Kubernetes_从云原生到kubernetes
一、前言
二、kubernetes和云原生
Cloud Native 直接翻译为云原生,云原生官网:https://www.cncf.io/
CNCF,表示 Cloud Native Computing Foudation ,翻译为 云原生计算基金会,属于Linux基金会,初衷是围绕“云原生”服务云计算,维护和集成开源技术,支持编排容器化微服务架构应用。
时至今日,Kubernetes逐渐已经成为云原生失败的基础设置。
Docker是容器化技术,Kubernetes是一种容器编排技术,之前还有一个Docker Swarm也是一种容器编排技术,但是已经不被使用。
云原生这三字,云表示在云服务器上部署,原生的意义就是 部署在一个陌生的环境,像部署在自己熟悉的环境上,类似于 JVM 一次编译,到处运行。
要实现云原生这个一次编译,到处运行,涉及很多组件,从小到大,Docker是容器化部署,Kubernetes是容器编排工具(Docker Swarm也是),对Docker进行编排,就是通过 yaml 文件来实现;Helm是包管理工具,对Kubernetes的 yaml 进行编排,Helm 中通过 if 块可以用 values.yaml 文件中变量 精确的决定 kubernetes yaml 文件中哪一行是否需要被运用。
kubernetes是云原生时代基础设施,如下图:
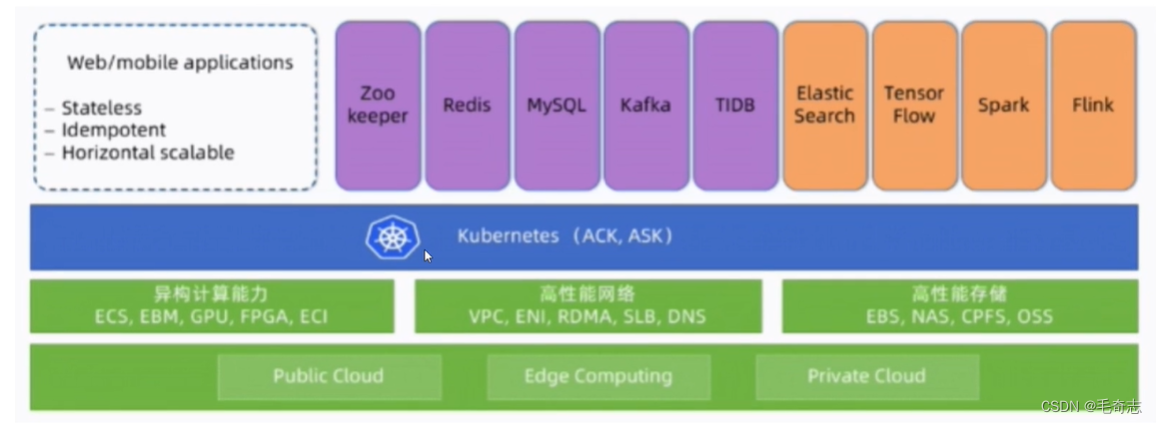
上图表示,将应用部署在Kubernetes集群上,这样 应用就可以在 公有云 私有云 混合云 上无缝迁移。应用包括用于数据存储的有状态的应用,使用StatefulSet部署,不用于数据存储的无状态的应用,使用Deployment部署。
Kubernetes四种部署方式:Deployment StatefulSet DaemonSet Job(CronJob)
ReplicaSet 存在的意义就是 replicas 这个属性 how many Pods
Deployment 存在的意义就是无状态
StatefulSet 存在的意义就是有状态
DaemonSet 存在的意义就是日志 监控
Job(CronJob) 存在的意义是一次性任务和定时任务
