【Hadoop】大数据时代,我们为什么使用hadoop
博客已转移,请借一步说话。http://www.daniubiji.cn/archives/538
我们先来看看大数据时代,
什么叫大数据,“大”,说的并不仅是数据的“多”!不能用数据到了多少TB ,多少PB 来说。
对于大数据,可以用四个词来表示:大量,多样,实时,不确定。
也就是数据的量庞大,数据的种类繁杂多样话,数据的变化飞快,数据的真假存疑。
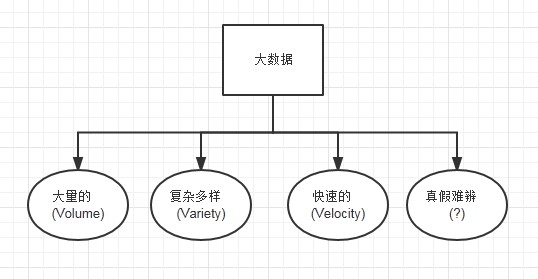
大量:这个大家都知道,想百度,淘宝,腾讯,Facebook,Twitter等网站上的一些信息,这肯定算是大数据了,都要存储下来。
多样:数据的多样性,是说数据可能是结构型的数据,也可能是非结构行的文本,图片,视频,语音,日志,邮件等。
实时:大数据需要快速的,实时的进行处理。如果说对时间要求低,那弄几个机器,对小数据进行处理,等个十天半月的出来结果,这样也没有什么意义了。
不确定: 数据是存在真伪的,各种各样的数据,有的有用,有的没用。很难辨析。
根据以上的特点,我们需要一个东西,来:
1存储大量数据
2快速的处理大量数据
3从大量数据中进行分析
于是就有了这样一个模型hadoop。
hadoop的历史就不说了。先来看看模型。

这就相当于一个生态系统,或者可以看成一个操作系统XP,win7.
HDFS和MapReduce为操作系统的核心,Hive,Pig,Mathout,Zookeeper,Flume,Sqoop,HBase等,都是操作系统上的一些软件,或应用。
HDFS:(Hadoop Distributed File System),Hadoop分布式文件系统。从名字上就看出了它的两点功能。
基本功能,存文件,是一个文件系统;另外这个文件系统是分布式的;
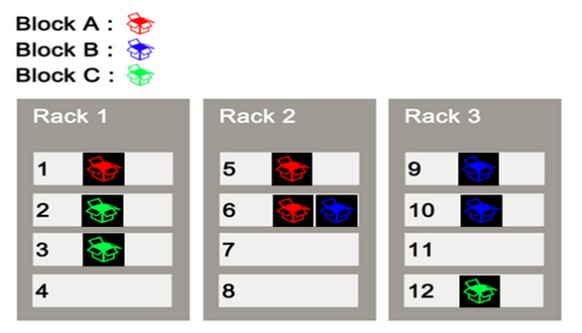
从图上来看,HDFS的简单原理。
Rack1,Rack2,Rack3是三个机架;
1,2,3,4,5,6,7,8,9,10,11,12 是机架上的十二台服务器。
Block A, Block B, Block C为三个信息块,也就是要存的数据。
从整体布局上来看,信息块被分配到机架上。看似很均匀。这样分配的目的,就是备份,防止某一个机器宕机后,单点故障的发生。
MapReduce,(Map + Reduce),就看成是计算的功能。可以对数据进行处理。
它加快了计算。主要也是通过上图的布局。将数据分布到多个服务器上。当有任务了,比如查询,或者比较大小,先让每台服务器,都处理自己的存储中文件。然后再将所有服务器的处理结果进行第二次处理。最后将结果返回。
其实,hadoop还有一点好处,就是省钱。
框架开源的,免费的,服务器也不用特别牛X的。
省钱才是硬道理。
另外,从别的资料看到一种解释mapreduce的方式,很简单
Goal: count the number of books in the library.
Map: You count up shelf #1, I count up shelf #2.
(The more people we get, the faster this part goes. )
Reduce: We all get together and add up our individual counts.
【Hadoop】大数据时代,我们为什么使用hadoop的更多相关文章
- 数据仓库和Hadoop大数据平台有什么差别?
广义上来说,Hadoop大数据平台也可以看做是新一代的数据仓库系统, 它也具有很多现代数据仓库的特征,也被企业所广泛使用.因为MPP架构的可扩展性,基于MPP的数据仓库系统有时候也被划分到大数据平台类 ...
