27 mysql主从出现错误
大多数的互联网应用场景都是读多写少,在发展过程中可能会出现读性能问题,在数据库层解决读性能问题:一主多从
下面是多主从结构
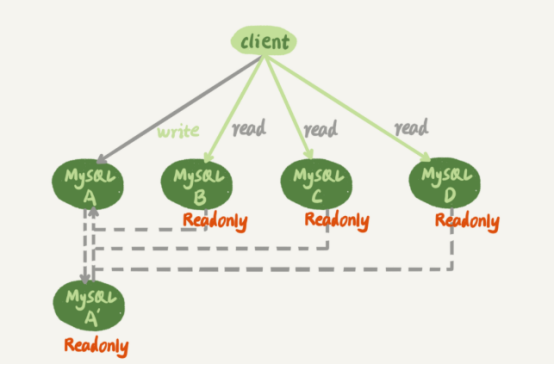
虚线箭头表示主备关系,A与A’互为主备,从库B,C,D指向主库A,一主多从的设置,一般用于读写分离,主库复制所有的写入和一部分读,其他的读有从库分担。
在一主多从架构下,主库故障后的主备切换
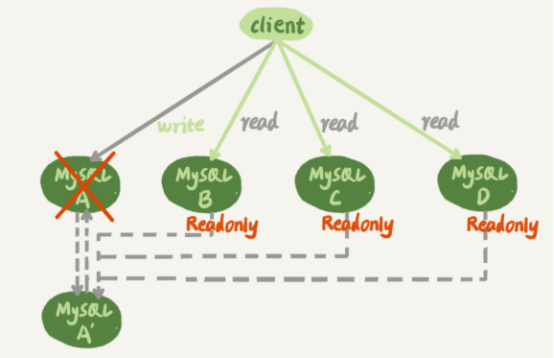
相比一主一从的切换,一主多从结构在切换完成后,A’会成为新的主库,从库B,C,D也要改接到A’,正是由于多了B,C,D重新指向的这个过程,所以这个主备切换的过程复杂度就增加了。
基于位点的主备切换
当我们把节点B设置节点A’的从库的时候,需要执行change master
CHANGE MASTER TO
MASTER_HOST=$host_name
MASTER_PORT=$port
MASTER_USER=$user_name
MASTER_PASSWORD=$password
MASTER_LOG_FILE=$master_log_name
MASTER_LOG_POS=$master_log_pos
前面的4个参数很容易确定,后面2个参数MASTER_LOG_FILE,MASTER_LOG_POS,要从主库的master文件和位点继续同步
那么这2个参数怎么确定呢
原来节点B是A的从库,本地记录的是A的位点,但是相同的日志,在A和A’上是不同的,因此,从库B切换过来的时候,先找到同步位点。
考虑切换过程中不能丢数据,所以我们找位点的时候,总是要找一个”稍微往前”的,然后再通过判断跳过那些在从库B上已经执行过的事务
一种方法:
1 等待新主库A’把中转日志(relay log)全部同步完成
2 在A’上执行show master status命令,得到当前A’上最新的file和position
3 取原主库A故障的时刻T
4 用mysqlbinlog解析A’的file,得到T时刻的位点。
mysqlbinlog File --stop-datetime=T --start-datetime=T
比如
# at 1881
#190109 15:22:37 server id 2018091901 end_log_pos 1928 CRC32 0x474e37c1 Rotate to mysql-bin.000023 pos: 4
DELIMITER ;
# End of log file
上面end_log_pos后面的是1928,表示的是A’这个实例,在T时刻写入的binlog的位置,然后,我们把这个1928值作为$master_log_pos,用在节点B的change master
然后这个值并不精确,为什么呢
可以设想有这么一种情况,加上在T这个时候,主库A已经执行完成了一个insert语句插入了R行数据,并且已经将binlog传给了A’和B,然后在传完的瞬间主库A就掉电了,那么,这时候系统的状态时这样的。
1 在从库B上,由于binlog同步了,R这一行数据已经存在
2 在新主库A’上,R这一行也已经存在,日志是写在1928这个位置之后的
3 我们在从库B上执行change master,执行A’的file文件的1928这个位置,就会把插入这一行数据的binlog又同步到B库
同步线程就会报错 主键重复
遇到这种情况,要先主动跳过错误
set global sql_slave_skip_counter=1;
start slave;
因为在切换过程中, 可能会不止重复执行一个事务,要在从库B开始接收到新主库时,观察,遇到错误就停下来,执行一次跳过命令,直到不出现错误
另外一种方式,设置slave_skip_errors参数,直接跳过指定的错误:
1062 错误插入数据时唯一冲突
1032 错误是删除数据时找不到行
因此可以把slave_skip_errors=’1032,1062’,这样中间遇到这个的错误时就直接跳过
这种直接跳过指定错误的方法,针对的是主备切换时,由于找不到精确的同步位点,所以只能采用这种方法来创建从库和新主库的主备关系
等完成了主备关系,并稳定执行一段时间,把该参数设置为null,以免以后真正的出现主备不一致。
GTID
5.6版本,引入了gtid,解决了上面主备切换,找位点困难的问题
GTID:global transaction identifiler,全局事务id,是一个事务在提交的时候生成的,是这个事务的唯一标识,格式:
GTID=server_uuid:gno
其中,server_uuid是一个实例第一次启动时自动生成的,是一个全局唯一的值
gno是一个整数,初始值是1,每次提交事务的时候分配给这个事务,并加1
Mysql官方的定义
GTID=source_id:transaction_id
这里的source_id就是uuid,
Mysql里说的transaction_id是指事务id,事务id是在事务执行过程中分配的,如果这个事务回滚了,这个事务id也会递增,而gno是在事务提交的时候才会分配。
从效果上看,gtid往往是连续的,因此用gno来表示更容易理解
GTID启动比较简单,只需要在mysql实例启动时候加参数gtid_mode=on和enforce_gtid_consistency=0
在gtid模式下,每个事务都会跟一个gtid一一对应,这个gtid有两种方式
1 如果gtid_next=automatic,代表使用默认值,这时,mysql就会把server_uuid:gno分配给这个事务
