hive基本结构与数据存储
一、Hive简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。还可以将 SQL 语句转换为 MapReduce 任务进行运行,通过自己的 SQL 去 查询分析需要的内容,这套 SQL 简称 HQL。使用hive的优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive将元数据存储在数据库(RDBMS)中,比如MySQL、Derby中。Hive有三种模式连接到数据,其方式是:单用户模式,多用户模式和远程服务模式。(也就是内嵌模式、本地模式、远程模式)。
Hive特点:
1.可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
2. 延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
3.容错
良好的容错性,节点出现问题SQL仍可完成执行。
二、Hive架构
Hive体系结构如下图:
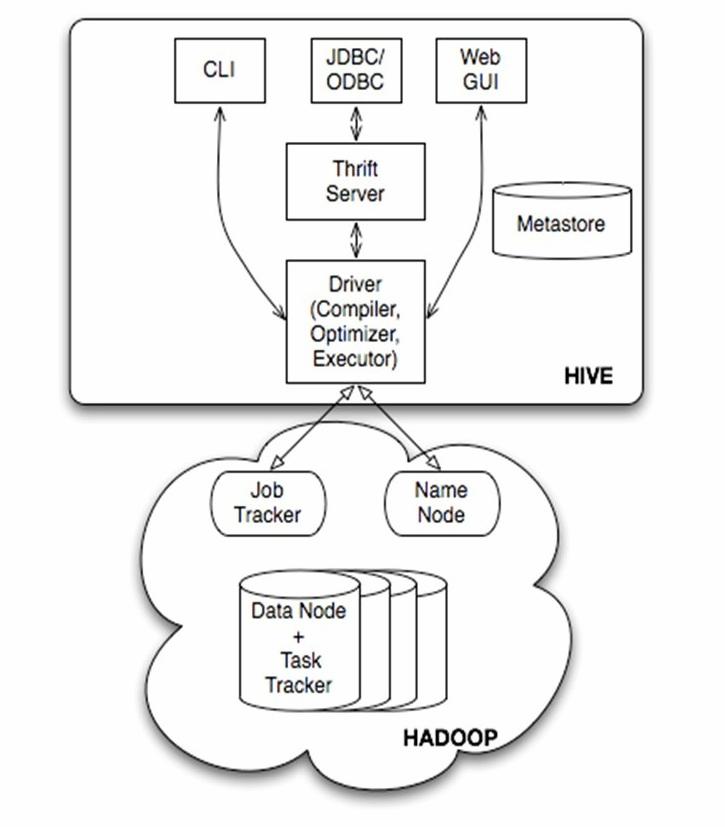
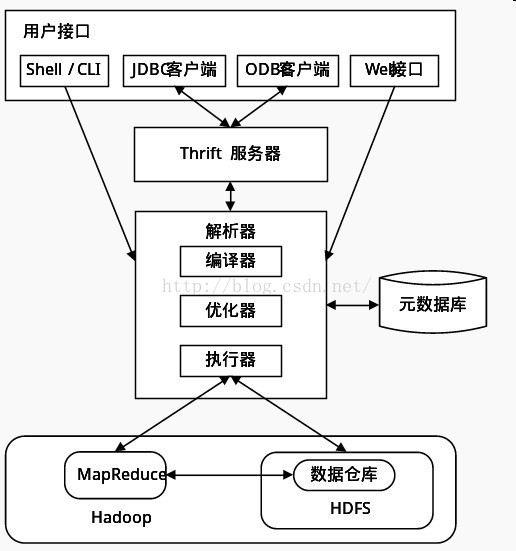
再来一张中文的图:
其中第一张图中的Jobtracker是hadoop1.x中的组件,它的功能相当于hadoop2.x中的: Resourcemanager+AppMaster
TaskTracker 相当于: Nodemanager + yarnchild
从上图可以看出,Hive体系结构大概分成一下四个部分:
1.用户接口:包括 CLI, Client, WUI。其中最常用的是 CLI,CLI为shell命令行,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
2.元数据存储:通常是存储在关系数据库如 mysql, derby 中
3.解释器、编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有MapReduce 调用执行。
4Hadoop:Hive中数据用 HDFS 进行存储,利用 MapReduce 进行计算。
三、数据存储
首先需要清楚Hive中数据存储的位置,元数据(即对数据的描述,包括表,表的列及其它各种属性)是存储在MySQL等数据库中的,因为这些数据要不断的更新,修改,不适合存储在HDFS中。
而真正的数据是存储在HDFS中,这样更有利于对数据做分布式运算。
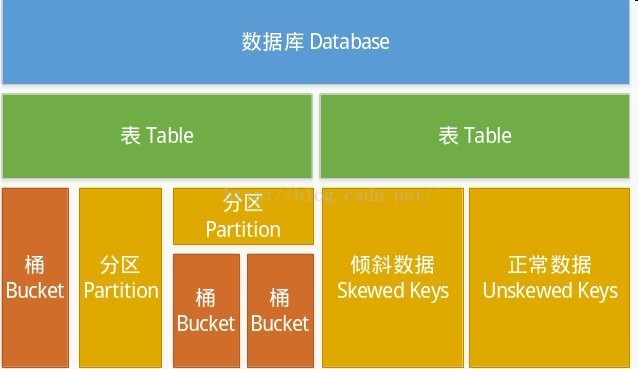
Hive中主要包括四类数据模型:
1、表:Hive中的表和关系型数据库中的表在概念上很类似,每个表在HDFS中都有相应的目录用来存储表的数据,这个目录可以通过${HIVE_HOME}/conf/hive-site.xml配置文件中的 hive.metastore.warehouse.dir属性来配置,这个属性默认的值是/user/hive/warehouse(这个目录在 HDFS上),我们可以根据实际的情况来修改这个配置。如果我有一个表wyp,那么在HDFS中会创建/user/hive/warehouse/wyp 目录(这里假定hive.metastore.warehouse.dir配置为/user/hive/warehouse);wyp表所有的数据都存放在这个目录中。这个例外是外部表。
2、外部表:Hive中的外部表和表很类似,但是其数据不是放在自己表所属的目录中,而是存放到别处,这样的好处是如果你要删除这个外部表,该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;而如果你要删除表,该表对应的所有数据包括元数据都会被删除。
3、分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。比如wyp 表有dt和city两个分区,则对应dt=20131218,city=BJ对应表的目录为/user/hive/warehouse /dt=20131218/city=BJ,所有属于这个分区的数据都存放在这个目录中。
4、桶:对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。比如将wyp表id列分散至16个桶中,首先对id列的值计算hash,对应hash值为0和16的数据存储的HDFS目录为:/user /hive/warehouse/wyp/part-00000;而hash值为2的数据存储的HDFS 目录为:/user/hive/warehouse/wyp/part-00002。
hive基本结构与数据存储的更多相关文章
- MySQL 5.7:非结构化数据存储的新选择
本文转载自:http://www.innomysql.net/article/23959.html (只作转载, 不代表本站和博主同意文中观点或证实文中信息) 工作10余年,没有一个版本能像MySQL ...