小结:云原生这三字,云表示在云服务器上部署,原生的意义就是部署在一个陌生的环境,像部署在自己熟悉的环境上,类似于 JVM 一次编译,到处运行。容器化部署实现了这个目标,Kubernetes是一种容器编排技术,所以说Kubernetes是云原生时代基础设施,这就是Docker、Kubernetes与云原生的关系。
三、从Docker Swarm到Kubernetes
kubernetes本质是一个容器编排技术,docker内置的 docker swarm 也是做容器编排的,都是管理和编排Docker Container容器,但是对于容器编排,k8s更加优秀,是现在的主流。
重点学习kubernetes,docker swarmy了解即可,知道有这个东西即可。
Github上:https://github.com/kubernetes/kubernetes
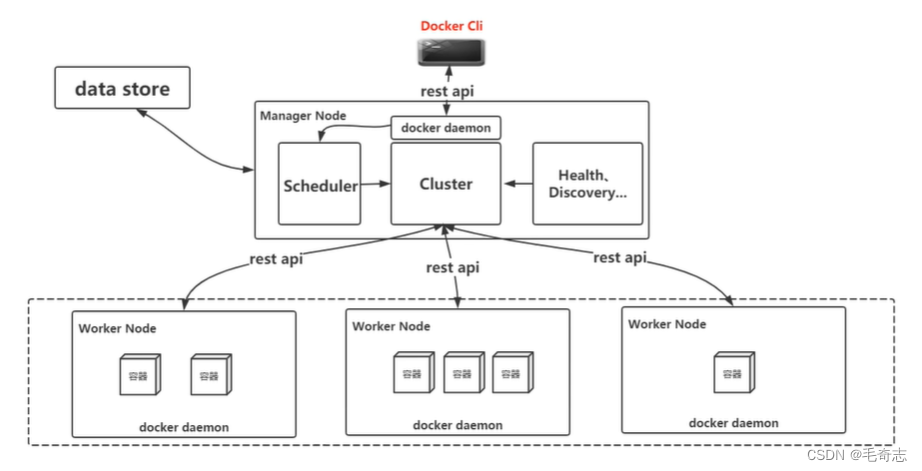
docker swarm 架构设计(了解即可)
四、kubernetes组件和架构简介
4.1 kubernetes组件
本节官方地址(K8S Docs Concepts):https://kubernetes.io/docs/concepts/
4.1.1 Container
(1)先以container为起点,k8s既然是容器编排工具,那么一定会有container
4.1.2 Pod
那k8s如何操作这些container呢?从感性的角度来讲,得要有点逼格,k8s不想直接操作container,因为操作container的事情是docker来做的,k8s中要有自己的最小操作单位,称之为Pod说白了,Pod就是一个或多个Container的组合
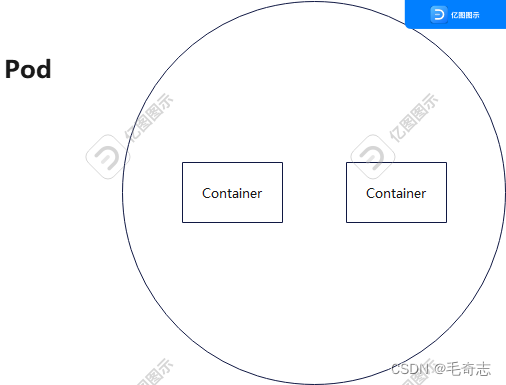
官方解释 :https://kubernetes.io/docs/concepts/workloads/pods/pod/
A Pod (as in a pod of whales or pea pod) is a group of one or more containers (such as Docker containers), with shared storage/network, and a specification for how to run the containers.
