hive基本结构与数据存储
一、Hive简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。还可以将 SQL 语句转换为 MapReduce 任务进行运行,通过自己的 SQL 去 查询分析需要的内容,这套 SQL 简称 HQL。使用hive的优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive将元数据存储在数据库(RDBMS)中,比如MySQL、Derby中。Hive有三种模式连接到数据,其方式是:单用户模式,多用户模式和远程服务模式。(也就是内嵌模式、本地模式、远程模式)。
Hive特点:
1.可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
2. 延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
3.容错
良好的容错性,节点出现问题SQL仍可完成执行。
二、Hive架构
Hive体系结构如下图:
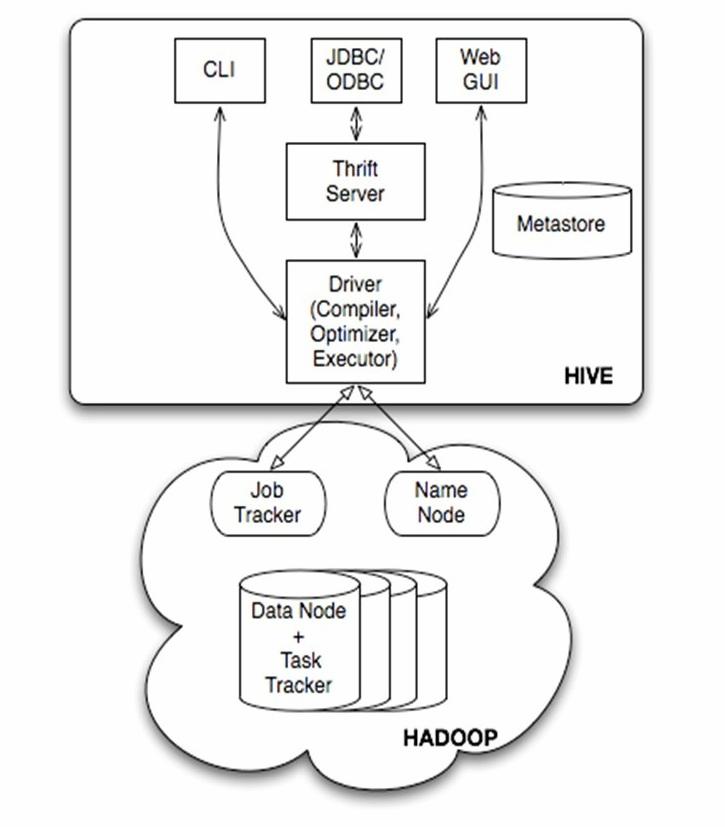
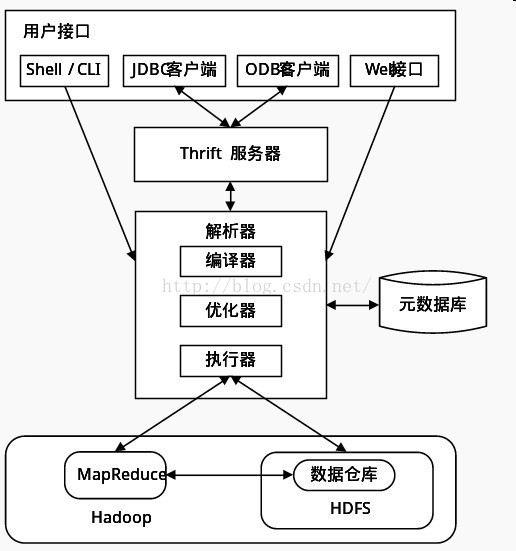
再来一张中文的图:
其中第一张图中的Jobtracker是hadoop1.x中的组件,它的功能相当于hadoop2.x中的: Resourcemanager+AppMaster
TaskTracker 相当于: Nodemanager + yarnchild
从上图可以看出,Hive体系结构大概分成一下四个部分:
1.用户接口:包括 CLI, Client, WUI。其中最常用的是 CLI,CLI为shell命令行,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
2.元数据存储:通常是存储在关系数据库如 mysql, derby 中
3.解释器、编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有MapReduce 调用执行。
4Hadoop:Hive中数据用 HDFS 进行存储,利用 MapReduce 进行计算。
三、数据存储
首先需要清楚Hive中数据存储的位置,元数据(即对数据的描述,包括表,表的列及其它各种属性)是存储在MySQL等数据库中的,因为这些数据要不断的更新,修改,不适合存储在HDFS中。
而真正的数据是存储在HDFS中,这样更有利于对数据做分布式运算。
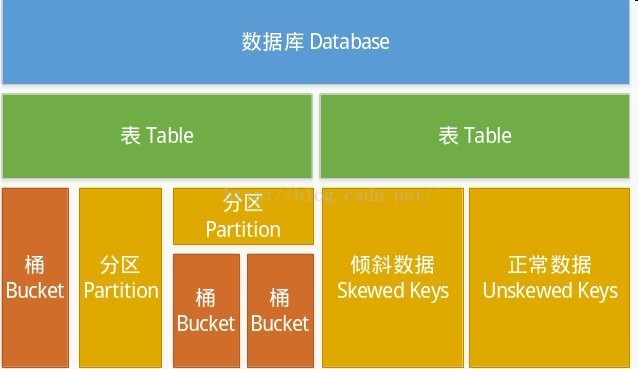
Hive中主要包括四类数据模型:
1、表:Hive中的表和关系型数据库中的表在概念上很类似,每个表在HDFS中都有相应的目录用来存储表的数据,这个目录可以通过${HIVE_HOME}/conf/hive-site.xml配置文件中的 hive.metastore.warehouse.dir属性来配置,这个属性默认的值是/user/hive/warehouse(这个目录在 HDFS上),我们可以根据实际的情况来修改这个配置。如果我有一个表wyp,那么在HDFS中会创建/user/hive/warehouse/wyp 目录(这里假定hive.metastore.warehouse.dir配置为/user/hive/warehouse);wyp表所有的数据都存放在这个目录中。这个例外是外部表。
2、外部表:Hive中的外部表和表很类似,但是其数据不是放在自己表所属的目录中,而是存放到别处,这样的好处是如果你要删除这个外部表,该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;而如果你要删除表,该表对应的所有数据包括元数据都会被删除。
3、分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。比如wyp 表有dt和city两个分区,则对应dt=20131218,city=BJ对应表的目录为/user/hive/warehouse /dt=20131218/city=BJ,所有属于这个分区的数据都存放在这个目录中。
4、桶:对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。比如将wyp表id列分散至16个桶中,首先对id列的值计算hash,对应hash值为0和16的数据存储的HDFS目录为:/user /hive/warehouse/wyp/part-00000;而hash值为2的数据存储的HDFS 目录为:/user/hive/warehouse/wyp/part-00002。
hive基本结构与数据存储的更多相关文章
- MySQL 5.7:非结构化数据存储的新选择
本文转载自:http://www.innomysql.net/article/23959.html (只作转载, 不代表本站和博主同意文中观点或证实文中信息) 工作10余年,没有一个版本能像MySQL ...
