大数据之superset
1、概述
superset大数据可视化的利器,深度集成durid,结合kylin、presto完成强大的大数据可视化功能,曾用名Panoramix、caravel。相比caravel它有个比较抢眼的功能SQL lab。具体可参考官方文档
2、安装
提前在10.0.2.245服务器上面部署好redis。参考我的另一文章:http://www.cnblogs.com/cuishuai/p/8033672.html
使用docker进行安装,首先要先安装docker,采用的是centos7直接使用yum安装即可。docker安装完成后还需要安装docker-compose
#yum -y install docker docker-compose
#yum -y install git
找到最新的superset的docker:https://github.com/amancevice/superset,git clone到服务器上。
#cd /data
#git clone https://github.com/amancevice/superset
修改docker-compose.yml文件
#cat docker-compose.yml
version: '2'
services:
image: amancevice/superset
container_name: superset
volumes:
- /data/superset/conf/superset_config.py:/etc/superset/superset_config.py
ports:
- 8088:8088
注:必须要做hosts映射,因为要使用hive或presto填写地址必须使用主机名不能使用ip地址,由于pyhive0.5不支持ip,新版本已修复。utils.py很重要,主要是为了消除sql lab的timeout,
文件路径:/usr/local/lib/python3.5/dist-packages/superset/utils.py

将上述的signal注释掉,新加两个pass。这种方法把控制超时发送信号的代码注掉了,这样查询超过30s的时候就不会把进程kill掉。
默认docker是没有安装vim的修改很不方便,可以按如下步骤安装vim:
1)首先cd到docker-compose.yml的目录下启动容器:docker-compose up -d
2)进入容器:docker exec -it -u 0 superset /bin/bash
3)修改debian的源:
#cd /etc/apt/
# cat >>sources.list<< EOF
deb http://mirrors.aliyun.com/debian wheezy main contrib non-free
deb-src http://mirrors.aliyun.com/debian wheezy main contrib non-free
deb http://mirrors.aliyun.com/debian wheezy-updates main contrib non-free
deb-src http://mirrors.aliyun.com/debian wheezy-updates main contrib non-free
deb http://mirrors.aliyun.com/debian-security wheezy/updates main contrib non-free
deb-src http://mirrors.aliyun.com/debian-security wheezy/updates main contrib non-free
EOF
#apt-get update && apt-get install vim
#vim /usr/local/lib/python3.5/dist-packages/superset/utils.py
def __enter__(self):
try:
#signal.signal(signal.SIGALRM, self.handle_timeout)
#signal.alarm(self.seconds)
pass
except ValueError as e:
logging.warning("timeout can't be used in the current context")
logging.exception(e)
def __exit__(self, type, value, traceback):
try:
#signal.alarm(0)
pass
添加如上两个注释,并使用pass代替。
配置文件:
#cat superset_config.py
#---------------------------------------------------------
# Superset specific config
#---------------------------------------------------------
ROW_LIMIT = 5000
SUPERSET_WORKERS = 4
SUPERSET_WEBSERVER_TIMEOUT = 3000
SUPERSET_WEBSERVER_PORT = 8088
#---------------------------------------------------------
#---------------------------------------------------------
# Flask App Builder configuration
#---------------------------------------------------------
# Your App secret key
SECRET_KEY = '\2\1thisismyscretkey\1\2\e\y\y\h'