- 记录binlog的时候,先记录一行 SET @@SESSION.GTID_NEXT=’server_uuid:gno’
- 把这个gtid加入本实例的gtid集合
2 如果gtid_next是一个指定的gtid值,比如通过set gtid_next=’current_gtid’指定为current_gtid,那么有两种可能
A 如果current_gtid已经存在于实例的gtid集合,接下来执行的这个事务会直接被忽略
B 如果current_gitd没有存在于实例的gtid集合中,就将这个current_gtid分配给接下来要执行的事务,也就说系统不需要给这个事务生成新的gtid,因此gno也不用加1
注意,一个current_gtid只能给一个事务使用,这个事务提交后,如果是要执行下一个事务,就要执行set命令,把gtid_next设置成另外一个gtid或者automatic
这样,每个mysql实例都维护了一个gtid集合,用来对应这个实例执行过的所有事务
在gtid模式下,出现主键冲突,就要跳过错误
stop slave;
set gtid_next='aaaaaaaa-cccc-dddd-eeee-ffffffffffff:10';
begin;
commit;
set gtid_next=automatic;
start slave;
其中,前三条语句的作用,是通过提交一个空事务,把这个gtid加到实例的gtid的集合中,
再执行start slave命令让同步线程执行起来的时候,实例会继续执行主库传来的事务,但是由于'aaaaaaaa-cccc-dddd-eeee-ffffffffffff:10'已经存在于实例的gtid集合中,所以实例就会直接跳过这个事务,也就不会再出现主键冲突的错误。
在上面的语句中,set gtid_next=automatic的作用是恢复gtid的默认分配行为,也就是说如果之后有新的事务在执行,就还是按照原来的分配方式继续执行。
基于GTID的主备切换
现在已经理解了gtid的概念,在看看基于gtid的主备复制用法
在gtid模式下,备库B要设置为新主库A’的从库的语法
CHANGE MASTER TO
MASTER_HOST=$host_name
MASTER_PORT=$port
MASTER_USER=$user_name
MASTER_PASSWORD=$password
master_auto_position=1
其中,master_auto_position=1 就表示这个主备关系是使用gtid协议,已经不需要上面的file和position位点了。
我们把现在这个时刻,实例A’的gtid集合记为set_a,实例B的gtid集合记为set_b,看主备切换的逻辑
在实例B上执行start slave命令,取binlog的逻辑:
1 实例B指定主库A’,基于主备协议建立连接
2 实例B把set_b发给主库A’
3 实例A’算出set_a与set_b的差集,也就是所有存在于set_a,但是不存在于set_b的gtid的集合,判断A’本地是否包含了这个差集需要的所有binlog事务
如果不包含,表示A’已经把实例B需要的binlog给删掉了,直接返回错误
如果确认全部包含,A’从自己的binlog文件里面,找出第一个不在set_b的事务,发给B.
4 之后就从这个事务开始,往后读文件,按顺序取binlog发给B去执行。
其实,这个逻辑里面包含了一个设计思想:在基于gtid的主备关系里,系统认为只要建立主备关系,就必须保证主库发给备库的日志是完整的。因此,如果实例B需要的日志已经不存在,A’就拒绝把日本发给B。
这跟基于位点的主备协议不同。基于位点的协议,是由备库决定的,备库指定哪个位点,主库就发哪个位点,不做日志的完整性判断。
基于上面的介绍,从库B,C,D只需要分别执行change master命令 执行实例A’就可以。
其实,严谨地说,主备切换不是不需要找点位了,而是找点位这个工作,在实例A’内部就已经完成,由于这个工作是自动的,所以对HA系统的开发人员来说,非常友好。
之后这个系统就有新主库A’写入,主库A’的自己生成的binlog中的gtid集合格式:server_uuid_of_A’:1-M
如果之前从库B的gtid集合格式是server_uuid_of_A:1-N,那么切换之后就变成了server_uuid_of_A:1-N,server_uuid_of_A’:1-M
GTID和在线DDL
假设,在互为主备的实例X和实例Y,且当前主库是X,并且都打开了gtid模式,这时的主备切换流程可以变成这样:
在实例X上stop slave
在实例Y上执行DDL,这里不需要关闭binlog
执行完成后,查出这个DDL语句对应的gtid,并记为server_uuid_of_Y:gno
到实例X 上执行以下语句序列
set GTID_NEXT="server_uuid_of_Y:gno";
begin;
commit;
set gtid_next=automatic;
start slave;
这样做的目的在于既可以当实例Y的更新有binlog记录,同时也可以确保不会在实例X上执行这个更新条目。
27 mysql主从出现错误的更多相关文章
- MySQL主从失败 错误Got fatal error 1236解决方法
--MySQL主从失败 错误Got fatal error 1236解决方法 ----------------------------------------------------2014/05/1 ...