4.1.3 ReplicaSet
那Pod的维护谁来做呢?那就是ReplicaSet,通过selector来进行管理
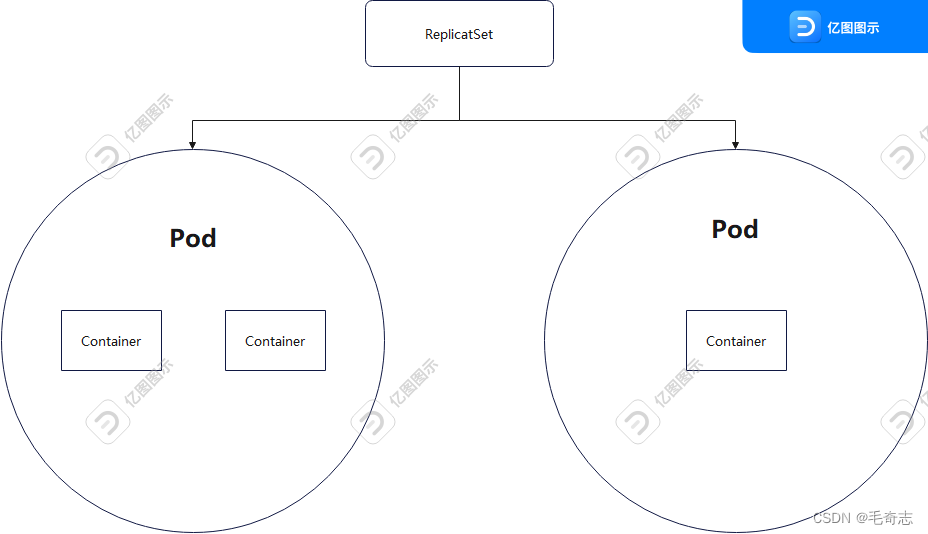
官方解释 :https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/
A ReplicaSet is defined with fields, including a selector that specifies how to identify Pods it can acquire, a number of replicas indicating how many Pods it should be maintaining, and a pod template specifying the data of new Pods it should create to meet the number of replicas criteria.
4.1.4 Deployment
Pod和ReplicaSet的状态如何维护和监测呢?Deployment
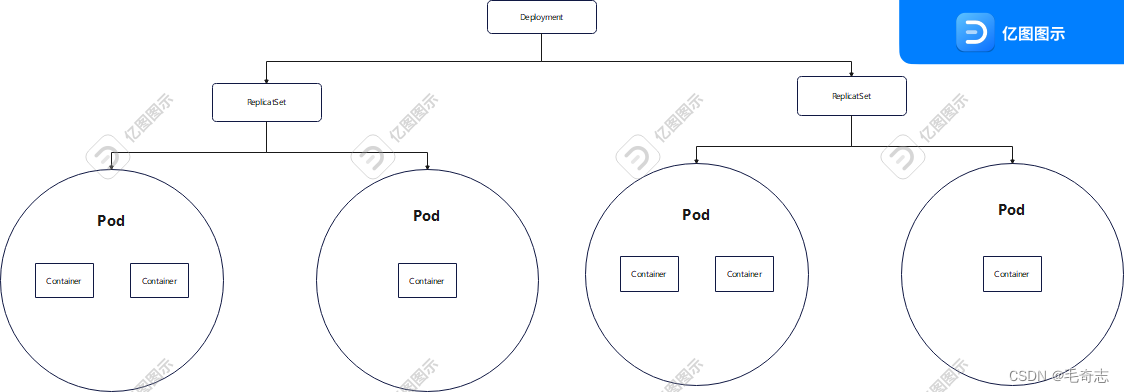
官网是如何描述的 :https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
A Deployment controller provides declarative updates for Pods and ReplicaSets. You describe a desired state in a Deployment, and the Deployment controller changes the actual state to the desired state at a controlled rate. You can define Deployments to create new ReplicaSets, or to remove existing Deployments and adopt all their resources with new Deployments.
4.1.5 Label与Selector
不妨把相同或者有关联的Pod分门别类一下,那怎么分门别类呢?Label
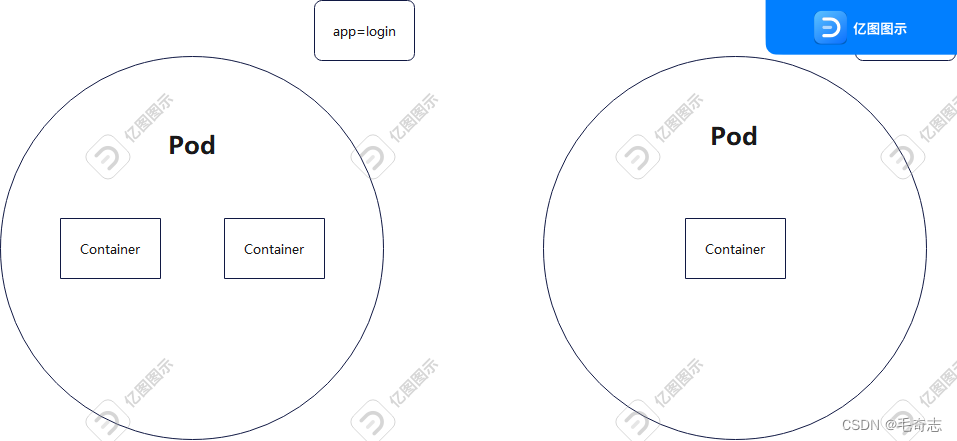
官网是如何描述的 :https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
Labels are key/value pairs that are attached to objects, such as pods.
