Scala学习之路 (九)Scala的上界和下届
一、泛型
1、泛型的介绍
泛型用于指定方法或类可以接受任意类型参数,参数在实际使用时才被确定,泛型可以有效地增强程序的适用性,使用泛型可以使得类或方法具有更强的通用性。泛型的典型应用场景是集合及集合中的方法参数,可以说同java一样,scala中泛型无处不在,具体可以查看scala的api。
2、泛型类、泛型方法
泛型类:指定类可以接受任意类型参数。
泛型方法:指定方法可以接受任意类型参数。
3、示例
1、定义泛型类
/* 下面的意思就是表示只要是Comparable就可以传递,下面是类上定义的泛型
*/
class GenericTest1[T <: Comparable[T]] { def choose(one:T,two:T): T ={
//定义一个选择的方法
if(one.compareTo(two) > ) one else two
} } class Boy(val name:String,var age:Int) extends Comparable[Boy]{
override def compareTo(o: Boy): Int = {
this.age - o.age
}
} object GenericTestOne{
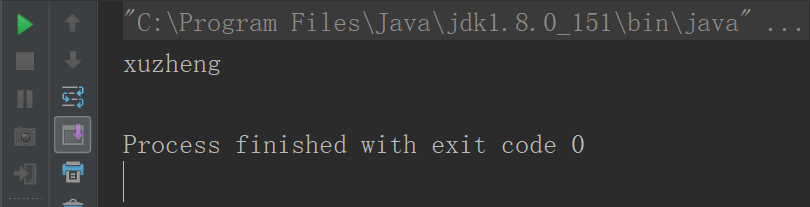
def main(args: Array[String]): Unit = {
val gt = new GenericTest1[Boy]
val huangbo = new Boy("huangbo",)
val xuzheng = new Boy("xuzheng",)
val boy = gt.choose(huangbo,xuzheng)
println(boy.name)
}
}
2、定义泛型方法
class GenericTest2{
//在方法上定义泛型
def choose[T <: Comparable[T]](one:T,two:T): T ={
if(one.compareTo(two) > ) one else two
}
}
class Boy(val name:String,var age:Int) extends Comparable[Boy]{
override def compareTo(o: Boy): Int = {
this.age - o.age
}
}
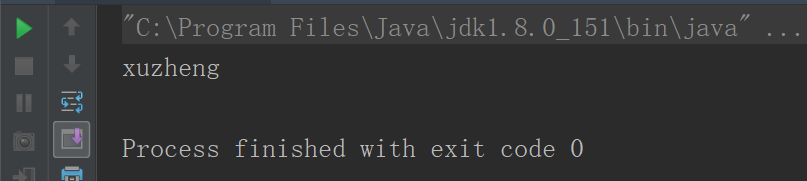
object GenericTestTwo{
def main(args: Array[String]): Unit = {
val gt = new GenericTest2
val huangbo = new Boy("huangbo",)
val xuzheng = new Boy("xuzheng",)
val boy = gt.choose(huangbo,xuzheng)
println(boy)
}
}
二、上界和下届
1、介绍
在指定泛型类型时,有时需要界定泛型类型的范围,而不是接收任意类型。比如,要求某个泛型类型,必须是某个类的子类,这样在程序中就可以放心的调用父类的方法,程序才能正常的使用与运行。此时,就可以使用上下边界Bounds的特性;
Scala的上下边界特性允许泛型类型是某个类的子类,或者是某个类的父类;
(1) U >: T
这是类型下界的定义,也就是U必须是类型T的父类(或本身,自己也可以认为是自己的父类)。
(2) S <: T
这是类型上界的定义,也就是S必须是类型T的子类(或本身,自己也可以认为是自己的子类)。
2、示例
(1)上界示例
参照上面的泛型方法
(2)下界示例
class GranderFather
class Father extends GranderFather
class Son extends Father
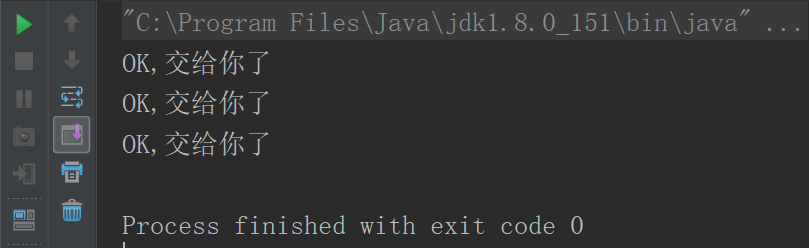
class Tongxue object Card{
def getIDCard[T >: Son](person:T): Unit ={
