一图看懂Hadoop中的MapReduce与Spark的区别:从单机数据系统到分布式数据系统经历了哪些?
今日博主思考了一个问题:Hadoop中的MapReduce与Spark他们之间到底有什么关系?
直到我看到了下面这张图
废话不多说先上图
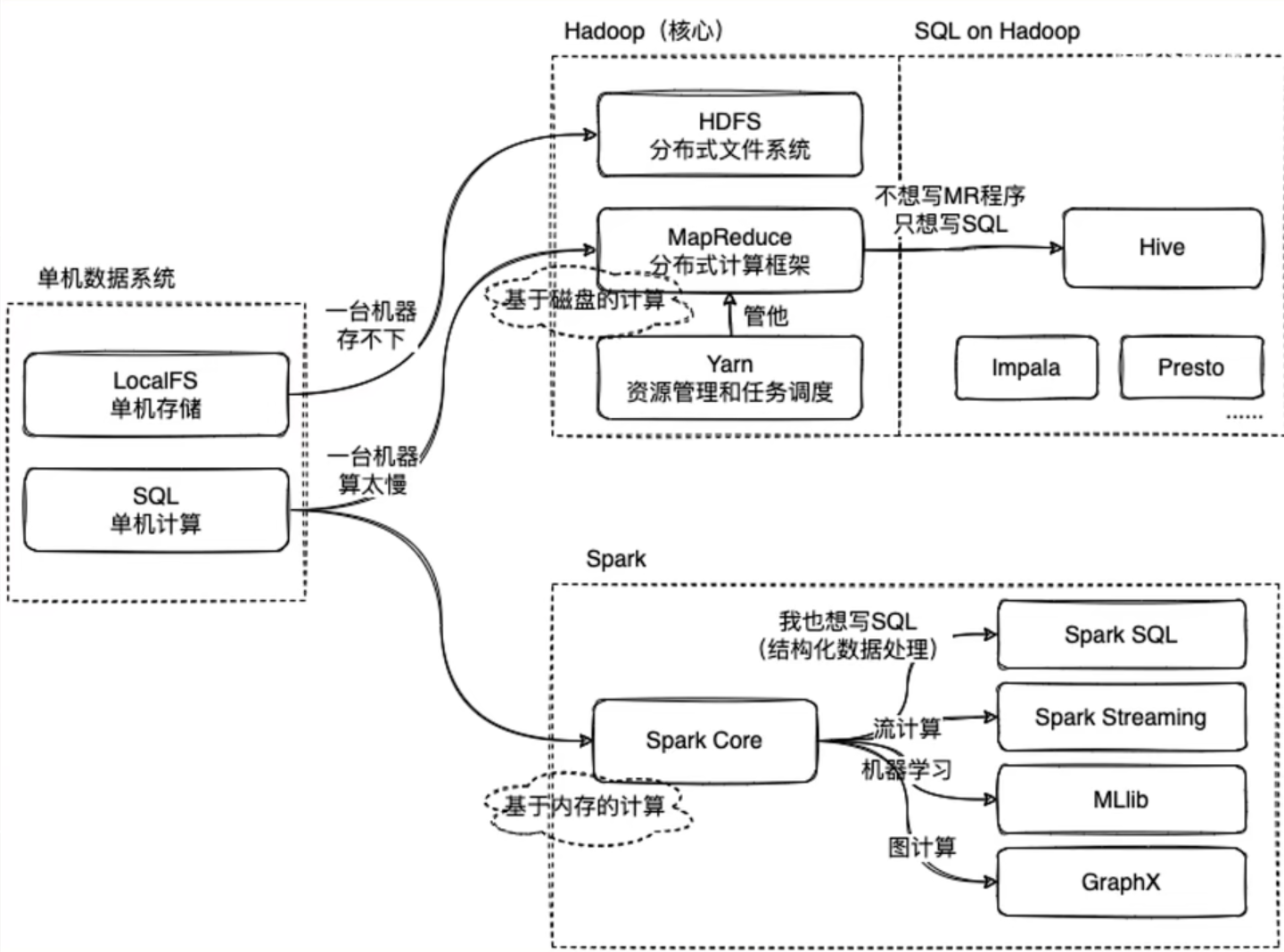
我们知道,单机数据系统,在本地主机上针对数据有单机本地存储操作(localFS)和单机计算操作(SQL)
这是在数据量比较小方便在一台主机就完成任务的情况。
那当我们的业务需要的数据足够大,一台机器完全应付不过来的时候应该怎么办?
我们很容易想到,既然一台机器办不到的事情,我们就交给10台机器、100台机器去办。
没错!
当我们的数据量足够庞大时,我们需要多台机器协同完成业务,此时我们就需要将数据一份份分成足够让一台机器能处理运行的小部分,布置给多台机器共同完成,这就是所谓的分布式数据系统
Hadoop就是为这样的业务场景服务的
Apache Hadoop是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架,有助于使用许多计算机组成的网络来解决数据、计算密集型的问题。基于MapReduce计算模型,它为大数据的分布式存储与处理提供了一个软件框架。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。————wikipedia
Apache Hadoop的核心模块分为存储和计算模块,前者被称为Hadoop分布式文件系统(HDFS),后者即MapReduce计算模型。Hadoop框架先将文件分成数据块并分布式地存储在集群的计算节点中,接着将负责计算任务的代码传送给各节点,让其能够并行地处理数据。这种方法有效利用了数据局部性,令各节点分别处理其能够访问的数据。与传统的超级计算机架构相比,这使得数据集的处理速度更快、效率更高。
其中HDFS分布式文件系统做到了利用多台机器的分布式文件存储,而MapReduce则实现了对数据的计算,而我们还需要一个对他们实现调度管理的“帮手”——Yarn
Mapreduce的实现需要自己编写计算框架,这很麻烦。
所以为什么不能有像单机数据系统的SQL一样方便的操作呢?
