elasticsearch之节点重启
Elasticsearch节点重启时背后发生的故事有哪些,应该注意哪些配置内容,本篇文章做一个简单的探讨。
节点离开
在elasticsearch集群中,假设NodeA因为种种原因退出集群,在NodeA上的Shard分片情况(ShardA是主分片,ShardB是某一分片副本)
- 在存活节点上找到ShardA的副本,将该副本升格为主分片
- 由于ShardB这一分片副本丢失,所以会重新创建相应的分片副本
- 在存活的节点中对于分片进行再平衡
这样做的目的是保证每个分片都有足够的副本,可以避免数据丢失。需要注意的是,步骤二和步骤三牵涉到大量的网络I/O操作。
节点返回
如果离开的节点重新加入集群,elasticsearch为了对数据分片(shard)进行再平衡,会为重新加入的NodeA再次分配数据分片(Shard), 这会再次导致大量的网络I/O操作。
延迟副本的重新分配
如果NodeA在离开前上面存在副本ShardB,重新加入之后还是有副本ShardB,看起来一样,但其实中间已经进行了大量的网络I/O,那么有没有办法延迟副本的重新分配呢,这样会冒丢失数据的可能(如果在NodeA重新加入之前,其它节点也挂了), 但是可以节省相应的网络开销。
延迟副本分配可以通过设置参数index.unassigned.node_left.delayed_timeout来实现,该参数动态可调,默认值是1分钟(1m)
PUT /_all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}
上述脚本将副本重新分配延迟到5分钟之后。
查看数据分片分布情况
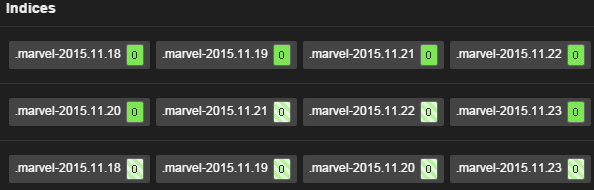
使用elasticsearch中的marvel插件可以很清楚的看到数据分片的分布情况,选取marvel中右上角 DashBoard 中的 Shard Allocation , 可以看到类似于下图的分布情况
更多选项
如果日常维护elasticsearch集群,针对某一节点进行需要重启的更改,那么可以先禁止分片分配,待重启完成后,再打开
PUT _cluster/setting
{
"cluster.routing.allocation.disable_allocation": true
}
避免节点重启导致的脑裂
如果elasticsearch集群中节点数比较多,而且负载也比较高,这个时候对某一个instance进行重启,很有可能会导致该instance无法找到master而将自己推举为master的情况出现,如何防止,需要调整 elasticsearch.yml 中的内容
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.timeout: 120s
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: ["host1","host2"]
client.transport.ping_timeout: 60s
加快recovery的进程
Elasticsearch在默认情况下将资源更多的分配给正常的traffic,这样给recovery的资源相对有限,会导致整个集群长时间处于yellow状态,如果机器配置很强劲,那么更改如下配置,可以加快elasticsearch instance重启之后的恢复过程。
cluster.routing.allocation.node_initial_primaries_recoveries: 10
cluster.routing.allocation.node_concurrent_recoveries: 5
indices.recovery.max_bytes_per_sec: 100mb
indices.recovery.concurrent_streams: 5
elasticsearch之节点重启的更多相关文章
- elasticsearch如何安全重启节点
elasticsearch如何安全重启节点 标签: elasticsearch 节点 | 发表时间:2016-05-24 03:58 | 作者:kfcman 分享到: 出处:http://www.it ...
- elasticsearch如何安全重启
elasticsearch如何安全重启节点 问题: elasticsearch集群,有时候可能需要修改配置,增加硬盘,扩展内存等操作,需要对节点进行维护升级.但是业务不能停,如果直接kill掉节 点, ...
- elasticsearch 单节点搭建与爬坑记录
elasticsearch 单节点搭建与爬坑记录 prepare 虚拟机或者云服务器(这里用的是阿里云ECS) linux---centos7 安装完毕的jdk 相应的安装包(在https:/ ...
- rac 11g_第二个节点重启后无法启动实例:磁盘组dismount问题
原创作品,出自 "深蓝的blog" 博客,欢迎转载,转载时请务必注明以下出处,否则追究版权法律责任. 深蓝的blog:http://blog.csdn.net/huangyanlo ...
