Hamming code
Also known as (7,4) code,7 trainsmitted bits for 4 source code.
TRANSMIT
The transmitted procedure can be reprecented as follows.
$t=G^Ts$
where G is:
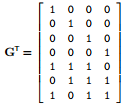
import numpy as np
G = np.matrix(
[[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1],
[1,1,1,0],
[0,1,1,1],
[1,0,1,1]]).T
s=np.matrix([[1,1,1,0]]).T t = (G.T*s)%2
visualization
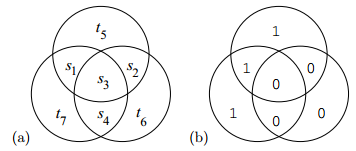
$t_5,t_6,t_7$ is called parity-check bits
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
DECODING
1.intuitive way: measure the similarity between the recieved bits $r$ and the encoded codes $t$
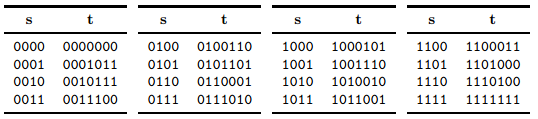
2.Syndrome decoding
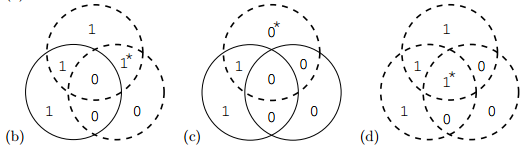
dashed line for which parity is not even(unhappy)
full line for which parity is even(happy)
find the unique bit,that lies inside all unhappy circles and outside all happy circles
the corresponding syndrome z as follow:
(b) 110 ($t_5$ not even,$t_6$ not even,$t_7$ even),$r_2$ should be unflipped
(c) 100 ($t_5$ not even,$t_6$ even,$t_7$ even),$r_5$ should be unflipped
(d) 111 ($t_5$ not even,$t_6$ not even,$t_7$ not even),$r_3$ should be unflipped
all the situations is listed in table below:

the syndrome z can be achieved by matrix:
$z=Hr$
which H is:
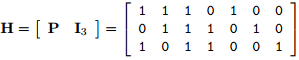
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
PERFORMANCE
1.when there is only one bit flipped in all 7 bits,the decoder can always get right
2.when there are more than one bits flippend,the decoder get wrong
the single bit error rate,can be estimate as follow:
$p_b \approx \frac{1-{(1-f)}^2-7{(1-f)}^6f}{2}$
the exact error rate is about 0.6688,which can be computed with following program.
import numpy as np
import copy
import itertools
from scipy.misc import comb def encode(s):
G = np.array(
[[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1],
[1,1,1,0],
[0,1,1,1],
[1,0,1,1]]
) return np.dot(G,s)%2 def decode(r):
t_hat = copy.deepcopy(r)
H = np.array(
[[1,1,1,0,1,0,0],
[0,1,1,1,0,1,0],
[1,0,1,1,0,0,1]]
) syndrome_map = {0:-1,
1:6,
10:5,
11:3,
100:4,
101:0,
110:1,
111:2} syndrome = np.dot(np.dot(H,r)%2,np.array([100,10,1]))
if syndrome_map[syndrome]>=0:
t_hat[syndrome_map[syndrome]] = (t_hat[syndrome_map[syndrome]]+1)%2 return t_hat def flipn(flip_list,t):
'''
flipped the bits specified by flip_list and return it
:param flip_list:
:param t:
:return:
'''
r = copy.deepcopy(t)
for flip in flip_list:
r[flip] = (r[flip]+1)%2
return r def flipn_avg_err(n,s):
'''
get the average error bits when flip n bits
:param n:
:param s:
:return:
'''
t = encode(s)
items = range(7)
errors = 0
count = 0
for flip in itertools.combinations(items,n):
r = flipn(list(flip),t)
t_hat = decode(r) errors += 4-sum(s==t_hat[:4])
count += 1
return errors*1.0/count f = 0.9
s = np.array([0,0,0,0])
all_error = 0.0
for n in range(2,8):
error = flipn_avg_err(n,s)
all_error += error*comb(7,n)*(f**(7-n))*((1-f)**n)
print all_error/4
python
Hamming code的更多相关文章
- URAL 1792. Hamming Code (枚举)
1792. Hamming Code Time limit: 1.0 second Memory limit: 64 MB Let us consider four disks intersectin ...
- 汉明码(Hamming Code)原理及实现
汉明码实现原理 汉明码(Hamming Code)是广泛用于内存和磁盘纠错的编码.汉明码不仅可以用来检测转移数据时发生的错误,还可以用来修正错误.(要注意的是,汉明码只能发现和修正一位错误,对于两位或 ...