- 一起学Hive——总结复制Hive表结构和数据的方法
在使用Hive的过程中,复制表结构和数据是很常用的操作,本文介绍两种复制表结构和数据的方法. 1.复制非分区表表结构和数据 Hive集群中原本有一张bigdata17_old表,通过下面的SQL语句可 ...
- C#中将结构类型数据存储到二进制文件中方法
以往在vb6,vc6中都有现成的方法将结构类型数据写入和读取到二进制文件中,但是在c#中却没有现成的方法来实现,因此我查阅了一些资料,借鉴了网上一些同学的做法,自己写了个类似的例子来读写结构类型数据到 ...
- spark 解析非结构化数据存储至hive的scala代码
//提交代码包 // /usr/local/spark/bin$ spark-submit --class "getkv" /data/chun/sparktes.jar impo ...
- [Hive - Tutorial] Data Units 数据存储单位
Data Units In the order of granularity - Hive data is organized into: 数据库.表.分区.桶 Databases: Namespac ...
- Scrapy系列教程(2)------Item(结构化数据存储结构)
Items 爬取的主要目标就是从非结构性的数据源提取结构性数据,比如网页. Scrapy提供 Item 类来满足这种需求. Item 对象是种简单的容器.保存了爬取到得数据. 其提供了 类似于词典(d ...
- HBase介绍(2)---数据存储结构
在本文中的HBase术语:基于列:column-oriented行:row列组:column families列:column单元:cell 理解HBase(一个开源的Google的BigTable实 ...
- Hive_Hive的数据模型_数据存储
Hive的数据模型_数据存储 web管理工具察看HDFS文件系统:http://<IP>:50070/ 基于HDFS没有专门的数据存储格式,默认使用制表符存储结构主要包括:数据库,文件,表 ...
- 67.Android中的数据存储总结
转载:http://mp.weixin.qq.com/s?__biz=MzIzMjE1Njg4Mw==&mid=2650117688&idx=1&sn=d6c73f9f04d0 ...
随机推荐
- C# 字符串与字节数组相互转换
https://www.cnblogs.com/xiaoqingshe/p/5882601.html
- 远程使用tomcat8的首页的管理工具
1.在%Tomcat_Home%/conf/Catalina/localhost中新建manager.xml,内容如下 <Context privileged="true" ...
- codefroce385E矩阵快速幂
状态变化 (x,y,dx,dy,i) 表示i时刻熊站在(x,y)处速度向量(dx,dy)下一个状态是 ( 2x+y+dx+i , x+2y+dy+i , x+y+dx , x+y+dy , i+1 ...
- Delphi 简体 繁体 转换
http://delphi.ktop.com.tw/board.php?cid=30&fid=69&tid=104986 試看看 這個是豬寶寶從網路上抄來的 檢視純文字版列印? fun ...
- 中兴u880e精简教程
精简软件请参考此处 (A代表可以删除,B代表建议别删除.)删或留你做主. Accounts AndSyncSettings.apk 账户与同步设置 A alarming.apk 闹钟时钟 A Appl ...
- 将int转int数组并将int数组元素处理后转int,实现加密
package faceobject; import java.util.Arrays; public class Test { /** 加密问题 数据是小于8位的整数 先将数据倒序,然后将每位数字都 ...
- Ubuntu文本编辑(vi和nano)命令
vi是Unix世界里极为普遍的全萤幕文书编辑器,几乎可以说任何一台Unix机器都会提供这套软体就像windows的记事本一样. 键入 vi /etc/hosts 进入vi界面,把光标移动到文件未尾.按 ...
- iOS-----线程同步与线程通信
线程同步与线程通信 多线程是有趣的事情,它很容易突然出现”错误情况”,这是由于系统的线程调度具有一定的随机性造成的.不过,即使程序偶然出现问题,那么是由于编程不当所引起的.当使用多个线程来访问同一个数 ...
- Js 手风琴效果
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...
- asp.net 操作word 权限
1.先安装office 2.在“DCOM配置”中,为IIS账号配置操作Word(其他Office对象也一样)的权限: 开始>运行>输入 dcomcnfg >确定 具体操作:“组件 ...