- Oracle教程:如何诊断节点重启问题(转载)
本文对如何诊断RAC环境中节点重启问题进行了介绍.适用于10gR2和11gR1. 首先我们对能够导致节点重启的CRS进程进行介绍.1.ocssd : 它的主要功能是节点监控(Node Monitori ...
- Erlang节点重启导致的incarnation问题(转)
转自霸爷的博客: 转载自系统技术非业余研究 本文链接地址: Erlang节点重启导致的incarnation问题 遇到个问题, =ERROR REPORT==== 10-Mar-2016::09:44 ...
- 11gR2 如何诊断节点重启问题
本文对如何诊断11gR2 GI环境下的节点重启问题进行了一些介绍. 首先,像10g版本一样,我们首先介绍在GI中能够导致节点重启的进程.1.Ocssd.bin:这个进程的功能和10g版本的功能基本差不 ...
- Hadoop 分布式环境slave节点重启忽然不好使了
Hadoop 分布式环境slaves节点重启: 忽然无法启动DataNode和NodeManager处理: 在master节点: vim /etc/hosts: 修改slave 节点的IP (这个时候 ...
- Elasticsearch 学习之 节点重启
ElasticSearch集群的高可用和自平衡方案会在节点挂掉(重启)后自动在别的结点上复制该结点的分片,这将导致了大量的IO和网络开销.如果离开的节点重新加入集群,elasticsearch为了对数 ...
随机推荐
- css如何实现水平居中呢?css实现水平居中的方法?
面试中遇到的一个问题:如何让css实现水平居中?下面来看一下哪些方法能实现水平居中. 首先分两种情况,行内元素还是块级元素.然而块级元素又分为定宽块状元素和不定款块状元素.先来看下行内元素如何水平居中 ...
- 坑爹的私有API
iOS私有API扫描工作总结 背景 苹果提供的iOS开发框架分PrivateFramework和Framework,PrivateFramework下的库是绝对不允许在提交的iOS应用中使用的,只允许 ...
- Python里*arg 和**kwargs的作用
Hi,伙计们.我发现Python新手们在理解*args和**kwargs这两个魔法变量时都有些困难.他们到底是什么?首先,我先告诉大家一个事实,完整地写*args和**kwargs是不必要的,我们可以 ...
- GET和POST
Ajax与Comet 1. Ajax Asynchronous Javascript+xml :能够向服务器请求额外的数据而无需卸载页面. Ajax技术的核心是XMLHttpRequest 对象(简称 ...
- 一款全兼容的播放器 videojs
[官网]http://www.videojs.com/ videojs就提供了这样一套解决方案,他是一个兼容HTML5的视频播放工具,早期版本兼容所有浏览器,方法是:提供三个后缀名的视频,并在不支持h ...
- ASM:《X86汇编语言-从实模式到保护模式》第17章:保护模式下中断和异常的处理与抢占式多任务
★PART1:中断和异常概述 1. 中断(Interrupt) 中断包括硬件中断和软中断.硬件中断是由外围设备发出的中断信号引发的,以请求处理器提供服务.当I/O接口发出中断请求的时候,会被像8259 ...
- sqlserver2000 数据库 'tempdb' 的日志已满
方法一解决过程: 查看了下数据库的属性,是自动增长,不指定文件大小上限.在网上Google了很久,试了些方法都不行:数据库所在磁盘还有很大的可用空间,试着下重药了.直接把tempdb的数据文件和日志文 ...
- MapReduce类型与格式(输入与输出)
一.输入格式 (1)输入分片记录 ①JobClient通过指定的输入文件的格式来生成数据分片InputSplit: ②一个分片不是数据本身,而是可分片数据的引用: ③InputFormat接口负责生成 ...
- 2.Java异常学习
1.Java异常的概念 异常的例子 1.除法就是一个需要捕获异常的例子,除数又可能是0 异常处理的基本流程如下 一旦发生异常,就使得程序不按照原来的流程继续的运行下去 a.程序抛出异常 try{ th ...
- PHP运行模式
1.运行模式 关于PHP目前比较常见的五大运行模式: 1)CGI(通用网关接口 / Common Gateway Interface) 2)FastCGI(常驻型CGI / Long-Live CGI ...