- 一起学Hive——总结复制Hive表结构和数据的方法
在使用Hive的过程中,复制表结构和数据是很常用的操作,本文介绍两种复制表结构和数据的方法. 1.复制非分区表表结构和数据 Hive集群中原本有一张bigdata17_old表,通过下面的SQL语句可 ...
- C#中将结构类型数据存储到二进制文件中方法
以往在vb6,vc6中都有现成的方法将结构类型数据写入和读取到二进制文件中,但是在c#中却没有现成的方法来实现,因此我查阅了一些资料,借鉴了网上一些同学的做法,自己写了个类似的例子来读写结构类型数据到 ...
- spark 解析非结构化数据存储至hive的scala代码
//提交代码包 // /usr/local/spark/bin$ spark-submit --class "getkv" /data/chun/sparktes.jar impo ...
- [Hive - Tutorial] Data Units 数据存储单位
Data Units In the order of granularity - Hive data is organized into: 数据库.表.分区.桶 Databases: Namespac ...
- Scrapy系列教程(2)------Item(结构化数据存储结构)
Items 爬取的主要目标就是从非结构性的数据源提取结构性数据,比如网页. Scrapy提供 Item 类来满足这种需求. Item 对象是种简单的容器.保存了爬取到得数据. 其提供了 类似于词典(d ...
- HBase介绍(2)---数据存储结构
在本文中的HBase术语:基于列:column-oriented行:row列组:column families列:column单元:cell 理解HBase(一个开源的Google的BigTable实 ...
- Hive_Hive的数据模型_数据存储
Hive的数据模型_数据存储 web管理工具察看HDFS文件系统:http://<IP>:50070/ 基于HDFS没有专门的数据存储格式,默认使用制表符存储结构主要包括:数据库,文件,表 ...
- 67.Android中的数据存储总结
转载:http://mp.weixin.qq.com/s?__biz=MzIzMjE1Njg4Mw==&mid=2650117688&idx=1&sn=d6c73f9f04d0 ...
随机推荐
- python 返回系统位数
# For bit it will and bit it will import struct print()
- redis缓存穿透、缓存击穿、缓存雪崩
缓存穿透 缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透. 解决办法: 预校验 在控 ...
- mongo学亮的分享
# MongoDB 集群部署## 关键词* 集群* 副本集* 分片## MongoDB集群部署>今天主要来说说Mongodb的三种集群方式的搭建Replica Set副本集 / Sharding ...
- Mybatis之SSM配置
applicationContext-dao.xml <?xml version="1.0" encoding="UTF-8"?> <bean ...
- VGG16提取图像特征 (torch7)
VGG16提取图像特征 (torch7) VGG16 loadcaffe torch7 下载pretrained model,保存到当前目录下 th> caffemodel_url = 'htt ...
- Hibernate主键生成器
主键生成器负责生成数据表记录的主键:increment:为long,short或者int类型主键生成唯一标识.只有在没有其他进程往同一张表中插入数据时才能使用.在集群下不能使用! identity:在 ...
- [转载]java正则表达式
转载自:http://butter.iteye.com/blog/1189600 1.正则表达式的知识要点1.正则表达式是什么?正则表达式是一种可以用于模式匹配和替换的强有力的工具.2.正则表达式的优 ...
- 关于yo3 所遇到的问题
关于去哪儿开发的yo3 库,实在不敢恭维 ,没有最坑,只有更坑. 官方文档写的实在是 ,有element,iview,ant-design等等一半也可以 ,个人观点. 在使用Scroller中, 自动 ...
- 公式中表达单个双引号【"】和空值【""】的方法及说明
http://club.excelhome.net/thread-661904-1-1.html 有人问为什么不用三个双引号"""来表示单个双引号["]呢,如果 ...
- linux中~和/区别
/是指根目录 就是所有目录最顶层的目录~指的是你当前用户的主目录 如果是root用户的话就是/root/目录 如果是其他用户的话就是/home/下以你用户名命名的用户 在linux里面,~/ ...