label 可以在任何类型的资源上,然后用 selector 选择器来选择,比如pod、node,都可以打标签。
4.1.6 Service
具有相同label的service要是能够有个名称就好了,Service
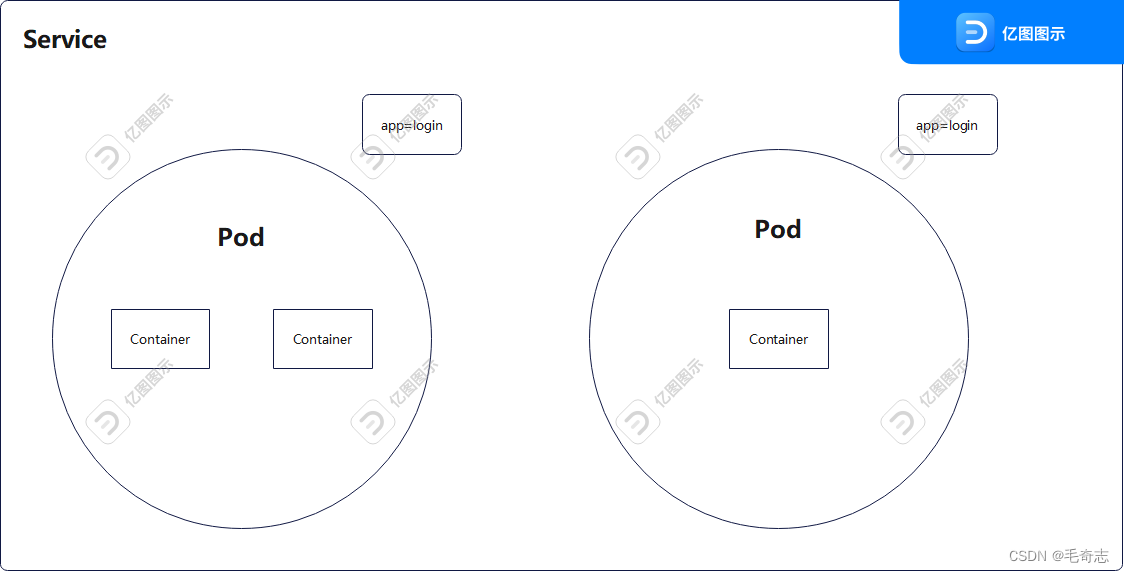
看官网上怎么说 :https://kubernetes.io/docs/concepts/services-networking/service/
An abstract way to expose an application running on a set of Pods as a network service.
With Kubernetes you don’t need to modify your application to use an unfamiliar service discovery mechanism. Kubernetes gives Pods their own IP addresses and a single DNS name for a set of Pods, and can load-balance across them.
4.1.7 Node
上述说了这么多,Pod运行在哪里呢?当然是机器咯,比如一台centos机器,我们把这个机器称作为Node.
