Solr快速入门
1. 什么是Solr
Solr是基于lucene的全文检索服务器。
不同于lucene工具包,solr是一个web应用,运行在servlet容器,屏蔽了底层细节,并对外提供服务。
Solr创建及维护索引:
solr客户端向solr服务端发送POST请求,请求内容是包含Field等信息的一个xml文档。通过该文档,solr实现对索引的维护(增删改)。
Solr的搜索:
solr客户端向solr服务端发送GET请求,solr服务器返回一个xml文档。
作为一个web应用,我们更多的工作不是编码而是配置。
2. Solr的安装与配置
解压solr压缩文件,可以看到下面几个目录
bin : 存放solr命令
contrib : solr增强功能
dist : solr编译后产生的war包和依赖包
exapmle: solr的示例,其中,example/solr->solrhome, example/solr/collection1->solrcore
slorhome是solr服务运行的主目录,一个solrhome里包含多个solrcore。
solrcore存放了solr实例运行时需要的配置文件和索引数据,每个solrcore都可以单独提供服务,多个solrcore之间没有关系。
不同的业务模块可以使用不同的solrcore来提供服务;建立solr集群的时候,必须配置多个solrcore。
`solrcore`/conf->配置文件
`solrcore`/data->solr的数据,包含索引文件和log
`solrcore`/core.properties->本solrcore对外的名字
安装配置步骤:
1. 解压war包至servlet容器,删除war包
2. 添加日志:
example/lib/ext复制到solr的WEB-INF/lib下
example/resources/log4j.properties复制到WEB-INF/classes下
3. 添加分词器:
分词器的jar包复制到solr的WEB-INF/lib下
分词器的字典,停止词,配置文件复制到WEB-INF/classes下
记得在后面配置分词器的fieldType
4. 复制example下面的solrhome(含solrcore),至自定义目录下。如果需要,复制example下面的dist和contrib,至自定义目录下
5. 修改Web.xml的<env-entry>,设置solrhome的位置
6. 配置`solrcore`/conf/solrconfig.xml
1)lib标签。如果需要,指定相关增强功能包的位置。其中solr.install.dir表示solrcore的位置,作相应修改("../"部分)
2)datadir标签。指定data的位置,其中solr.data.dir表示`solrcore`/data,不用修改
3)requestHandler标签。设置请求url和服务器索引维护(update),搜索(search)行为之间的对应关系。后面使用dataimport插件时需要设置。
<requestHandler name="/select" class="solr.SearchHandler">
<!-- 默认参数值,可以在请求URL中覆盖-->
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int> <!--默认显示数量-->
<str name="wt">json</str> <!--默认显示格式-->
<str name="df">text</str> <!--默认搜索字段-->
</lst>
</requestHandler>
7. 配置`solrcore`/conf/schema.xml
详解:
<!-- name:field的名称, 使用field必备; type:见下方fieldType,决定了是否分词; indexed:是否索引; stored:是否存储; required:该field是否必需;
multiValued: 是否存储多个值, 比如商品图片地址 -->
<!-- 索引数据库中根据需要索引字段建立各field -->
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <!-- 动态field, 用通配符指定field名称 -->
<dynamicField name="*_i" type="int" indexed="true" stored="true"/> <!-- 唯一键, 用作id的field. 该field必须已经定义且required属性为true, schema中有且仅有一个uniqueKey-->
<uniqueKey>id</uniqueKey> <!-- 复制域, source:被复制的field; dest:复制到的field. 两个field必须已经定义且dest的multiValued属性为true -->
<!-- 将多个域的信息复制到一个域里面, 目的: 方便组合查找 -->
<copyField source="cat" dest="text"/> <!-- 域的类型,自定义分词器需要配置 class:类似lucene,但没有是否索引,是否存储的信息, 该信息定义在field标签里 -->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index"> <!--建立索引时设置-->
<tokenizer class="solr.StandardTokenizerFactory"/> <!-- 建立索引时的分词器, 和搜索时分词器须相同 -->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <!--停止词过滤器-->
<filter class="solr.LowerCaseFilterFactory"/> <!--大写转小写过滤器-->
</analyzer>
<analyzer type="query"> <!--搜索时设置, 与索引时设置基本一致, 可以只设置一个 -->
<tokenizer class="solr.StandardTokenizerFactory"/> <!-- 搜索时的分词器, 和索引分词器须相同 -->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
添加dataimport插件
dataimport插件实现将sql语句的查询结果批量导入到solr索引库中, 当然该功能也可以通过下面的SolrJ实现
solr管理界面dataimport默认不可用, 以下步骤可开启:
1.添加`solrcore`/conf/solrconfig.xml的lib标签, 指定dist/solr-dataimporthandler
2.复制mysql数据库驱动包至contrib/db/lib下, 添加lib标签
3.添加`solrcore`/conf/solrconfig.xml的requestHandler标签, class:DataImportHandler, name:/dataimport, 指定sql语句配置文件data-config.xml
