HDFS 伪分布式环境搭建
HDFS 伪分布式环境搭建
作者:Grey
原文地址:
相关软件版本
Hadoop 2.6.5
CentOS 7
Oracle JDK 1.8
安装步骤
在CentOS 下安装 Oracle JDK 1.8
将下载好的 JDK 的安装包 jdk-8u202-linux-x64.tar.gz 上传到应用服务器的/tmp目录下
执行以下命令
cd /usr/local && mkdir jdk && tar -zxvf /tmp/jdk-8u202-linux-x64.tar.gz -C ./jdk --strip-components 1
执行下面两个命令配置环境变量
echo "export JAVA_HOME=/usr/local/jdk" >> /etc/profile
echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile
然后执行
source /etc/profile
验证 JDK 是否安装好,输入
java -version
显示如下内容
'java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
JDK 安装成功。
创建如下目录:
mkdir /opt/bigdata
将 Hadoop 安装包下载至/opt/bigdata目录下
下载方式一
执行:yum install -y wget
然后执行如下命令:cd /opt/bigdata/ && wget https://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
下载方式二
如果报错或者网络不顺畅,可以直接把下载好的安装包上传到/opt/bigdata/目录下
配置静态ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
内容参考如下内容修改
修改BOOTPROTO="static"
新增:
IPADDR="192.168.150.137"
NETMASK="255.255.255.0"
GATEWAY="192.168.150.2"
DNS1="223.5.5.5"
DNS2="114.114.114.114"
然后执行service network restart
设置主机名vi /etc/sysconfig/network
设置为
NETWORKING=yes
HOSTNAME=node01
注:HOSTNAME 自己定义即可,主要要和后面的 hosts 配置中的一样。
设置本机的ip到主机名的映射关系:vi /etc/hosts
192.168.150.137 node01
注:IP 根据你的实际情况来定
重启网络service network restart
执行如个命令,关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
firewall-cmd --reload
service iptables stop
chkconfig iptables off
关闭 selinux:执行vi /etc/selinux/config
设置
SELINUX=disabled
做时间同步yum install ntp -y
修改配置文件vi /etc/ntp.conf
加入如下配置:
server ntp1.aliyun.com
启动时间同步服务
service ntpd start
加入开机启动
chkconfig ntpd on
SSH 免密配置,在需要远程到这个服务器的客户端中
执行ssh localhost
依次输入:yes
然后输入:本机的密码
生成本机的密钥和公钥:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
在服务器上配置免密:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
在客户端再次执行ssh localhost
发现可以免密登录,不需要输入密码了
接下来安装 hadoop 安装包,执行
cd /opt/bigdata && tar xf hadoop-2.6.5.tar.gz
然后执行:
mv hadoop-2.6.5 hadoop
添加环境变量vi /etc/profile
加入如下内容:
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/opt/bigdata/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后执行source /etc/profile
Hadoop 配置
执行vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
配置 JAVA_HOME
export JAVA_HOME=/usr/local/jdk
执行vi $HADOOP_HOME/etc/hadoop/core-site.xml
在<configuration></configuration>节点内配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
执行vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
在<configuration></configuration>节点内配置
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/local/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/local/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name> <value>/var/bigdata/hadoop/local/dfs/secondary</value>
</property>
执行vi $HADOOP_HOME/etc/hadoop/slaves
配置为node01
初始化和启动 HDFS,执行
hdfs namenode -format
创建目录,并初始化一个空的fsimage
如果你使用windows作为客户端,那么需要配置 hosts 条目
进入C:\Windows\System32\drivers\etc
在 host 文件中增加如下条目:
192.168.241.137 node01
注:ip 地址要和你的服务器地址一样
启动 hdfs
执行start-dfs.sh
输入: yes
第一次启动,datanode 和 secondary 角色会初始化创建自己的数据目录
并在命令行执行:
hdfs dfs -mkdir /bigdata
hdfs dfs -mkdir -p /user/root
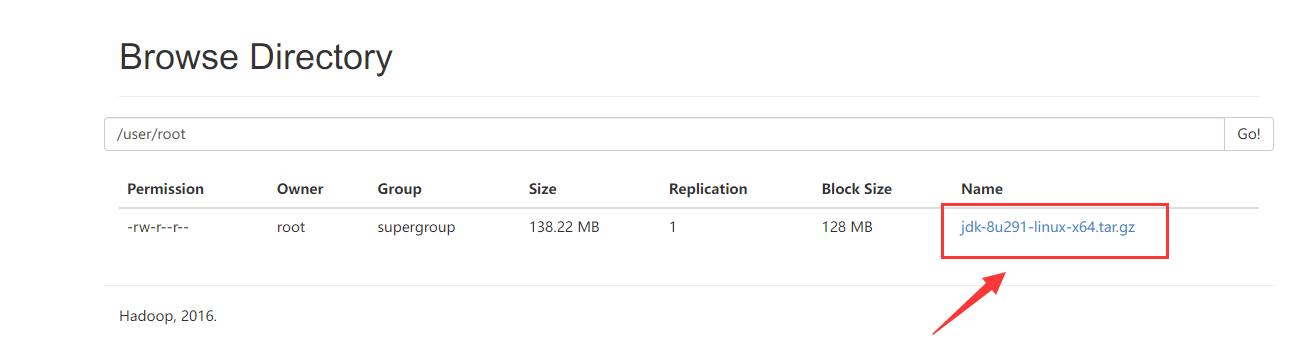
通过 hdfs 上传文件:
hdfs dfs -put jdk-8u291-linux-x64.tar.gz /user/root
通过:http://node01:50070/explorer.html#/user/root
可以看到上传的文件
参考资料
Hadoop MapReduce Next Generation - Setting up a Single Node Cluster.