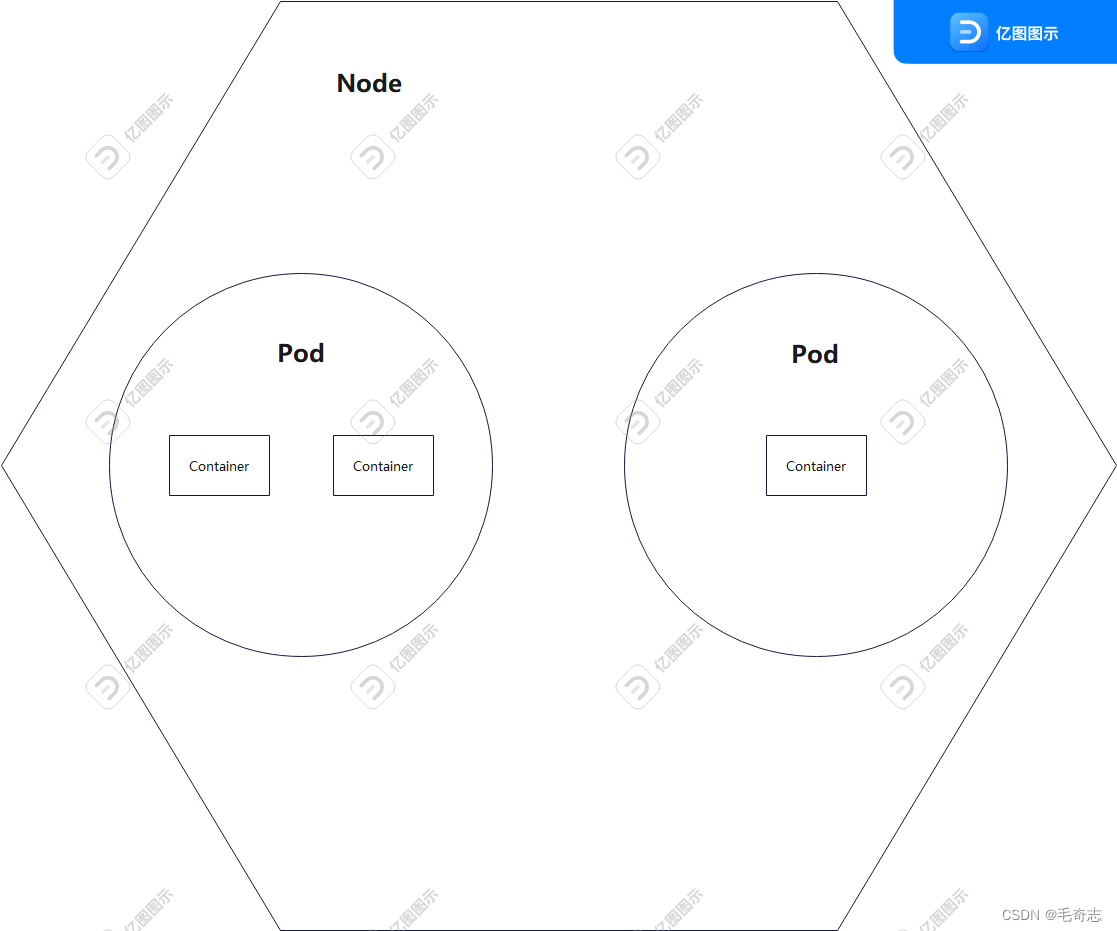
看看官网怎么说 :https://kubernetes.io/docs/concepts/architecture/nodes/
A node is a worker machine in Kubernetes, previously known as a minion. A node may be a VM or physical machine, depending on the cluster. Each node contains the services necessary to run pods and is managed by the master components.
4.1.8 多Node节点组成的集群
难道只有一个Node吗?显然不太合适,多台Node共同组成集群才行嘛
画个图表示一下咯,最好能把之前的Label,Service也一起画上去,整体感受一下
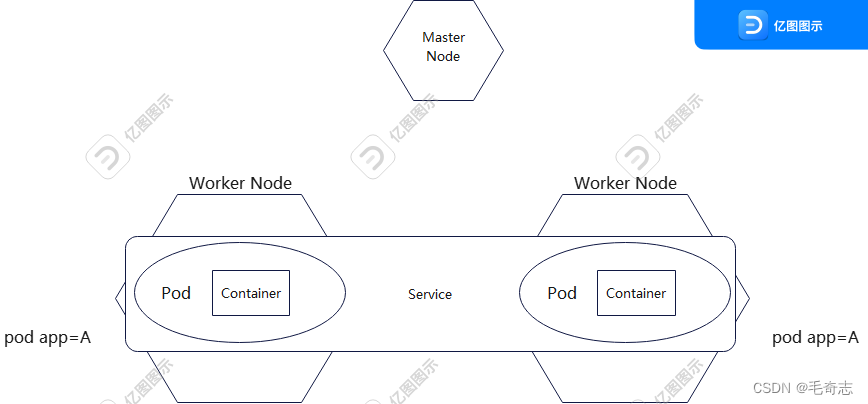
此时,我们把目光转移到由3个Node节点组成的Master-Node集群
4.2 kubernetes架构
这个集群要配合完成一些工作,总要有一些组件的支持吧?接下来我们来想想有哪些组件,然后画一个相对完整的架构图
01-总得要有一个操作集群的客户端,也就是和集群打交道
回答:kubectl,每个集群node上都可以使用kubectl,只要 /root/.kube/config 文件。
02-请求肯定是到达Master Node,然后再分配给Worker Node创建Pod之类的 关键是命令通过kubectl过来之后,是不是要认证授权一下?