# The SQLAlchemy connection string to your database backend
# This connection defines the path to the database that stores your
# superset metadata (slices, connections, tables, dashboards, ...).
# Note that the connection information to connect to the datasources
# you want to explore are managed directly in the web UI
#SQLALCHEMY_DATABASE_URI = 'sqlite:////data/superset.db'
SQLALCHEMY_DATABASE_URI = 'sqlite:////home/superset/superset.db'
# Flask-WTF flag for CSRF
WTF_CSRF_ENABLED = True
# Add endpoints that need to be exempt from CSRF protection
WTF_CSRF_EXEMPT_LIST = []
# Set this API key to enable Mapbox visualizations
MAPBOX_API_KEY = ''
CACHE_DEFAULT_TIMEOUT = 60*60*6
CACHE_CONFIG = {
'CACHE_TYPE': 'redis',
'CACHE_REDIS_HOST': '10.0.2.245',
'CACHE_REDIS_PORT': '6379',
'CACHE_REDIS_URL': 'redis://10.0.2.245:6379'
}
class CeleryConfig(object):
BROKER_URL = 'redis://10.0.2.245:6379/0'
CELERY_IMPORTS = ('superset.sql_lab',)
CELERY_RESULT_BACKEND = 'redis://10.0.2.245:6379/0'
# CELERY_ANNOTATIONS = {'tasks.add':{'rate_limit':'10/s'}}
CELERY_CONFIG = CeleryConfig