于是Hive就诞生了。
那,Spark又是怎么回事?
Spark对标的是Hadoop中的计算模块MapReduce,而一般情况下Spark会比MapReduce快2~3倍,
这是因为,MapReduce是基于磁盘的计算,而Spark是基于内存的计算。
而Spark中也有像Hive一样为了方便而诞生的只用写SQL语句就能完成数据处理的方式——Spark SQL
在Spark中还有一些格外的功能,例如针对机器学习使用的Spark MLib、针对流计算的Spark streaming以及针对图计算的Spark GraphX等等
以上就是Hadoop中的MapReduce与Spark 的区别,以及他们实现为了实现结构化数据处理进行的SQL实现。
一图看懂Hadoop中的MapReduce与Spark的区别:从单机数据系统到分布式数据系统经历了哪些?的更多相关文章
- 一图看懂hadoop分布式文件存储系统HDFS工作原理
一图看懂hadoop分布式文件存储系统HDFS工作原理
- 一图看懂hadoop MapReduce工作原理
MapReduce执行流程及单词统计WordCount示例
- 一张图看懂JavaScript中数组的迭代方法:forEach、map、filter、reduce、every、some
好吧,竟然不能单发一张图,不够200字啊不够200字! 在<JavaScript高级程序设计>中,分门别类介绍了非常多数组方法,其中迭代方法里面有6种,这6种方法在实际项目有着非常广泛的作 ...
- 一图看懂hadoop Spark On Yarn工作原理
hadoop Spark On Yarn工作原理
- 一图看懂hadoop Yarn工作原理
Hadoop 资源调度框架Yarn运行流程
- 一张图看懂AI、机器学习和深度学习的区别
AI(人工智能)是未来,是科幻小说,是我们日常生活的一部分.所有论断都是正确的,只是要看你所谈到的AI到底是什么. 例如,当谷歌DeepMind开发的AlphaGo程序打败韩国职业围棋高手Lee Se ...
- 一图看懂Spring获取对象与java new对象区别
Spring获取对象与java new对象的区别,图片被压缩了,请点击图片放大查看
- 一张图看懂ANSYS17.0 流体 新功能与改进
一张图看懂ANSYS17.0 流体 新功能与改进 提交 我的留言 加载中 已留言 一张图看懂ANSYS17.0 流体 新功能与改进 原创2016-02-03ANSYS模拟在线模拟在线 模拟在线 ...
- 一篇文章一张思维导图看懂Android学习最佳路线
一篇文章一张思维导图看懂Android学习最佳路线 先上一张android开发知识点学习路线图思维导图 Android学习路线从4个阶段来对Android的学习过程做一个全面的分析:Android初级 ...
- 一张图看懂开源许可协议,开源许可证GPL、BSD、MIT、Mozilla、Apache和LGPL的区别
一张图看懂开源许可协议,开源许可证GPL.BSD.MIT.Mozilla.Apache和LGPL的区别 首先借用有心人士的一张相当直观清晰的图来划分各种协议:开源许可证GPL.BSD.MIT.Mozi ...
随机推荐
- DirectPV-----文章内容有待进一步实践完善
GitHub文档地址:https://github.com/minio/directpv DirectPV是用于直连存储的CSI驱动程序.从更简单的意义上讲,它是一个分布式持久卷管理器,而不是像SAN ...
- 使用traefik进行金丝雀发布
文章转载自:https://mp.weixin.qq.com/s/nMMN7hAJK6SFn1V1YyxvHA 在 Traefik 2.0 中以服务负载均衡的形式进行了支持.可以将服务负载均衡器看成负 ...
- 防火墙:iptable和firewalld常用操作
iptables //安装iptables-service yum install iptables-services //编辑config文件 vi /etc/sysconfig/iptables ...
- PAT (Advanced Level) Practice 1002 A+B for Polynomials 分数 25
This time, you are supposed to find A+B where A and B are two polynomials. Input Specification: Each ...
- SpringBoot课程学习(二)
一.断言 (1).@assertTrue,@assertFalse assertTrue与assertFalse用来判断条件是否为true或false,assertTrue表示如果值为true则通过, ...
- 使用 Spring Security 手动验证用户
1.概述 在这篇快速文章中,我们将重点介绍如何在 Spring Security 和 Spring MVC 中手动验证用户的身份. 2.Spring Security 简单地说,Spring Secu ...
- GitLab + Jenkins + Harbor 工具链快速落地指南
目录 一.今天想干啥? 二.今天干点啥? 三.今天怎么干? 3.1.常规打法 3.2.不走寻常路 四.开干吧! 4.1.工具链部署 4.2.网络配置 4.3.验证工具链部署结果 4.3.1.GitLa ...
- Magnet: Push-based Shuffle Service for Large-scale Data Processing
本文是阅读 LinkedIn 公司2020年发表的论文 Magnet: Push-based Shuffle Service for Large-scale Data Processing 一点笔记. ...
- 齐博x1标签实例:调用多个圈子同时调用贴子
下面讲解,在首页,如何调用圈子的同时也调用他们相关的贴子. 单单调用圈子,就像调用文章一样,很多人都能轻松实现,比如下面的代码 {qb:tag name="xxx" type=&q ...
- springMVC必要jar包
spring-aop-4.3.2.RELEASE.jar :: 包含在应用中使用Spring 的AOP 特性时所需的类和源码级元数据支持. spring-beans-4.3.2.RELEASE.jar ...