4.建立data-config.xml文件

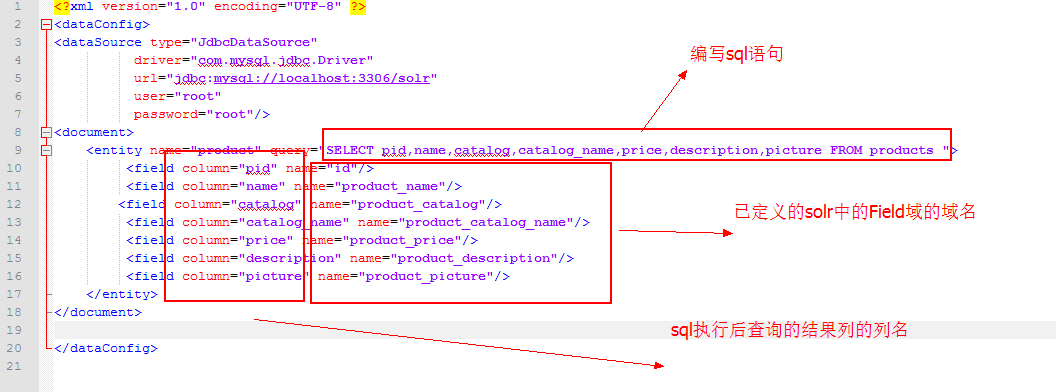
3. 通过SolrJ访问Solr
维护索引:
public class IndexManager {
@Test
public void createAndUpdateIndex() throws Exception {
// 创建Document对象
SolrInputDocument doc = new SolrInputDocument();
// field要求已经在solar服务器的配置文件中定义
doc.addField("id", "testId");
doc.addField("name", "testName");
// 创建HttpSolrServer
HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr");
// 根据唯一键查找, 没有则创建, 有则修改
server.add(doc);
// 提交
server.commit();
}
@Test
public void deleteIndex() throws Exception {
HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr");
// 根据ID删除
server.deleteById("c001");
// 根据条件删除
server.deleteByQuery("id:c001");
// 删除全部(慎用)
server.deleteByQuery("*:*");
// 提交
server.commit();
}
}
搜索:
public class IndexSearch {
@Test
public void searchSimple() throws Exception {
HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr");
// 创建SolrQuery对象
SolrQuery query = new SolrQuery();
// 查询条件
query.setQuery("product_name:玩具");
// 执行查询并接收响应
QueryResponse response = server.query(query);
// 拿到结果
SolrDocumentList queryResults = response.getResults();
// 匹配结果总数
long count = queryResults.getNumFound();
System.out.println("结果总数:" + count);
for (SolrDocument doc : queryResults) {
System.out.println(doc.get("id"));
System.out.println(doc.get("product_name"));
System.out.println(doc.get("product_catalog"));
System.out.println(doc.get("product_price"));
System.out.println(doc.get("product_picture"));
}
}
@Test
public void searchComplicate() throws Exception {
SolrQuery query = new SolrQuery();
query.set("q", "product_name:玩具");
// 设置过滤条件, 可添加多个
query.addFilterQuery("product_price:[1 TO 10]");
// 设置排序
query.setSort("product_price", ORDER.asc);
// 设置结果分页
query.setStart(0);
query.setRows(10);
// 设置结果显示的Field域集合
query.setFields("id,product_name,product_price");
// 设置默认搜索域, 查询语句中不需要"product_keywords:"了
query.set("df", "product_keywords");
// 设置某field高亮显示
query.setHighlight(true);
query.addHighlightField("product_name");
query.setHighlightSimplePre("<font style=\"color:red\">");
query.setHighlightSimplePost("</font>");
HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr");
QueryResponse response = server.query(query);
// 得到结果
SolrDocumentList queryResults = response.getResults();
long count = queryResults.getNumFound();
System.out.println("匹配结果总数:" + count);
// 得到被封装的高亮结果, 类似: 普通字段<font style="color:red">高亮字段</font>普通字段
Map<String, Map<String, List<String>>> hlResults = response.getHighlighting();
for (SolrDocument doc : queryResults) {
System.out.println(doc.get("id"));
// 解析被封装的带高亮显示的结果. 对可能的高亮field分别处理
List<String> hlLists = hlResults.get(doc.get("id")).get("product_name");
if (hlLists != null)
System.out.println("高亮显示商品名:" + hlLists.get(0));
else {
System.out.println("正常显示商品名:" + doc.get("product_name"));
}
System.out.println(doc.get("product_price"));
}
}
}
4. SolrCloud的搭建与访问
Solr集群需要用到多个solr与多个zookeeper
这里搭一个如下的简单架构作为例子
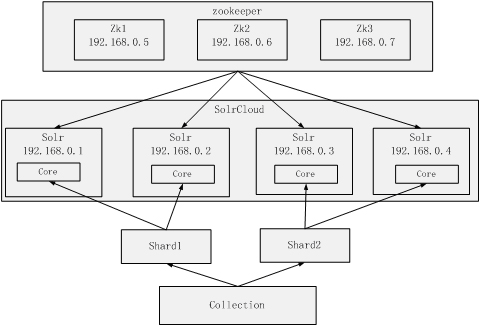
zookeeper在这个集群的作用:
1. 集群管理. 负责solr的主从关系, 负载均衡, 作为外界访问集群的入口. 为了保证高可用, zookeeper自身也必须是集群. 为使选举和投票有效, zookeeper至少需要三个节点.
