做两个配置。
replication.factor参数,这个值必须大于1,即要求每个partition必须有至少2个副本
min.insync.replicas参数,这个值必须大于1,这个是要求一个leader至少感知到有至少一个follower还跟自己保持联系
这两个配置加上上面生产者的配置联合起来用,基本可确保kafka不丢数据
(3)消费者丢数据
这种情况一般是自动提交了offset,然后你处理程序过程中挂了。kafka以为你处理好了。再强调一次offset是干嘛的
offset:指的是kafka的topic中的每个消费组消费的下标。简单的来说就是一条消息对应一个offset下标,每次消费数据的时候如果提交offset,那么下次消费就会从提交的offset加一那里开始消费。
比如一个topic中有100条数据,我消费了50条并且提交了,那么此时的kafka服务端记录提交的offset就是49(offset从0开始),那么下次消费的时候offset就从50开始消费。
解决方案也很简单,改成手动提交即可。
AM--消息队列的更多相关文章
- 消息队列——RabbitMQ学习笔记
消息队列--RabbitMQ学习笔记 1. 写在前面 昨天简单学习了一个消息队列项目--RabbitMQ,今天趁热打铁,将学到的东西记录下来. 学习的资料主要是官网给出的6个基本的消息发送/接收模型, ...
- 消息队列 Kafka 的基本知识及 .NET Core 客户端
前言 最新项目中要用到消息队列来做消息的传输,之所以选着 Kafka 是因为要配合其他 java 项目中,所以就对 Kafka 了解了一下,也算是做个笔记吧. 本篇不谈论 Kafka 和其他的一些消息 ...
- .net 分布式架构之业务消息队列
开源QQ群: .net 开源基础服务 238543768 开源地址: http://git.oschina.net/chejiangyi/Dyd.BusinessMQ ## 业务消息队列 ##业务消 ...
- 【原创经验分享】WCF之消息队列
最近都在鼓捣这个WCF,因为看到说WCF比WebService功能要强大许多,另外也看了一些公司的招聘信息,貌似一些中.高级的程序员招聘,都有提及到WCF这一块,所以,自己也关心关心一下,虽然目前工作 ...
- Java消息队列--ActiveMq 实战
1.下载安装ActiveMQ ActiveMQ官网下载地址:http://activemq.apache.org/download.html ActiveMQ 提供了Windows 和Linux.Un ...
- Java消息队列--JMS概述
1.什么是JMS JMS即Java消息服务(Java Message Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送 ...
- 消息队列性能对比——ActiveMQ、RabbitMQ与ZeroMQ(译文)
Dissecting Message Queues 概述: 我花了一些时间解剖各种库执行分布式消息.在这个分析中,我看了几个不同的方面,包括API特性,易于部署和维护,以及性能质量..消息队列已经被分 ...
- Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇
目前业界流行的分布式消息队列系统(或者可以叫做消息中间件)种类繁多,比如,基于Erlang的RabbitMQ.基于Java的ActiveMQ/Apache Kafka.基于C/C++的ZeroMQ等等 ...
- Netty构建分布式消息队列实现原理浅析
在本人的上一篇博客文章:Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇 中,重点向大家介绍了AvatarMQ主要构成模块以及目前存在的优缺点.最后以一个生产者.消费者传递消息的例子, ...
- C#分布式消息队列 EQueue 2.0 发布啦
前言 最近花了我几个月的业余时间,对EQueue做了一个重大的改造,消息持久化采用本地写文件的方式.到现在为止,总算完成了,所以第一时间写文章分享给大家这段时间我所积累的一些成果. EQueue开源地 ...
随机推荐
- 算法习题---5.1大理石在哪(UVa10474)
一:题目 现有N个大理石,每个大理石上写了一个非负整数.首先把各数从小到大排序,然后回答Q个问题.每个问题问是否有一个大理石写着某个整数x,如果是,还要回答哪个大理石上写着x.排序后的大理石从左到右编 ...
- [转]Office 安装卸载太麻烦?用这个工具帮你解决:Office Tool Plus
原文链接:https://sspai.com/post/43839 Office Tool官方网站:https://otp.landian.vip/zh-cn/ 真的很好用,发一个安装的截图:
- anywhere随启随用的静态文件服务器
手机移动端调试,也可以使用anywhere anywhere -p 8080 指定端口 anywhere -s 保持浏览器关闭 anywhere -h localhost -p 8080 通过主机名 ...
- java-socket-demo的实现
目录 前言 IO通讯模型 IO通讯模型简介 1. 阻塞式同步IO 2. 非阻塞式同步IO 3. 多路复用IO(阻塞+非阻塞) 4. 异步IO Java对IO模型的支持 注意点及实现方案 TCP粘包/拆 ...
- skynet sproto 问题
刚碰到一个小细节,纠结了半个小时 sproto的协议,request 和{ 必须有空格
- Codeforces-Two Buttons-520problemB(思维题)
B. Two Buttons Vasya has found a strange device. On the front panel of a device there are: a red but ...
- python开发【学习目录】:目录
python开发[学习目录]:目录 Python开发:环境搭建(python3.PyCharm) Python开发[第一篇]:初识Python Python开发[第二篇]:Python基础知识 Pyt ...
- Quartz.Net—Calendar
动态的排除一些触发器的时间. DailyCalendar-天日历 定义: This implementation of the Calendar excludes (or includes - see ...
- Prometheus入门到放弃(1)之Prometheus安装部署
规划: IP 角色 版本 10.10.0.13 prometheus-server 2.10 10.10.0.11 node_exporter 0.18.1 10.10.0.12 node_expor ...
- Python 发送微信小程序的模板消息
在小程序的开发过程中,会存在模板消息的发送,具体文档见 这里,模板消息的发送是和语言无关的,这里将简要写一下怎么用 Python 给用户发送模板消息. 通过文档可以知道,发送的时候,需要使用小 ...