- 大数据时代快速SQL引擎-Impala
背景 随着大数据时代的到来,Hadoop在过去几年以接近统治性的方式包揽的ETL和数据分析查询的工作,大家也无意间的想往大数据方向靠拢,即使每天数据也就几十.几百M也要放到Hadoop上作分析,只会适 ...
- 转:大数据时代快速SQL引擎-Impala
本文来自:http://blog.csdn.net/yu616568/article/details/52431835 如有侵权 可立即删除 背景 随着大数据时代的到来,Hadoop在过去几年以接近统 ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- 大数据时代,我们为什么使用hadoop
大数据时代,我们为什么使用hadoop 我们先来看看大数据时代, 什么叫大数据,“大”,说的并不仅是数据的“多”!不能用数据到了多少TB ,多少PB 来说. 对于大数据,可以用四个词来表示:大量,多样 ...
- 大数据项目实践:基于hadoop+spark+mongodb+mysql+c#开发医院临床知识库系统
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- 【大数据】Summingbird(Storm + Hadoop)的demo运行
一.前言 为了运行summingbird demo,笔者走了很多的弯路,并且在国内基本上是查阅不到任何的资料,耗时很久才搞定了demo的运行.真的是一把辛酸泪,有兴趣想要研究summingbird的园 ...
- hadoop大数据技术架构详解
大数据的时代已经来了,信息的爆炸式增长使得越来越多的行业面临这大量数据需要存储和分析的挑战.Hadoop作为一个开源的分布式并行处理平台,以其高拓展.高效率.高可靠等优点越来越受到欢迎.这同时也带动了 ...
- 大数据框架:Spark vs Hadoop vs Storm
大数据时代,TB级甚至PB级数据已经超过单机尺度的数据处理,分布式处理系统应运而生. 知识预热 「专治不明觉厉」之“大数据”: 大数据生态圈及其技术栈: 关于大数据的四大特征(4V) 海量的数据规模( ...
随机推荐
- 对IT行业的一些思考
阅读完两篇报道,从“2014年十大最热门行业和职业排行榜”可以看出最热门的行业是IT行业,可以看出IT行业在未来的发展前景很乐观,选择IT行业的人也会越来越多,IT行业也会越来越庞大.但是 ...
- win7仿win98电脑主题
http://ys-d.ys168.com/599631823/S7hMfgo3M382J764IOJ8/plus98_for_windows_7_by_ansonsterling.zip
- shell 一些符号的使用
给你个全的,你在Linux环境下多试下就明白了:$0 这个程式的执行名字$n 这个程式的第n个参数值,n=1..9$* 这个程式的所有参数,此选项参数可超过9个.$# 这个程式的参数个数$$ 这个程式 ...
- PHP面向对象之抽象类,抽象方法
抽象类,抽象方法 抽象类: 是一个不能实例化的类: 定义形式: abstract class 类名{} 为什么需要抽象类: 它是为了技术管理而设计! 抽象方法: 是一个只有方法头,没有方法体的方法 ...
- 教你配置使用阿里云 Maven 库,体验秒下 jar 包的快感
鉴于国内的网络环境,从默认 Maven 库下载 jar 包是非常的痛苦. 速度慢就不说了,还经常是下不下来,然后一运行就是各种 ClassNotFoundException,然后你得找到残留文件删掉重 ...
- Vue.js 判断对象属性是否存,不存在添加
Vue.set是可以对对象添加属性的,这里item对象添加一个checked属性 //if(typeof item.checked=='undefined'){if(!this.item.checke ...
- ZOJ1827_The Game of 31
这是一个比较经典的博弈题目,今年网赛好像是南京赛上有一个类似的题目. 这种题目是没有一定公式或者函数的,需要自己dp或者搜索解决. 题意为分别给你4张写有1,2,3,4,5,6的卡片共24张,每次轮流 ...
- java map的 keyset()方法
- Probability|Given UVA - 11181(条件概率)
题目大意:n个人去购物,要求只有r个人买东西.给你n个人每个人买东西的概率,然后要你求出这n个人中有r个人购物并且其中一个人是ni的概率pi. 类似于5个人中 抽出三个人 其中甲是这三个人中的一个的 ...
- Qt的编程风格与规范
Qt的编程风格与规范 来源: http://blog.csdn.net/qq_35488967/article/details/70055490 参考资料: https://wiki.qt.io/Qt ...