println("OK,交给你了")
}
def main(args: Array[String]): Unit = {
getIDCard[GranderFather](new Father)
getIDCard[GranderFather](new GranderFather)
getIDCard[GranderFather](new Son)
//getIDCard[GranderFather](new Tongxue)//报错,所以注释 }
}
三、协变和逆变
对于一个带类型参数的类型,比如 List[T]:
如果对A及其子类型B,满足 List[B]也符合 List[A]的子类型,那么就称为covariance(协变);
如果 List[A]是 List[B]的子类型,即与原来的父子关系正相反,则称为contravariance(逆变)。
协变
____ _____________
| | | |
| A | | List[ A ] |
|_____| |_____________|
^ ^
| |
_____ _____________
| | | |
| B | | List[ B ] |
|_____| |_____________|
逆变
____ _____________
| | | |
| A | | List[ B ] |
|_____| |_____________|
^ ^
| |
_____ _____________
| | | |
| B | | List[ A ] |
|_____| |_____________|
在声明Scala的泛型类型时,“+”表示协变,而“-”表示逆变。
- C[+T]:如果A是B的子类,那么C[A]是C[B]的子类。
- C[-T]:如果A是B的子类,那么C[B]是C[A]的子类。
- C[T]:无论A和B是什么关系,C[A]和C[B]没有从属关系。
根据Liskov替换原则,如果A是B的子类,那么能适用于B的所有操作,都适用于A。让我们看看这边Function1的定义,是否满足这样的条件。假设Bird是Animal的子类,那么看看下面两个函数之间是什么关系:
def f1(x: Bird): Animal // instance of Function1[Bird, Animal]
def f2(x: Animal): Bird // instance of Function1[Animal, Bird]
在这里f2的类型是f1的类型的子类。为什么?
我们先看一下参数类型,根据Liskov替换原则,f1能够接受的参数,f2也能接受。在这里f1接受的Bird类型,f2显然可以接受,因为Bird对象可以被当做其父类Animal的对象来使用。
再看返回类型,f1的返回值可以被当做Animal的实例使用,f2的返回值可以被当做Bird的实例使用,当然也可以被当做Animal的实例使用。
所以我们说,函数的参数类型是逆变的,而函数的返回类型是协变的。
那么我们在定义Scala类的时候,是不是可以随便指定泛型类型为协变或者逆变呢?答案是否定的。通过上面的例子可以看出,如果将Function1的参数类型定义为协变,或者返回类型定义为逆变,都会违反Liskov替换原则,因此,Scala规定,协变类型只能作为方法的返回类型,而逆变类型只能作为方法的参数类型。类比函数的行为,结合Liskov替换原则,就能发现这样的规定是非常合理的。
总结:参数是逆变的或者不变的,返回值是协变的或者不变的。
Scala学习之路 (九)Scala的上界和下届的更多相关文章
- Scala 学习之路(九)—— 继承和特质
一.继承 1.1 Scala中的继承结构 Scala中继承关系如下图: Any是整个继承关系的根节点: AnyRef包含Scala Classes和Java Classes,等价于Java中的java ...
- Scala学习之路----基础入门
一.Scala解释器的使用 REPL:Read(取值)-> Evaluation(求值)-> Print(打印)-> Loop(循环) scala解释器也被称为REPL,会快速编译s ...