回答:Master Node上的apiserver,/etc/kubernetes/manifests目录下有 kube-apiserver.yaml 文件
03-请求过来之后,Master Node中谁来接收?
回答:APIServer
04-API收到请求之后,接下来调用哪个Worker Node创建Pod,Container之类的,得要有调度策略
回答:Master节点的上的静态Pod Scheduler 来负责。
官方资料:https://kubernetes.io/docs/concepts/scheduling/kube-scheduler/
05-Scheduler通过不同的策略,真正要分发请求到不同的Worker Node上创建内容,具体谁负责?
回答: Controller Manager
06-Worker Node接收到创建请求之后,具体谁来负责?
回答:Kubelet服务,最终Kubelet会调用Docker Engine,创建对应的容器[这边也反应出一点,在Node上需要有Docker Engine,才能创建维护容器]
07-会不会涉及到域名解析的问题?
回答:主节点上的CoreDNS服务
08-是否需要有监控面板能够监测整个集群的状态?
回答:Dashboard
09-集群中这些数据如何保存?
回答:分布式存储 ETCD
10-至于像容器的持久化存储,网络等可以联系一下
回答:Docker中的内容
11- 不妨用一个图片总结整个流程
回答:
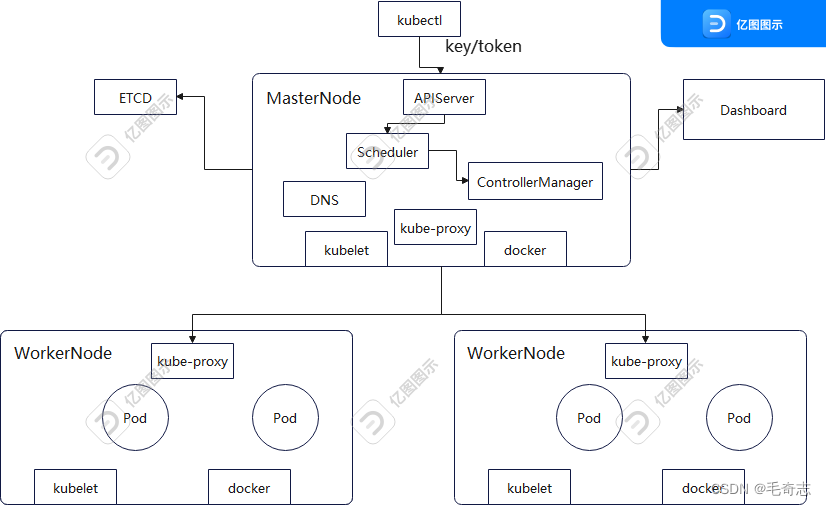
这个图片上告诉我们:
(1) 对于主节点来说,kubectl 连接主节点的所有操作,都必须通过 apiserver 的认证、授权、准入控制,才能正常进行;
(2) 四个静态Pod: apiserver controllerManager scheduler etcd 都是运行在主节点上,apiserver用于认证、打开外网、rbac授权、controllerManager用来管理各种controller,包括 replicaset deployment statefulset daemonset job/cronjob,scheduler决定某个Pod分配哪个Node上,etcd作为配置中心存放数据。
(3) dashboard 提供简单的可视化,完整的可视化还是需要 Prometheus+Grafana 监控
(4) 默认情况下主节点有污点Taint,不分配Pod运行