2.配置文件管理. 各solr配置文件相同, 将配置文件上传给zookeeper统一管理, 每个solr节点都到zookeeper上取配置.
如果在一台主机上搭建集群, 注意避免端口冲突.
4.1 搭建zookeeper集群
1)在zookeeper01目录下创建一个data文件夹。
2)在data目录下创建一个myid的文件
3)Myid的内容为1(zookeeper02对应“2”,zookeeper03对应“3”)
4)进入conf文件, 复制zoo_sample.cfg模板文件创建zoo.cfg
5)修改zoo.cfg
把dataDir属性指定为刚创建的data文件夹
指定clientPort, 这是外界访问zookeeper01的端口
添加如下内容:
server.1=`zookeeper01的ip`:`port2`:`port3`
server.2=`zookeeper02的ip`:`port2`:`port3`
server.3=`zookeeper03的ip`:`port2`:`port3`
两个端口号分别是zookeeper间相互通信, 进行投票和选举的端口
6)zookeeper02 03以此类推
7)启动zookeeper. 使用zookeeper的bin目录下的zkServer.sh
启动:./zkServer.sh start
关闭:./zkServer.sh stop
查看服务状态:./zkServer.sh status
4.2 搭建solr集群
1)需要准备4台tomcat与4个solr实例
2)创建solrhome, 修改web.xml关联solrhome等类似单机solr
3)修改`solrhome`/solr.xml. 将solrCloud下的host, hostPort修改为所在的web容器访问地址与端口号
4)使用solr-4.10.3/example/scripts/cloud-scripts/zkcli.sh命令将某台的`solrcore`/conf目录上传到zookeeper集群
./zkcli.sh -zkhost `zookeeper01的ip`:`port1`,zookeeper02的ip`:`port1`,zookeeper03的ip`:`port1` -cmd upconfig -confdir `solrcore`/conf -confname myconf
查看是否上传成功, 使用zookeeper的zkCli.sh命令
5)通知solr实例zookeeper的位置。修改tomcat的catalina.sh添加
JAVA_OPTS="-DzkHost=`zookeeper01的ip`:`port1`,zookeeper02的ip`:`port1`,zookeeper03的ip`:`port1`"
6)启动solr实例, 访问如下url进行分片, 分为2片, 每片一主一从
分片, 创建solrcore collection2:
http://某solr的ip:port/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2
可以删除不用的solrcore collection1
http://某solr的ip:port/solr/admin/collections?action=DELETE&name=collection1
4.3 使用SolrJ访问集群
public class IndexManager {
@Test
public void createAndUpdateIndex() throws Exception {
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "testId");
document.addField("item_title", "testName");
// 创建一个SolrServer对象, zkHost地址为三个zookeeper地址
CloudSolrServer solrServer = new CloudSolrServer("192.168.25.154:2181,192.168.25.154:2182,192.168.25.154:2183");
// 设置使用的solrcore(分片策略)
solrServer.setDefaultCollection("collection2");
solrServer.add(document);
solrServer.commit();
}
}
可以看出除了获取solrServer, 使用上和单机版没有任何区别. 集群对客户端来说的封闭的.
Solr快速入门的更多相关文章
- 【solr专题之一】Solr快速入门
一.Solr学习相关资料 1.官方材料 (1)快速入门:http://lucene.apache.org/solr/4_9_0/tutorial.html,以自带的example项目快速介绍发Solr ...