- Scala学习之路 (十)Scala的Actor
一.Scala中的并发编程 1.Java中的并发编程 ①Java中的并发编程基本上满足了事件之间相互独立,但是事件能够同时发生的场景的需要. ②Java中的并发编程是基于共享数据和加锁的一种机制,即会 ...
- Scala学习之路 (四)Scala的数组、映射、元组、集合
一.数组 1.定长数组和变长数组 import scala.collection.mutable.ArrayBuffer object TestScala { def main(args: Array ...
- Scala 学习之路(八)—— 类和对象
一.初识类和对象 Scala的类与Java的类具有非常多的相似性,示例如下: // 1. 在scala中,类不需要用public声明,所有的类都具有公共的可见性 class Person { // 2 ...
- Scala 学习之路(四)—— 数组Array
一.定长数组 在Scala中,如果你需要一个长度不变的数组,可以使用Array.但需要注意以下两点: 在Scala中使用(index)而不是[index]来访问数组中的元素,因为访问元素,对于Scal ...
- Scala 学习之路(二)—— 基本数据类型和运算符
一.数据类型 1.1 类型支持 Scala 拥有下表所示的数据类型,其中Byte.Short.Int.Long和Char类型统称为整数类型,整数类型加上Float和Double统称为数值类型.Scal ...
- Scala 学习之路(一)—— Scala简介及开发环境配置
一.Scala简介 1.1 概念 Scala全称为Scalable Language,即“可伸缩的语言”,之所以这样命名,是因为它的设计目标是希望伴随着用户的需求一起成长.Scala是一门综合了面向对 ...
- scala学习——(1)scala基础(下)
(七)定长数组 val array_name = new Array[T](length) val array_name = Array("","") 通过() ...
随机推荐
- C# 最大二叉堆算法
C#练习二叉堆算法. namespace 算法 { /// <summary> /// 最大堆 /// </summary> /// <typeparam name=&q ...
- JFinal -基于Java 语言的MVC极速 web 开发框架
JFinal概述 JFinal 是基于Java 语言的极速 web 开发框架,其核心设计目标是开发迅速.代码量少.学习简单.功能强大.轻量级.易扩展.Restful.在拥有Java语言所有优势的同时再 ...
- Code Signal_练习题_firstDigit
Find the leftmost digit that occurs in a given string. Example For inputString = "var_1__Int&qu ...
- js-设计模式学习笔记-策略模式
策略模式的定义是:定义一系列的算法,把它们一个个封装起来,并且使它们可以相互替换(相互替换:表现为它们具有相同的目标和意图). 策略模式的目的是讲算法的使用与算法的实现分离开来. 一个基于策略模式的程 ...
- Windows7系统如果安装&升级IE11浏览器
作为一个前端工作人员,IE678简直就是噩梦,还好现在大多数网站已经开始放弃了对IE6/7/8的支持了. 由于Win7系统默认是安装的IE8,所以在打开部分网站时会提示:IE浏览器版本过低.解决方法如 ...
- Android 常见adb命令
Android 常见adb命令 by:授客 QQ:1033553122 1. 查看所有已链接的设备 命令: adb devices 例: C:\Users\laiyu>adb device ...
- localStorage/cookie 用法分析与简单封装
本地存储是HTML5中提出来的概念,分localStorage和sessionStorage.通过本地存储,web应用程序能够在用户浏览器中对数据进行本地的存储.与 cookie 不同,存储限制要大得 ...
- 团队项目第二阶段个人进展——Day1
一.昨天工作总结 冲刺第一天,查看了第一阶段的代码 二.遇到的问题 写个的代码发现看不懂了 三.今日工作规划 重新设计页面布局
- 想涨工资吗?那就学习Scala,Golang或Python吧
[编者按]据薪水调查机构 PayScale 提供的数据显示,掌握 Scala,Golang 和 Python 语言以及诸如 Apache Spark 之类的大数据技术,能带来最大的薪水提升.本文作者为 ...
- EVE Online Third Party Development
第一部分:price_history表 # 建表语句 CREATE TABLE IF NOT EXISTS `price_history` ( `regionID` INT NOT NULL, `ty ...