一图看懂Hadoop中的MapReduce与Spark的区别:从单机数据系统到分布式数据系统经历了哪些?
今日博主思考了一个问题:Hadoop中的MapReduce与Spark他们之间到底有什么关系?
直到我看到了下面这张图
废话不多说先上图
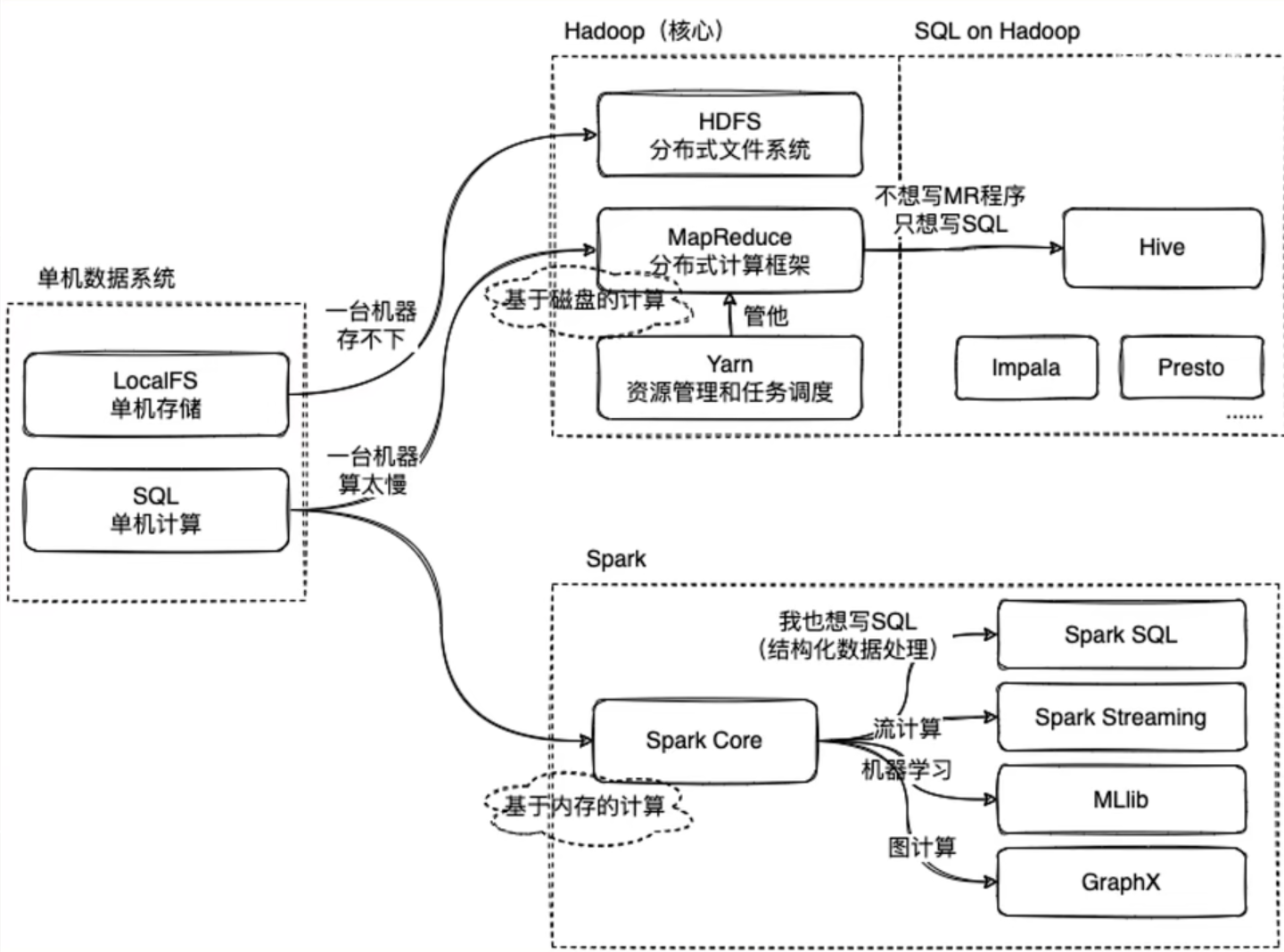
我们知道,单机数据系统,在本地主机上针对数据有单机本地存储操作(localFS)和单机计算操作(SQL)
这是在数据量比较小方便在一台主机就完成任务的情况。
那当我们的业务需要的数据足够大,一台机器完全应付不过来的时候应该怎么办?
我们很容易想到,既然一台机器办不到的事情,我们就交给10台机器、100台机器去办。
没错!
当我们的数据量足够庞大时,我们需要多台机器协同完成业务,此时我们就需要将数据一份份分成足够让一台机器能处理运行的小部分,布置给多台机器共同完成,这就是所谓的分布式数据系统
Hadoop就是为这样的业务场景服务的
Apache Hadoop是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架,有助于使用许多计算机组成的网络来解决数据、计算密集型的问题。基于MapReduce计算模型,它为大数据的分布式存储与处理提供了一个软件框架。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。————wikipedia
Apache Hadoop的核心模块分为存储和计算模块,前者被称为Hadoop分布式文件系统(HDFS),后者即MapReduce计算模型。Hadoop框架先将文件分成数据块并分布式地存储在集群的计算节点中,接着将负责计算任务的代码传送给各节点,让其能够并行地处理数据。这种方法有效利用了数据局部性,令各节点分别处理其能够访问的数据。与传统的超级计算机架构相比,这使得数据集的处理速度更快、效率更高。
其中HDFS分布式文件系统做到了利用多台机器的分布式文件存储,而MapReduce则实现了对数据的计算,而我们还需要一个对他们实现调度管理的“帮手”——Yarn
Mapreduce的实现需要自己编写计算框架,这很麻烦。
所以为什么不能有像单机数据系统的SQL一样方便的操作呢?