- Solr快速入门(一)
概述 本文档介绍了如何获取和运行Solr,将各种数据源收集到多个集合中,以及了解Solr管理和搜索界面. 首先解压缩Solr版本并将工作目录更改为安装Solr的子目录.请注意,基本目录名称可能随Sol ...
- 【solr专题之一】Solr快速入门 分类: H4_SOLR/LUCENCE 2014-07-02 14:59 2403人阅读 评论(0) 收藏
一.Solr学习相关资料 1.官方材料 (1)快速入门:http://lucene.apache.org/solr/4_9_0/tutorial.html,以自带的example项目快速介绍发Solr ...
- Spring Data Solr —— 快速入门
Solr是基于Lucene(全文检索引擎)开发,它是一个独立系统,运行在Tomcat或Jetty(solr6以上集成了jetty,无需再部署到servlet容器上),但其原生中文的分词词功能不行,需要 ...
- Nutch 快速入门(Nutch 2.2.1+Hbase+Solr)
http://www.tuicool.com/articles/VfEFjm Nutch 2.x 与 Nutch 1.x 相比,剥离出了存储层,放到了gora中,可以使用多种数据库,例如HBase, ...
- 1.搜索引擎的历史,搜索引擎起步,发展,繁荣,搜索引擎的原理,搜索技术用途,信息检索过程,倒排索引,什么是Lucene,Lucene快速入门
一: 1 搜索引擎的历史 萌芽:Archie.Gopher Archie:搜索FTP服务器上的文件 Gopher:索引网页 2 起步:Robot(网络机器人)的出现与spider(网络爬虫) ...
- elasticsearch系列二:索引详解(快速入门、索引管理、映射详解、索引别名)
一.快速入门 1. 查看集群的健康状况 http://localhost:9200/_cat http://localhost:9200/_cat/health?v 说明:v是用来要求在结果中返回表头 ...
- 大数据技术之_09_Flume学习_Flume概述+Flume快速入门+Flume企业开发案例+Flume监控之Ganglia+Flume高级之自定义MySQLSource+Flume企业真实面试题(重点)
第1章 Flume概述1.1 Flume定义1.2 Flume组成架构1.2.1 Agent1.2.2 Source1.2.3 Channel1.2.4 Sink1.2.5 Event1.3 Flum ...
- Lucene7.2.1系列(一)快速入门
系列文章: Lucene系列(一)快速入门 Lucene系列(二)luke使用及索引文档的基本操作 Lucene系列(三)查询及高亮 Lucene是什么? Lucene在维基百科的定义 Lucene是 ...
随机推荐
- 汇编学习笔记(AT&T语法)
一个最基本的汇编程序如下所示: .section .data .section .text .globl _start _start: movl $, %eax # the number 1 is t ...
- django一些配置与ORM
- Vue(1)- es6的语法、vue的基本语法、vue应用示例,vue基础语法
一.es6的语法 1.let与var的区别 ES6 新增了let命令,用来声明变量.它的用法类似于var(ES5),但是所声明的变量,只在let命令所在的代码块内有效.如下代码: { let a = ...
- RT-Thread内核之线程调度(三)
4.RT-Thread中的线程? /** * 线程结构 */ struct rt_thread { /** Object对象 */ char name[RT_NAME ...
- maven项目乱码以及项目名出现红叉
中文乱码 出现中文乱码的时候可以看一下maven项目里面的pom.xml是不是设置了UTF-8,如果设置了UTF-8,只需将UTF-8去掉就好.因为默认的是GBK国际编码,UTF-8是中文编码,自己建 ...
- datetime时间处理
基本数据获取: In [38]: import datetime as dt In [39]: on = dt.datetime.now() #获取当前准确时间 In [40]: on Out[40] ...
- SHELL —— BASH环境
一 .什么是SHELL shell一般代表两个层面的意思,一个是命令解释器,比如BASH,另外一个就是shell脚本.本节我们站在命令解释器的角度来阐述shell 二 .命令的优先级 命令分为: == ...
- WinForm下的Nhibernate+Spring.Net的框架配置文件
1.先将配置文件放到如下:<?xml version="1.0" encoding="utf-8"?> <configuration> ...
- maven自动化构建deploy
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/20 ...
- HDFS 详解
HDFS 概述 基于2.7.3 HDFS 优点: 1.高容错性 数据自动保存多个副本,默认是三个副本 副本丢失后,会自动恢复 2.适合批处理 移动计算而非移动数据,批处理的时候,数据量很大,移动数据是 ...