from werkzeug.contrib.cache import RedisCache
RESULTS_BACKEND = RedisCache(
host='10.0.2.245', port=6379, key_prefix='superset_results')
进入到存放docker-compose.yml的目录下面:
#docker-compose up -d
#docker exec -it superset superset db upgrade
#docker exec -it superset superset load_examples
#docker exec -it superset superset-init
启动superset worker
#docker exec -it superset /bin/bash
$nohup superset worker &
默认是superset用户,如果想获取root用户权限
#docker exec -it -u 0 superset /bin/bash
3、打开浏览器访问
宿主机ip:port
http://192.168.1.100:8088
输入上面初始化设置的用户名密码
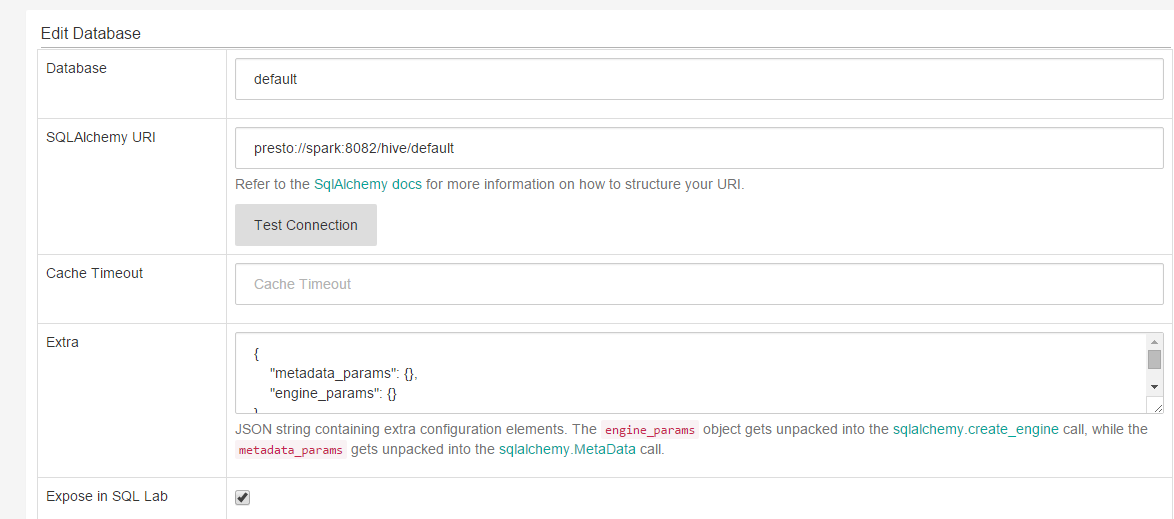
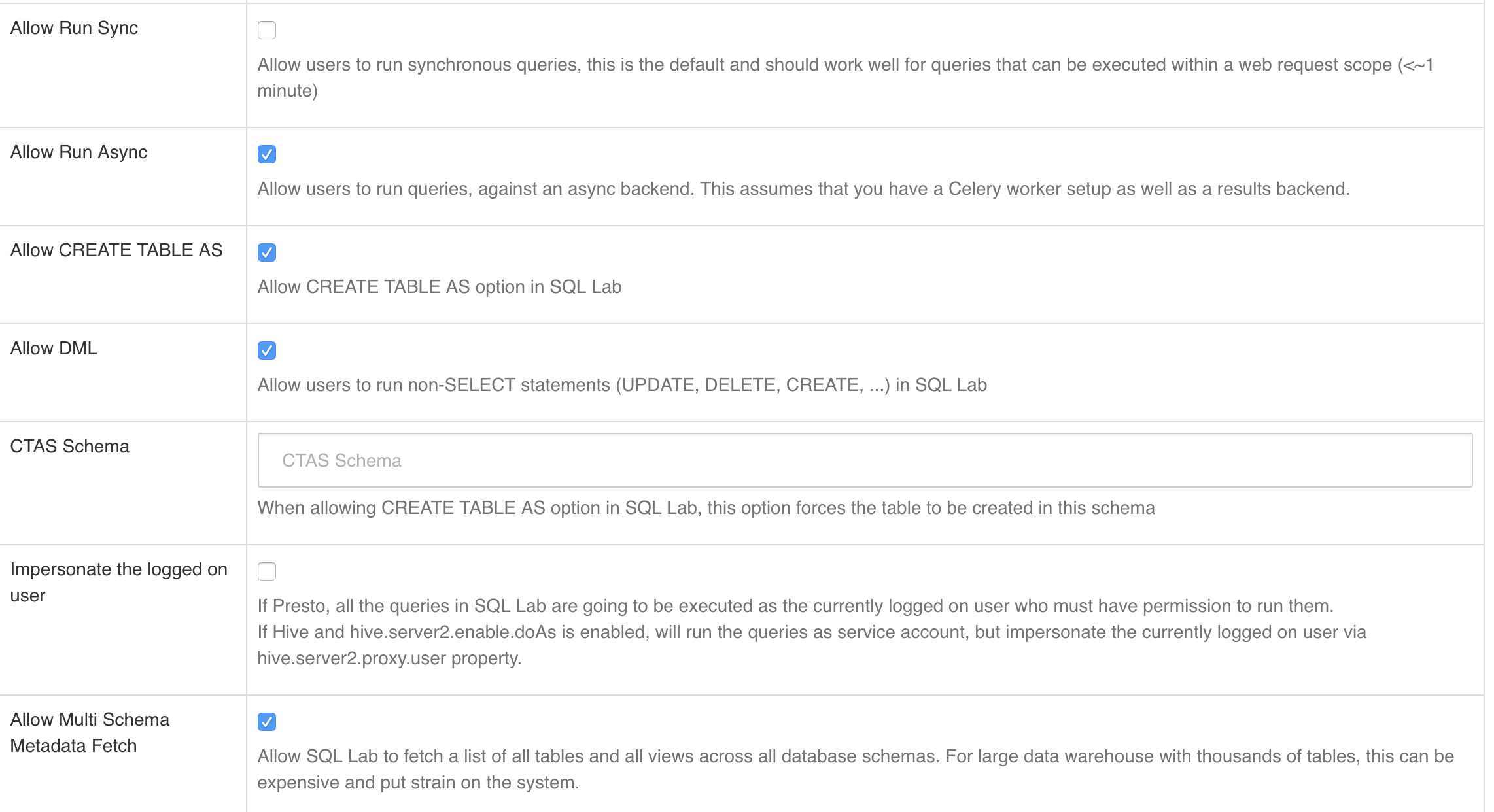
4、连接presto,spark是10.0.2.245,由于之前的老版本不支持ip,现在新版本已经修改。可以直接是用ip
大数据之superset的更多相关文章
- Echarts大数据可视化物流航向省份流向迁徙动态图,开发全解+完美参数注释
最近在研究Echarts的相关案例,毕竟现在大数据比较流行,比较了D3.js.superset等相关的图表插件,还是觉得echarts更简单上手些. 本文是以原生JS为基础,如果使用Vue.js的话, ...
- 使用Oracle Stream Analytics 21步搭建大数据实时流分析平台
概要: Oracle Stream Analytics(OSA)是企业级大数据流实时分析计算平台.它可以通过使用复杂的关联模式,扩充和机器学习算法来自动处理和分析大规模实时信息.流式传输的大数据可以源 ...