HDFS 伪分布式环境搭建的更多相关文章
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- HDFS伪分布式环境搭建
(一).HDFS shell操作 以上已经介绍了如何搭建伪分布式的Hadoop,既然环境已经搭建起来了,那要怎么去操作呢?这就是本节将要介绍的内容: HDFS自带有一些shell命令,通过这些命令我们 ...
- Hadoop学习笔记1:伪分布式环境搭建
在搭建Hadoop环境之前,请先阅读如下博文,把搭建Hadoop环境之前的准备工作做好,博文如下: 1.CentOS 6.7下安装JDK , 地址: http://blog.csdn.net/yule ...
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
- 【Hadoop】伪分布式环境搭建、验证
Hadoop伪分布式环境搭建: 自动部署脚本: #!/bin/bash set -eux export APP_PATH=/opt/applications export APP_NAME=Ares ...
- 【Hadoop离线基础总结】CDH版本Hadoop 伪分布式环境搭建
CDH版本Hadoop 伪分布式环境搭建 服务规划 步骤 第一步:上传压缩包并解压 cd /export/softwares/ tar -zxvf hadoop-2.6.0-cdh5.14.0.tar ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- Hadoop 2.7 伪分布式环境搭建
1.安装环境 ①.一台Linux CentOS6.7 系统 hostname ipaddress subnet mask ...
- hive-2.2.0 伪分布式环境搭建
一,实验环境: 1, ubuntu server 16.04 2, jdk,1.8 3, hadoop 2.7.4 伪分布式环境或者集群模式 4, apache-hive-2.2.0-bin.tar. ...
随机推荐
- uniapp使用scroll-view与swiper组件实现tab滑动切换页面需要注意的问题
效果图: tab栏可以滑动,切换页面跟随tab栏同步滑动.这里需要注意的是使用swiper组件时,它会有一个默认的高度,你必须动态的获取数据列表的高度覆盖原来的默认高度. 下面是代码 html < ...
- SAP 实例 9 Text output
REPORT demo_show_text. CLASS demo DEFINITION. PUBLIC SECTION. CLASS-METHODS main. ENDCLASS. CLASS de ...
- leetcode题解#3:无重复字符的最长子串
leetcode题解:无重复字符的最长子串 题目 给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度. 示例 1: 输入: s = "abcabcbb"输出: 3 解释 ...
- 程序分析与优化 - 9 附录 XLA的缓冲区指派
本章是系列文章的案例学习,不属于正篇,主要介绍了TensorFlow引入的XLA的优化算法.XLA也有很多局限性,XLA更多的是进行合并,但有时候如果参数特别多的场景下,也需要进行分割.XLA没有数据 ...
- 记一次requests请求乱码的问题
太懒了,直接说原因吧: 请求返回的内容含有emoji表情 我的解决办法是替换掉emoji字符: 安装库:pip install emoji 替换:emoji.demojize(CONTENT) 注意, ...
- springboot和mybatis 配置多数据源
主数据源(由于代码没有办法复制的原因,下面图片和文字不一致) package com.zhianchen.mysqlremark.toword.config;import com.zaxxer.hik ...
- 从零开始实现lmax-Disruptor队列(五)Disruptor DSL风格API原理解析
MyDisruptor V5版本介绍 在v4版本的MyDisruptor实现多线程生产者后.按照计划,v5版本的MyDisruptor需要支持更便于用户使用的DSL风格的API. 由于该文属于系列博客 ...
- python将命令输出写入文件或临时缓存
python将命令输出写入文件 将文件写入到对应文件,方便后期处理或保存 def write_file(file_path): with open(file=file_path, mode=" ...
- 「APIO2010」巡逻 题解
来源 LCA 个人评价:lca求路径,让我发现了自己不会算树的直径(但是本人似乎没有用lca求) 1 题面 「APIO2010」巡逻 大意:有一个有n个节点的树,每条边权为1,一每天要从1号点开始,遍 ...
- odoo 14 Debug 调试
1 # PDB的用法 2 # PDB是用来调试运行代码的. 3 # 如何启动PDB(启动之后你可以调用odoo任何模块中的方法) 4 # ./odoo-bin shell --log-level=de ...