(5) 每个节点上都会有 kubelet 服务,可以使用 systemctl status kubelet 查看
每个节点上都会有 docker 服务 ,可以使用 systemctl status docker 查看,其作用是将镜像image运行起来变为容器Container
每个节点上都会有 kube-proxy 容器 ,可以使用 kubectl get pod -o wide -n kube-system 查看,其作用是将 kubectl 发送到 service 的请求路由到 具体的Pod 上;
每个节点上都会有 calico/fluend 容器 ,可以使用 kubectl get pod -o wide -n kube-system 查看,其作用Node之间网络通信;
集群一些节点上有 dns 容器,可以使用 kubectl get pod -o wide -n kube-system 查看,其作用使用将 serviceName.namespace 解析为 集群内ip,也可以解析 外网域名,通过配置 /etc/resolv.conf nameserver域名解析服务器列表 和 /etc/hosts 本地域名解析文件来实现。
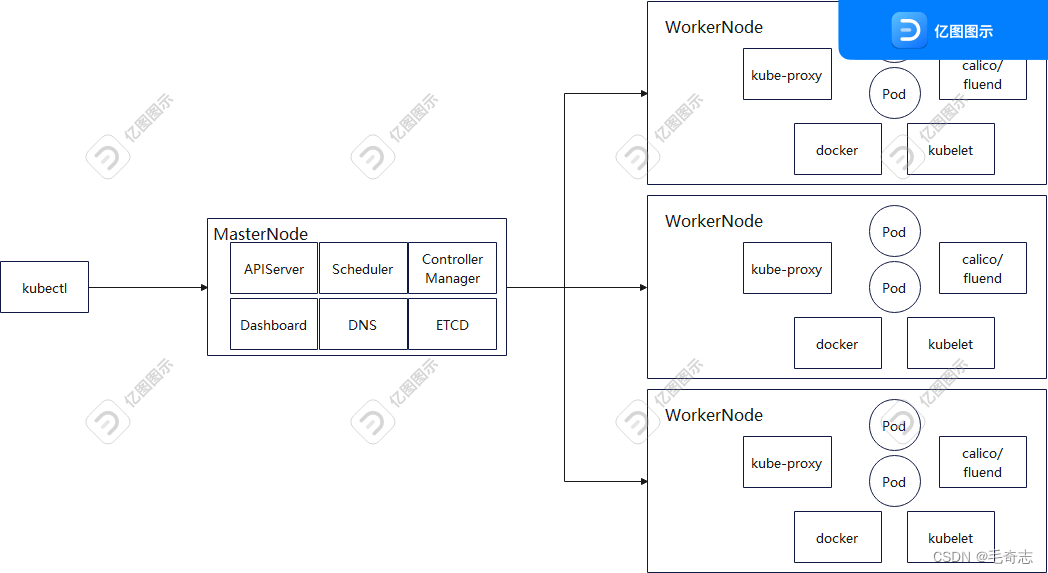
再来一张横向架构图图,加深理解,如下:
五、尾声
从云原生到kubernetes,完成了。
Kubernetes_从云原生到kubernetes的更多相关文章
- 云原生应用 Kubernetes 监控与弹性实践
前言 云原生应用的设计理念已经被越来越多的开发者接受与认可,而Kubernetes做为云原生的标准接口实现,已经成为了整个stack的中心,云服务的能力可以通过Cloud Provider.CRD C ...
- 从零搭建云原生技术kubernetes(K8S)环境-通过kubesPhere的AllInOne方式
前言 k8s云原生搭建,步骤有点多,但通过kubesphere,可以快速搭建k8s环境,同时有一个以 Kubernetes 为内核的云原生分布式操作系统-kubesphere,本文将从零开始进行kub ...
- 云原生生态周报 Vol.9| K8s v1.15 版本发布
本周作者 | 衷源.心贵 业界要闻 1.Kubernetes Release v1.15 版本发布,新版本的两个主题是持续性改进和可扩展性.(https://github.com/kubernetes ...