- 腾讯云EMR大数据实时OLAP分析案例解析
OLAP(On-Line Analytical Processing),是数据仓库系统的主要应用形式,帮助分析人员多角度分析数据,挖掘数据价值.本文基于QQ音乐海量大数据实时分析场景,通过QQ音乐与腾 ...
- 大数据最后一公里——2021年五大开源数据可视化BI方案对比
个人非常喜欢这种说法,最后一公里不是说目标全部达成,而是把整个路程从头到尾走了一遍. 大数据在经过前几年的野蛮生长以后,开始与数据中台的概念一同向着更实际的方向落地.有人问,数据可视化是不是等同于数据 ...
- 一篇文章看懂TPCx-BB(大数据基准测试工具)源码
TPCx-BB是大数据基准测试工具,它通过模拟零售商的30个应用场景,执行30个查询来衡量基于Hadoop的大数据系统的包括硬件和软件的性能.其中一些场景还用到了机器学习算法(聚类.线性回归等).为了 ...
- CRL快速开发框架系列教程十一(大数据分库分表解决方案)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- PayPal高级工程总监:读完这100篇论文 就能成大数据高手(附论文下载)
100 open source Big Data architecture papers for data professionals. 读完这100篇论文 就能成大数据高手 作者 白宁超 2016年 ...
- 分享MSSQL、MySql、Oracle的大数据批量导入方法及编程手法细节
1:MSSQL SQL语法篇: BULK INSERT [ database_name . [ schema_name ] . | schema_name . ] [ table_name | vie ...
- 【NLP】大数据之行,始于足下:谈谈语料库知多少
大数据之行,始于足下:谈谈语料库知多少 作者:白宁超 2016年7月20日13:47:51 摘要:大数据发展的基石就是数据量的指数增加,无论是数据挖掘.文本处理.自然语言处理还是机器模型的构建,大多都 ...
随机推荐
- 18:description方法
本小节知识点: [掌握]description基本概念 [掌握]description重写的方法 [了解]description陷阱 1.description基本概念 NSLog(@"%@ ...
- java锁的种类以及辨析(转载)
java锁的种类以及辨析(一):自旋锁 锁作为并发共享数据,保证一致性的工具,在JAVA平台有多种实现(如 synchronized 和 ReentrantLock等等 ) .这些已经写好提供的锁为我 ...
- hdu 4940 数据太水...
http://acm.hdu.edu.cn/showproblem.php?pid=4940 给出一个有向强连通图,每条边有两个值分别是破坏该边的代价和把该边建成无向边的代价(建立无向边的前提是删除该 ...
- execl 导入
/** * 导入Excel功能 是把execl表中的数据添加到数据表中 */ public function import(){ if (!empty($_FILES)) { $file = re ...
- SRM467
250pt: 一个学生等老师来上课的,但是他不知道老师啥时候会来的,然后他等waiting时间后觉得无聊就会出去转walking时间,回来等待waiting时间后老师没来就会再次出去.老师会在a... ...
- hdu 1.2.7
#include<cstdio> #include<iostream> using namespace std; int main() { //freopen("in ...
- petapoco 新手上路
PetaPoco是一个轻量级ORM框架 用法可参考http://www.toptensoftware.com/petapoco/ https://github.com/CollaboratingPl ...
- Html Agility Pack解析Html(C#爬虫利器)
有个需求要写网络爬虫,以前接触过一个叫Html Agility Pack这个解析html的库,这次又要用到,然而发现以前咋用的已经不记得了,现在从头开始记录一下使用过程. Html Agility P ...
- .net项目的mvc简单发布
基于VS2015 1. 右键要发布的项目的启动项目 2. 弹窗选择自定义,随意输入配置文件名称 3. 下一页选择FileSystem文件系统发布,同时选择将文件系统发布到本地的路径 4. 下一页,选择 ...
- 关于 kali linux
2.更新系统:首先更换一个速度快点的国内源(1) lsb_release -a先看你的版本,是Rolling还是其他什么(2) leafpad /etc/apt/sources.list(源的默认文件 ...