- mysql主从数据库错误处理
方法一:忽略错误后,继续同步 该方法适用于主从库数据相差不大,或者要求数据可以不完全统一的情况,数据要求不严格的情况 解决: stop slave; #表示跳过一步错误,后面的数字可变set glob ...
- mysql主从 1050错误
在mysql从库上查询时出现如下错误 ...................... Last_Errno: 1050 Last_Error: Error 'Tab ...
- mysql 主从错误以及监控
同步中的常见的错误和处理 1.现象:在从库上面show slave status\G;出现下列情况, Slave_IO_Running: Yes Slave_S ...
- mysql 主从错误情况与原因
mysql 主从错误情况1,master 上删除一条记录是从库报错 找不到该记录引起原因:master出现宕机或者从库已经删除.解决方案:stop slave;set global sql_slave ...
- mysql主从同步原理及错误解决
mysql主从同步的原理: 1.在master上开启bin-log日志功能,记录更新.插入.删除的语句. 2.必须开启三个线程,主上开启io线程,从上开启io线程和sql线程. 3.从上io线程去连接 ...
- 学一点 mysql 双机异地热备份----快速理解mysql主从,主主备份原理及实践
双机热备的概念简单说一下,就是要保持两个数据库的状态 自动同步.对任何一个数据库的操作都自动应用到另外一个数据库,始终保持两个数据库数据一致. 这样做的好处多. 1. 可以做灾备,其中一个坏了可以切换 ...
- mysql主从同步(4)-Slave延迟状态监控
mysql主从同步(4)-Slave延迟状态监控 转自:http://www.cnblogs.com/kevingrace/p/5685511.html 之前部署了mysql主从同步环境(Mysql ...
- mysql主从同步(3)-percona-toolkit工具(数据一致性监测、延迟监控)使用梳理
转自:http://www.cnblogs.com/kevingrace/p/6261091.html 在mysql工作中接触最多的就是mysql replication mysql在复制方面还是会有 ...
随机推荐
- Android学习笔记①——安卓工具的基本安装
安卓已经出来很长时间了,网上的教程也有很多,怕以后忘记,就把网上大牛们的分享的知识自己在学习一下,也记录一下,如果能帮到别人,那是更好不过的! 鉴于现在的IDE工具来说,IDEA已经占据了java的半 ...
- jquery表单验证插件 jquery.form.js-转
来自:http://www.cnblogs.com/luluping/archive/2009/04/15/1436177.html Form插件,支持Ajax,支持Ajax文件上传,功能强大,基本满 ...
- 访问IO设备
http://blog.csdn.net/goodluckwhh/article/details/16986871 内存屏障主要解决的问题是编译器的优化和CPU的乱序执行.编译器在优化的时候,生成的汇 ...
- CUDA Samples: Dot Product
以下CUDA sample是分别用C++和CUDA实现的两个非常大的向量实现点积操作,并对其中使用到的CUDA函数进行了解说,各个文件内容如下: common.hpp: #ifndef FBC_CUD ...
- ng开启缓存 造成的问题:
开启缓存 造成的问题:
- python最重要的模块logging
logging模块 这个模块是目前最重要的模块!!!我一定给讲透彻一点 很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误.警告等信息输出,python中的loggi ...
- IOS开发 警告 All interface orientations must be supported unless the app requires full screen.
在IOS开发中遇到警告 All interface orientations must be supported unless the app requires full screen. 只要勾上R ...
- IOS开发 多线程GCD
Grand Central Dispatch (GCD)是Apple开发的一个多核编程的解决方法. dispatch queue分成以下三种: 1)运行在主线程的Main queue,通过dispat ...
- python 怎么画图
1 安装matplotlib: 安装方法:http://www.2cto.com/os/201309/246928.html(其中,安装过程中,tar解压怎么解都有问题.然后就删掉再下载一遍) 2 使 ...
- js之购物车案例
这里主要提供思路: 一共两个页面通过原生来实现,我们需要对cookie进行封装. 在商品列表页,我们将点击添加的商品放入一个对象中,而后将该对象放入数组中,一个对象可以说就是一个商品.在购物车页面 ...