- 产品对话 | 愿云原生不再只有Kubernete
从2013年,云原生(Cloud Native)的概念由 Pivotal 的 MattStine 首次提出,到现在,其技术细节不断得到社区的完善.云原生逐渐演变出包括 DevOps.持续交付.微服务. ...
- 重大升级!灵雀云发布全栈云原生开放平台ACP 3.0
云原生技术的发展正在改变全球软件业的格局,随着云原生技术生态体系的日趋完善,灵雀云的云原生平台也进入了成熟阶段.近日,灵雀云发布重大产品升级,推出全栈云原生开放平台ACP 3.0.作为面向企业级用户的 ...
- 从Kubernetes到“云原生全家桶”,网易如何让业务部署提效280%?
近日,网易云轻舟微服务团队接受了CNCF的采访,分享了网易云在云原生领域尤其是Kubernetes方面的实践经验.以下为案例全文:公司:网易地点:中国杭州行业:互联网技术 挑战它的游戏业务是世界上最大 ...
- 如何将云原生工作负载映射到 Kubernetes 中的控制器
作者:Janakiram MSV 译者:殷龙飞 原文地址:https://thenewstack.io/how-to-map-cloud-native-workloads-to-kubernetes- ...
- 《Kubernetes与云原生应用》系列之容器设计模式
http://www.infoq.com/cn/articles/kubernetes-and-cloud-native-app-container-design-pattern <Kubern ...
- Kubernetes 入门必备云原生发展简史
作者|张磊 阿里云容器平台高级技术专家,CNCF 官方大使 "未来的软件一定是生长于云上的"这是云原生理念的最核心假设.而所谓"云原生",实际上就是在定义一条能 ...
- Kubernetes v1.16 发布 | 云原生生态周报 Vol. 20
作者:心贵.进超.元毅.心水.衷源.洗兵 业界要闻 Kubernetes v1.16 发布 在这次发布中值得关注的一些特性和 Feature: CRD 正式进入 GA 阶段: Admission We ...
随机推荐
- 【设计模式】Java设计模式 - 动态代理
[设计模式]Java设计模式 - 动态代理 不断学习才是王道 继续踏上学习之路,学之分享笔记 总有一天我也能像各位大佬一样 一个有梦有戏的人 @怒放吧德德 最近工作比较忙,没啥时间学习 目录 [设计模 ...
- KingbaseES R3 集群pcp_attach_node 更新show pool_nodes中节点状态
系统环境: 操作系统: [kingbase@node2 bin]$ cat /etc/centos-release CentOS Linux release 7.2.1511 (Core) 数据库: ...
- 9. 第八篇 kube-controller-manager安装及验证
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247483826&idx=1&sn=88f0cef6 ...
- 使用KubeOperator安装k8s集群后,节点主机yaml文件路径
[root@k8s-develop-master-1 kubernetes]# cd /etc/kubernetes [root@k8s-develop-master-1 kubernetes]# l ...
- 使用 PushGateway 进行数据上报采集
转载自:https://cloud.tencent.com/developer/article/1531821 1.PushGateway 介绍 Prometheus 是一套开源的系统监控.报警.时间 ...
- vscode展示子文件夹
取消勾选设置-功能-compact Folders
- python基本数据类型以及基础运算符
今日分享内容 作业讲解 python基本数据类型 与用户交互 格式化输出 基本运算符 多种赋值方式 逻辑运算符 成员运算符 分享内容详细 # 附加练习题(提示:一步步拆解) # 1.想办法打印出jas ...
- aws-cli命令-S3相关的操作及管理
在工作中,我们可能经常会将本地数据上传S3进行备份,或者将S3数据下载到本地 本文主要讲解下,工作中可能经常会用到的与S3相关的操作 1.将本地目录的数据同步到指定的S3位置,及s3资源管理 # 同步 ...
- 研一入坑Go 文件操作
1 package main 2 3 import ( 4 "fmt" 5 "os" 6 "path" 7 "path/filep ...
- nginx启停shell脚本
#!/bin/bash # 编写 nginx 启动脚本 # 本脚本编写完成后,放置在/etc/init.d/目录下,就可以被 Linux 系统自动识别到该脚本 # 如果本脚本名为/etc/init.d ...