于是Hive就诞生了。
那,Spark又是怎么回事?
Spark对标的是Hadoop中的计算模块MapReduce,而一般情况下Spark会比MapReduce快2~3倍,
这是因为,MapReduce是基于磁盘的计算,而Spark是基于内存的计算。
而Spark中也有像Hive一样为了方便而诞生的只用写SQL语句就能完成数据处理的方式——Spark SQL
在Spark中还有一些格外的功能,例如针对机器学习使用的Spark MLib、针对流计算的Spark streaming以及针对图计算的Spark GraphX等等
以上就是Hadoop中的MapReduce与Spark 的区别,以及他们实现为了实现结构化数据处理进行的SQL实现。
一图看懂Hadoop中的MapReduce与Spark的区别:从单机数据系统到分布式数据系统经历了哪些?的更多相关文章
- 一图看懂hadoop分布式文件存储系统HDFS工作原理
一图看懂hadoop分布式文件存储系统HDFS工作原理
- 一图看懂hadoop MapReduce工作原理
MapReduce执行流程及单词统计WordCount示例
- 一张图看懂JavaScript中数组的迭代方法:forEach、map、filter、reduce、every、some
好吧,竟然不能单发一张图,不够200字啊不够200字! 在<JavaScript高级程序设计>中,分门别类介绍了非常多数组方法,其中迭代方法里面有6种,这6种方法在实际项目有着非常广泛的作 ...
- 一图看懂hadoop Spark On Yarn工作原理
hadoop Spark On Yarn工作原理
- 一图看懂hadoop Yarn工作原理
Hadoop 资源调度框架Yarn运行流程
- 一张图看懂AI、机器学习和深度学习的区别
AI(人工智能)是未来,是科幻小说,是我们日常生活的一部分.所有论断都是正确的,只是要看你所谈到的AI到底是什么. 例如,当谷歌DeepMind开发的AlphaGo程序打败韩国职业围棋高手Lee Se ...
- 一图看懂Spring获取对象与java new对象区别
Spring获取对象与java new对象的区别,图片被压缩了,请点击图片放大查看
- 一张图看懂ANSYS17.0 流体 新功能与改进
一张图看懂ANSYS17.0 流体 新功能与改进 提交 我的留言 加载中 已留言 一张图看懂ANSYS17.0 流体 新功能与改进 原创2016-02-03ANSYS模拟在线模拟在线 模拟在线 ...
- 一篇文章一张思维导图看懂Android学习最佳路线
一篇文章一张思维导图看懂Android学习最佳路线 先上一张android开发知识点学习路线图思维导图 Android学习路线从4个阶段来对Android的学习过程做一个全面的分析:Android初级 ...
- 一张图看懂开源许可协议,开源许可证GPL、BSD、MIT、Mozilla、Apache和LGPL的区别
一张图看懂开源许可协议,开源许可证GPL.BSD.MIT.Mozilla.Apache和LGPL的区别 首先借用有心人士的一张相当直观清晰的图来划分各种协议:开源许可证GPL.BSD.MIT.Mozi ...
随机推荐
- 使用sonarqube对java项目进行分析
目前有两种办法,第一种是使用SonarQube-Scanner-Maven,第二种是结合gitlab-ci进行 前提条件:已安装并启动sonarqube,知道访问地址和登录的用户名及密码,具体参考文档 ...
- Kibana:如何让用户匿名访问 Kibana 中的 Dashboard
文章转载自:https://elasticstack.blog.csdn.net/article/details/118152293 有一个很好的 Dashboard,我们想分析这个 Dashboar ...
- cAdvisor容器监控规则
其他说明参考host主机监控规则:https://www.cnblogs.com/sanduzxcvbnm/p/13589848.html 在prometheus主程序目录下的rules目录下新建do ...
- 【前端必会】使用indexedDB,降低环境搭建成本
背景 学习前端新框架.新技术.如果需要做一些数据库的操作来增加demo的体验(CURD流程可以让演示的体验根据丝滑) 最开始的时候一个演示程序我们会调用后台,这样其实有一点弊端,就是增加了开发和维护成 ...
- Wine 安装迅雷5.8.14.176
测试过的系统版本:Kubuntu 22.04 测试过的Wine版本 Wine7.8 程序下载地址: https://pan.baidu.com/s/1pSgunVH3WtACssX5we3DdQ 提取 ...
- MySQL用户也可以是个角色
前言 角色(Role),可以认为是一些权限的集合,一直是存在各个数据库中,比如Oracle.SQL Server.OceanBase等,MySQL 自从 8.0 release 才引入角色这个概念. ...
- Stanford CoreNLP无法生成实例对象
在服务器上运行Stanford,今日无法启动"StanfordCoreNLP"了,就是运行下面代码一直在运行,不结束,不报错. from stanfordcorenlp impor ...
- 方法的重载(overload)
1.定义:在同一个类中,允许存在一个以上的同名方法,只要它们的参数个数或者参数类型不同即可. "两同一不同":同一个类.相同方法名 参数列表不同:参数个数不同,参数类型不同 2.举 ...
- vue+spirngboot 分离技术实现图书信息的增删改查(改造这学期的课程设计【1】)
1.前端项目的创建 vue init webpack bookshopvue 安装axios http://www.axios-js.com/ npm install --save axios vue ...
- Debian安装WPS的方法
1.防止安装失败,请尽量重启电脑,关闭系统的软件商店,因为商店的权限可能会锁住pkg的配置文件,导致无法安装wps. 2.将原机残废的WPS卸载干净,卸载方法:手动或命令行操作. sudo apt r ...