storm(二) 事务机制
前言
为了保证tuple的强有序和exactly-once语义,storm提供了事务机制,为每个tuple提供一个id
设计方法1
为每个tuple设置一个事务id,在数据库保存事务id和当前处理的id做比较。
1.两个id不一样,由于事务的强有序特点,判断出该tuple没有出现过,所以更新id
2.id一样,重复出现,可以不用处理
问题:
这样做会导致新能很低,每个tuple都必须处理完后才能处理下一个tuple(否则会影响和下一个tuple的顺序),并且每个tuple还得至少访问一次数据库
设计方法2
单个性能慢,很自然的就想到了多个一起处理。多个tuple形成一个batch。这样也可以保证强有序性
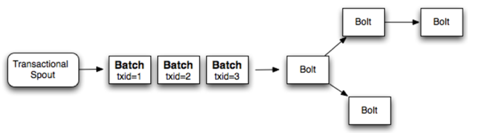
这样性能就提高了很多,如果一个batch处理了1000个tuples,那么性能就提高了1000倍。但是这还是没有更好的把资源利用充分。每个batch都是一个个处理,第二个batch必须等第一个batch完全处理完之后才能开始处理。

设计方法3
(storm选择的设计方法)
通过前两中设计方法,我们意识到了一个关键的思想,并不是所有的处理过程都需要保证强有序。只要保证最终执行完的那瞬间是强有序就ok。抽象出每次处理都需要两步。
1.计算一个batch的部分次数
2.在数据库更新该batch的部分次数
storm实现把对一个batch的计算分成了两块
1.处理。在此环节可以并发处理多个batch
2.提交。在此环节只能处理1个batch。这样就保证了强有序。
当这两块的其中某块出现问题,该事务都会被重新执行。
其实这跟设计方法二有点相似,都用了batch的思想。并结合分治思想,把整体尽可能的拆成许多小碎片,对每一个碎片都用最优的方法处理。
设计细节
1.storm把事务相关的信息存储在zookeeper中
2.storm会管理所有事务的处理或提交时机
3.关于容错。storm利用ack机制,会在合适的时候自动回放失败的事务。使用者不需要做任何acking
回放失败的事务需要一个tuple源的队列,比如kafka。
整体运行流程
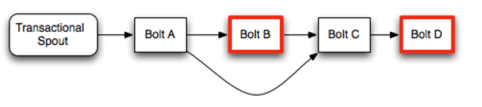
Processer必须等前一个Committer完成提交后才能调用finishBatch。
关于事务失败
由于事务框架屏蔽了Ack接口,提供了另一种方式,可以 throw FailedException.
关于配置
有两个重要配置
1.事务依赖的zookeeper,默认和storm集群依赖的一样,可以通过以下key修改
transactional.zookeeper.servers
2.同时处理batch的个数,默认是1,可以通过以下key修改
topology.max.spout.pending
参考资料
http://storm.apache.org/releases/1.1.1/Transactional-topologies.html
storm(二) 事务机制的更多相关文章
- Storm(三)Storm的原理机制
一.Storm的数据分发策略 1. Shuffle Grouping 随机分组,随机派发stream里面的tuple,保证每个bolt task接收到的tuple数目大致相同. 轮询,平均分配 2. ...
- Redis学习笔记~Redis事务机制与Lind.DDD.Repositories.Redis事务机制的实现
回到目录 Redis本身支持事务,这就是SQL数据库有Transaction一样,而Redis的驱动也支持事务,这在ServiceStack.Redis就有所体现,它也是目前最受业界认可的Redis ...
- 理解storm的ACKER机制原理
一.简介: storm中有一个很重要的特性: 保证发出的每个tuple都会被完整处理.一个tuple被完全处理的意思是: 这个tuple以及由这个tuple所产生的所有的子tuple都被成 ...