- 汉明码(hamming code)
hamming code用于磁盘RAID 2中, 关于汉明码的讲解可以看这篇博文,介绍的很详细.最重要是最后的结论: 汉明码属于分组奇偶校验,P4P2P1=000,说明接收方生成的校验位和收到的校验位 ...
- 汉明码、海明校验码(Hamming Code)
目录 基础知识 汉明码/海明校验码 计算 基础知识 码距:又叫海明距离,是在信息编码中,两个编码之间对应位上编码不同的位数.例如编码100110和010101,第1.2.5.6位都不相同,所以这两个编 ...
- Google Interview University - 坚持完成这套学习手册,你就可以去 Google 面试了
作者:Glowin链接:https://zhuanlan.zhihu.com/p/22881223来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 原文地址:Google ...
- 什么是RAID
RAID 维基百科,自由的百科全书 关于与「 RAID 」同名的其他主题,详见「 RAID (消歧义) 」. 独立硬盘冗余阵列 ( RAID , R edundant A rray of I ndep ...
- 关于硬盘和几种RAID
1 硬盘的基本工作原理 1.1 硬盘部件结构图 1.2 主要参数术语解释 磁头:在与硬盘交换数据的过程 中,读操作远远快于写操作,硬盘厂商开发一种读/写分离磁头. 转速(Rotationl Speed ...
- ECC校验优化之路
引子: 今天上嵌入式课程时,老师讲到Linux的文件系统,讲的重点是Linux中对于nand flash的ECC校验和纠错.上课很认真地听完,确实叹服代码作者的水平. 晚上特地下载了Linux最新的内 ...
- 独立硬盘冗余阵列与HDFS
http://zh.wikipedia.org/wiki/RAID 独立硬盘冗余阵列(RAID, Redundant Array of Independent Disks),旧称廉价磁盘冗余阵列(Re ...
随机推荐
- poj 3111 K Best (二分搜索之最大化平均值之01分数规划)
Description Demy has n jewels. Each of her jewels has some value vi and weight wi. Since her husband ...
- 从手工测试逆袭为NB自动化测试的学习路线
在开始之前先学习两个工具商业web自动化测试工具请学习QTP:QTP的学习可以跳过,我是跳过了的.开源web自动化测试工具请学习Selenium:我当年是先学watir,再学selenium 这里主要 ...
- Dalvik虚拟机JNI方法的注册过程分析
文章转载至CSDN社区罗升阳的安卓之旅,原文地址:http://blog.csdn.net/luoshengyang/article/details/8923483 在前面一文中,我们分析了Dalvi ...
- SlipButton——滑动开关
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMjI1MjUwMg==/font/5a6L5L2T/fontsize/400/fill/I0JBQk ...
- css1-颜色和长度
<!DOCTYPE html>CSS1-颜色和长度 <style>div{ /*颜色*/ color:#f00; /*前景色*/ background:#00f; /*背景色* ...
- MVC 错误处理1
实例1. /// <summary> /// 错误处理 /// 404 处理 /// </summary> protected void Application_Error(o ...
- Android Studio稍微较新的版本下载
ALL ANDROID STUDIO PACKAGES-V1.4.1.2422023 Select a specific Android Studio package for your platfor ...
- C#验证类 可验证:邮箱,电话,手机,数字,英文,日期,身份证,邮编,网址,IP (转)
namespace YongFa365.Validator { using System; using System.Text.RegularExpressions; /**//// <summ ...
- Javascript中String、Array常用方法介绍
string和array作为javascript内置对象,其中许多方法无论是在开发过程中,还是在面试的时候都有机会被面试官问到,这里对经常用到的方法做一个介绍,这些方法都有过很多的实际应用场景,所以对 ...
- xyiyy开始写博客了
拖延症一直到现在才开始写博客... 希望写的博客对大家能有一些帮助,有不恰当或者不对的地方,还望大家指出. 以下为我的两个昵称:fraud xyiyy