csv数据集按比例分割训练集、验证集和测试集,即分层抽样的方法
一、一种比较通俗理解的分割方法
1.先读取总的csv文件数据:
import pandas as pd
data = pd.read_csv('D:\BaiduNetdiskDownload\weibo_senti_100k\weibo_senti_100k\weibo_senti_100k.csv')
data.head(10)#输出前十行

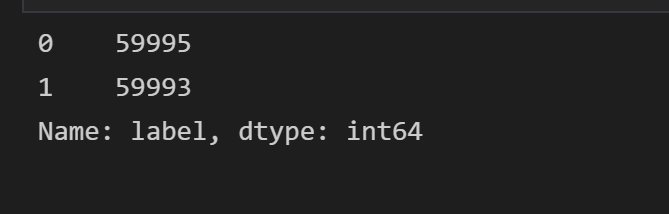
data.label.value_counts()#查看标签类别及数目
2.按照标签将总的dataframe分割为两份,一份为标签为1,一份为标签为0
groups = data.groupby(data.label)
data_true = groups.get_group(1)
data_false = groups.get_group(0)
data_true.head(10),data_false.head(10)

3.
data_true = data_true.sample(frac=1.0) # 全部打乱
data_false = data_false.sample(frac=1.0) # 全部打乱
#给测试集两种标签各600个,按照大概8:1:1的比例取
test_true = data_true.iloc[:600, :]
test_false = data_false.iloc[:600, :]
test_data = pd.concat([test_true, test_false], axis = 0, ignore_index=True).sample(frac=1)
#验证集
valid_true = data_true.iloc[600:1200, :]
valid_false = data_false.iloc[600:1200, :]
valid_data = pd.concat([valid_true, valid_false], axis = 0, ignore_index=True).sample(frac=1)
#训练集
train_true = data_true.iloc[1200:, :]
train_false = data_false.iloc[1200:, :]
train_data = pd.concat([train_true, train_false], axis = 0, ignore_index=True).sample(frac=1)
4.生成csv文件
test_data.to_csv('test.csv')
valid_data.to_csv('val.csv')
train_data.to_csv('train.csv')
二、不通俗方法
可以看出上面的方法不断地生成新的dataframe太麻烦了些,虽然直观醒目,但在代码编写上很是繁冗,于是可以使用apply方法避免这种问题
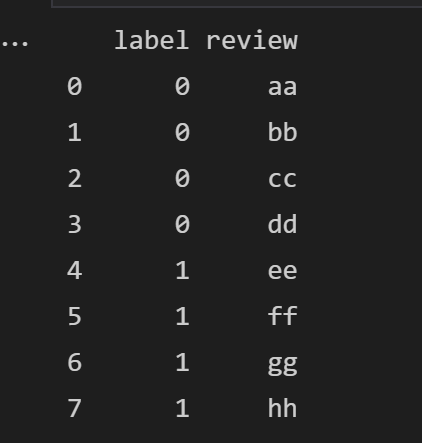
1.为便于讲解,先生成一个简单的dataframe:
df = pd.DataFrame({'label':[0,0,0,0,1,1,1,1], 'review':['aa', 'bb', 'cc', 'dd', 'ee', 'ff', 'gg', 'hh']})
2.首先定义一个简单的分层取样函数,frac为取样概率,group为一个单独的dataframe
def simpleSampling(group, frac):
return group.sample(frac=frac)
3.接下来使用apply函数对分组后的每一个组(即一个dataframe)进行函数操作
train_df = df.groupby(df.label).apply(simpleSampling, 0.5)
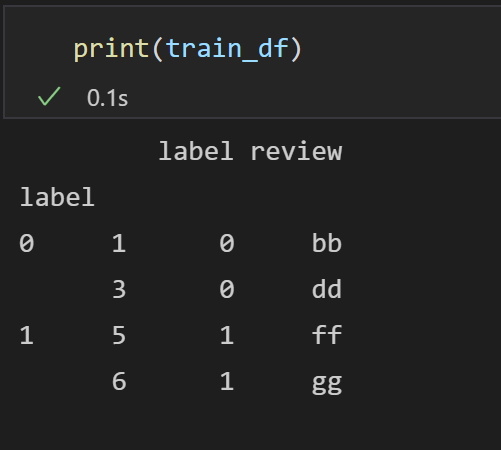
可以看到多了一列label标签,可以使用sample(frac=1, ignore_index = True)消除它
4.在生成了train数据集后,我们需要把train从原df中删除掉,但是dataframe没有直接删除的方法,我们迂回的使用删除重复行的方法:
df = df.append(train_df.sample(frac=1, ignore_index=True)).drop_duplicates(keep = False)
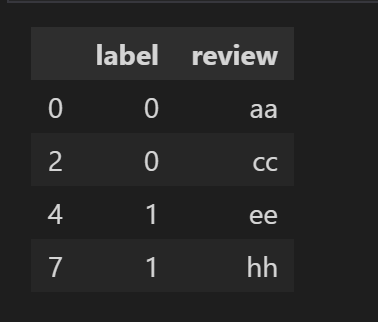
可以看到df只剩上图的几行了,接下来生成测试集和验证集
5.我们如果要生成原数据集0.25比例的验证集,那么需要注意的是,在将train删除后,在新的数据集中我们的比例就变成了p(val) = p(test) = 0.25 / 0.5 = 0.5
val_df = df.groupby(df.label).apply(simpleSampling, 0.5).sample(frac=1, ignore_index = True)
test_df = df.append(val_df).drop_duplicates(keep=False)
train_df.to_csv('train_csv')
val_df.to_csv('val_csv')
test_df.to_csv('test_csv')
至此我们的数据集就已经成功分割了,以上两种方法原理相同,只是第二种方法巧妙地应用了apply函数,避免了一个接一个的新的dataframe的生成。
csv数据集按比例分割训练集、验证集和测试集,即分层抽样的方法的更多相关文章
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- 【深度学习的实用层面】(一)训练,验证,测试集(Train/Dev/Test sets)
在配置训练.验证.和测试数据集的过程中做出正确的决策会更好地创建高效的神经网络,所以需要对这三个名词有一个清晰的认识. 训练集:用来训练模型 验证集:用于调整模型的超参数,验证不同算法,检验哪种算法更 ...