- Storm的ack机制在项目应用中的坑
正在学习storm的大兄弟们,我又来传道授业解惑了,是不是觉得自己会用ack了.好吧,那就让我开始啪啪打你们脸吧. 先说一下ACK机制: 为了保证数据能正确的被处理, 对于spout产生的每一个tup ...
- Kafka设计解析(八)- Exactly Once语义与事务机制原理
原创文章,首发自作者个人博客,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/kafka/transaction/ 写在前面的话 本 ...
- 学习RabbitMQ(三):AMQP事务机制
本文转自:http://m.blog.csdn.net/article/details?id=54315940 在使用RabbitMQ的时候,我们可以通过消息持久化操作来解决因为服务器的异常奔溃导致的 ...
- MQ确认机制之事务机制------tx
一:介绍 1.介绍 在前面的说的模式中会出现一个问题. 就是生产者将消息发送出去到底有没有到达rabbitMq,默认情况下是不知道. 有两种解决方式. AMQP实现事务机制 Confirm机制. 这里 ...
- {Django基础六之ORM中的锁和事务}一 锁 二 事务
Django基础六之ORM中的锁和事务 本节目录 一 锁 二 事务 一 锁 行级锁 select_for_update(nowait=False, skip_locked=False) #注意必须用在 ...
- Kafka设计解析(八)Exactly Once语义与事务机制原理
转载自 技术世界,原文链接 Kafka设计解析(八)- Exactly Once语义与事务机制原理 本文介绍了Kafka实现事务性的几个阶段——正好一次语义与原子操作.之后详细分析了Kafka事务机制 ...
随机推荐
- intellij idea 编码设置(乱码问题)
一般把编辑器设置为 utf-8 如下设置: file-->setting-->editor-->file encodings-->
- Python并行编程(一):基本概念
1.线程和进程 进程是应用程序的一个执行实例,比如,在桌面上双击浏览器将会运行一个浏览器.线程是一个控制流程,可以在进程内与其他活跃的线程同时执行.控制流程指的是顺序执行一些机器指令.进程可以包含多个 ...
- 类的super
我们经常在类的继承当中使用super(), 来调用父类中的方法.例如下面: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 class A: def func(self): ...
- 聊聊高并发(三十四)Java内存模型那些事(二)理解CPU快速缓存的工作原理
在上一篇聊聊高并发(三十三)从一致性(Consistency)的角度理解Java内存模型 我们说了Java内存模型是一个语言级别的内存模型抽象.它屏蔽了底层硬件实现内存一致性需求的差异,提供了对上层的 ...
- js-jquery-003-条形码-二维码【QR码】
一.基本使用 插件地址:https://github.com/jeromeetienne/jquery-qrcode 1.首先在页面中加入jquery库文件和qrcode插件. <script ...
- Ubuntu 16.04 源码编译安装PHP7+swoole
备注: Ubuntu 16.04 Server 版安装过程图文详解 Ubuntu16镜像地址: 链接:https://pan.baidu.com/s/1XTVS6BdwPPmSsF-cYF6B7Q 密 ...
- MySQL协议分析(2)
MySQL协议分析(2) 此阶段是在压缩传输无加密条件下进行的协议分析 思路 结合Oracle官网的说明和自己用wireshark加python进行数据包分析 步骤 客户端与服务器端是否压缩的协商阶段 ...
- Java中树和树的几种常规遍历方法
其中包含有先序遍历.中序遍历.后序遍历以及广度优先遍历四种遍历树的方法: package com.ietree.basic.datastructure.tree.binarytree; import ...
- PHPCMS 修改后台路径简便方法
之前在网上找了很多关于修改phpcms后台路径的修改方法,但是都太繁琐(个人感觉),终于找到了一个相对简单的修改方法,在这里和大家分享一下,希望互相学习. 第一步:在网站根目录创建一个文件夹,以后就要 ...
- 本地idea开发mapreduce程序提交到远程hadoop集群执行
https://www.codetd.com/article/664330 https://blog.csdn.net/dream_an/article/details/84342770 通过idea ...