- 机器学习入门06 - 训练集和测试集 (Training and Test Sets)
原文链接:https://developers.google.com/machine-learning/crash-course/training-and-test-sets 测试集是用于评估根据训练 ...
- [机器学习] 训练集(train set) 验证集(validation set) 测试集(test set)
在有监督(supervise)的机器学习中,数据集常被分成2~3个即: 训练集(train set) 验证集(validation set) 测试集(test set) 一般需要将样本分成独立的三部分 ...
- 训练集(train set) 验证集(validation set) 测试集(test set)
转自:http://www.cnblogs.com/xfzhang/archive/2013/05/24/3096412.html 在有监督(supervise)的机器学习中,数据集常被分成2~3个, ...
- 随机切分csv训练集和测试集
使用numpy切分训练集和测试集 觉得有用的话,欢迎一起讨论相互学习~Follow Me 序言 在机器学习的任务中,时常需要将一个完整的数据集切分为训练集和测试集.此处我们使用numpy完成这个任务. ...
- 训练集(train set) 验证集(validation set) 测试集(test set)。
训练集(train set) 验证集(validation set) 测试集(test set). http://blog.sina.com.cn/s/blog_4d2f6cf201000cjx.ht ...
- AI---训练集(train set) 验证集(validation set) 测试集(test set)
在有监督(supervise)的机器学习中,数据集常被分成2~3个即: 训练集(train set) 验证集(validation set) 测试集(test set) 一般需要将样本分成独立的三部分 ...
- sklearn学习3----模型选择和评估(1)训练集和测试集的切分
来自链接:https://blog.csdn.net/zahuopuboss/article/details/54948181 1.sklearn.model_selection.train_test ...
- sklearn——train_test_split 随机划分训练集和测试集
sklearn——train_test_split 随机划分训练集和测试集 sklearn.model_selection.train_test_split随机划分训练集和测试集 官网文档:http: ...
随机推荐
- js过滤filter 按条件过滤
const dataList = this.formData.tableData.filter(item => item.name !== '');
- MySQL分库分表原理
转自https://www.jianshu.com/p/7aec260ca1a2 前言 在互联网还未崛起的时代,我们的传统应用都有这样一个特点:访问量.数据量都比较小,单库单表都完全可以支撑整个业务. ...
- turtle绘制风轮
题目要求: 使用turtle库,绘制一个风轮效果,其中,每个风轮内角为45度,风轮边长150像素. 我的代码: import turtle turtle.setup(500,500,100,200) ...
- Visual Studio 2022 离线包手动下载和清理
下载离线vsvs_Professional.exe --layout e:\vs2022 --all --includeRecommended --includeOptional --lang zh- ...
- java文本转语音
下载jar包https://github.com/freemansoft/jacob-project/releases 解压,将jacob-1.18-xxx.dll相应放到项目使用的JAVA_HOME ...
- 1012.Django中间件以及上下文处理器
一.中间件 中间件的引入: Django中间件(Middleware)是一个轻量级.底层的"插入"系统,可以介入Django的请求和响应处理过程,修改Django的输入或输出. d ...
- How to Show/Hide a Button Using the Business Process Flow Stage
How to Show/Hide a Button Using the Business Process Flow Stage In today's blog, we'll discuss how t ...
- 惰性载入(函数)-跟JS性能有关的思想
一.惰性载入概念: 惰性.懒惰.其实跟懒惰没有关系,就是图省事,把没意义的事少做.不做. 惰性载入函数:函数执行时会根据不同的判断分支最终选择合适的方案执行,但这样的分支判断仅会发生一次,后面的其他同 ...
- 认证全家桶(Cookie、Session、Token、JWT)
什么是认证(Authentication) 通俗地讲就是验证当前用户的身份,证明"你是你自己"(比如:你每天上下班打卡,都需要通过指纹打卡,当你的指纹和系统里录入的指纹相匹配时,就 ...
- Javaweb学习笔记第十五弹--Listente概述、AJAX、Axiox、JSON
Listener(监听器) 可以在application.session和request三个对象创建 Javaweb提供了8个监听器,其中较为典型的是ServletContextListener监听器 ...