采用Kettle分页处理大数据量抽取任务
作者:Grey
原文地址: http://greyzeng.com/2016/10/31/big-data-etl/
需求:
将Oracle数据库中某张表历史数据导入MySQL的一张表里面。
源表(Oracle):table1
目标表(MySQL):table2
数据量:20,000,000
思路:
由于服务器内存资源有限,所以,无法使用Kettle一次性从源表导入目标表千万级别的数据,考虑采用分页导入的方式来进行数据传输,即:
根据实际情况设置一个每次处理的数据量,比如:5,000条,然后根据总的数据条数和每次处理的数据量计算出一共分几页,
假设总数据量有:20,000,000,所以页数为:20,000,000/5,000=4,000页
注: 若存在小数,小数部分算一页,比如:20.3算21页
步骤:
根据需求的条件,首先对数据进行分页:
数据量:20,000,000
每页数据量:5,000
页数:4,000
源表(Oracle):table1
目标表(MySQL):table2
主流程:transfer_table1_to_table2.kjb

流程说明:
transfer_table1_to_table2.kjb: 主流程
build_query_page.ktr: 构造页数游标
loop_execute.kjb: 根据页数来执行数据导入操作
我们分别来看各个部分的构成:
build_query_page.ktr: 构造页数游标
这一步中,我们需要构造一个类似这样的数据结构:

其中P_PAGE是表头,其余为页码数,
注: 在这里取页码数我通过这个表的rownum来构造
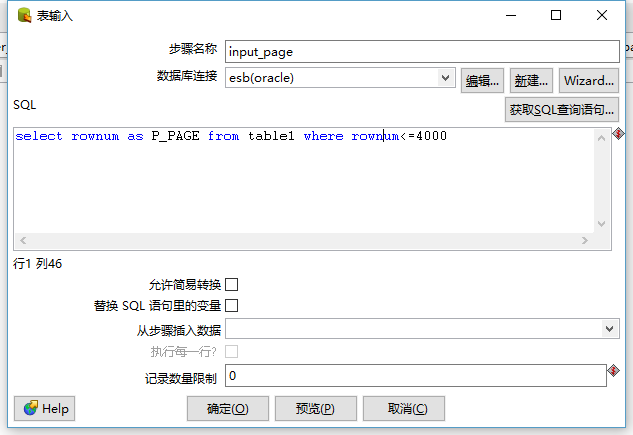
SQL:
select
rownum
as P_PAGE from mds.mds_balances_hist where
rownum<=4000
具体实现如下图:



loop_execute.kjb: 根据页数来执行数据导入操作
在上一步中,我们构造了页数,在这步中,我们遍历上一步中的页码数,通过页码数找出相应的数据集进行操作,
其中包括set_values.ktr和execute_by_page.ktr两个转换
loop_execute.kjb具体实现如下:

set_values.ktr:表示获取从上一步中获得的页数

execute_by_page.ktr:表示根据页数进行数据导入操作
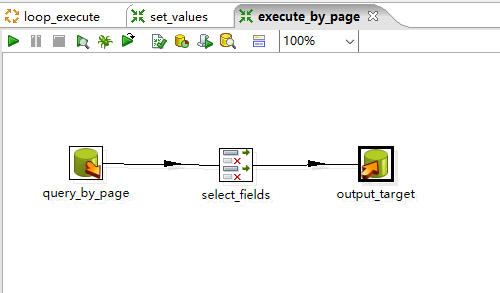
其中query_by_page采用Oracle经典三层嵌套分页算法:
SELECT b.rn,b.* FROM
(
SELECT A.*, ROWNUM RN
FROM (SELECT * FROM table1) A
WHERE
ROWNUM <= (${VAR_P_PAGE}*5000)
) b
WHERE RN >= ((${VAR_P_PAGE}-1)*5000+1)

注: ${VAR_P_PAGE}为每次获取的页码数。
select_field为设置需要导入的列名:


output_target目的是输出到目标表table2:

因为要遍历上一次执行的结果,那么需要在transfer_table1_to_table2.kjb的loop_execute.kjb中做如下设置:

最后,执行transfer_table1_to_table2.kjb即可。
总结:
通过上述方法,我们可以很好的解决内存不足的情况下,大数据量在不同的数据库之间的导入工作。
FAQ:
- 在Kettle导入大量数据的过程中,可能会出现连接断开的现象:
http://forums.pentaho.com/showthread.php?74102-MySQL-connection-settings-at-java-level
(Idle connection timeout if we keep kettle idle for 8hours).
解决办法:

采用Kettle分页处理大数据量抽取任务的更多相关文章
- MySQL分页查询大数据量优化方法
方法1: 直接使用数据库提供的SQL语句 语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N适应场景: 适用于数据量较少的情况(元组百/千级)原因/缺点: ...
- 参考 ZTree 加载大数据量。加载慢问题解析
参考 ZTree 加载大数据量. 1.一次性加载大数据量加载说明 1).zTree v3.x 针对大数据量一次性加载进行了更深入的优化,实现了延迟加载功能,即不展开的节点不创建子节点的 DOM. 2) ...
- 大数据量报表APPLET打印分页传输方案
1 . 问题概述 当报表运算完成时,客户端经常需要调用润乾自带的runqianReport4Applet.jar来完成打印操作, 然而数据量比较大的时候,会导致无法加载完成,直至applet内存 ...
- 大数据量下,分页的解决办法,bubuko.com分享,快乐人生
大数据量,比如10万以上的数据,数据库在5G以上,单表5G以上等.大数据分页时需要考虑的问题更多. 比如信息表,单表数据100W以上. 分页如果在1秒以上,在页面上的体验将是很糟糕的. 优化思路: 1 ...
- MySQL大数据量快速分页实现(转载)
在mysql中如果是小数据量分页我们直接使用limit x,y即可,但是如果千万数据使用这样你无法正常使用分页功能了,那么大数据量要如何构造sql查询分页呢? 般刚开始学SQL语句的时候,会这 ...
- MySQL大数据量分页查询
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- 【1】MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
- mysql大数据量下的分页
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- MySQL大数据量分页查询方法及其优化
MySQL大数据量分页查询方法及其优化 ---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适 ...
随机推荐
- 作业七:团队项目——Alpha版本冲刺阶段-14
组内成员进行测试,对一些小问题进行了修改.
- [ACM_动态规划] Palindrome
http://acm.hust.edu.cn/vjudge/contest/view.action?cid=28415#problem/D 题目大意:给一个长为n的字符串,问最少插入几个字符成回文串 ...
- as3commons-bytecode 获取所有类的一个BUG
下载了这个swc,号称可以反射出所有加载的类.已经用在了spring. 可是一运行就报错,说bytearray.uncompress出错.操. 下载整个源码,单独加载as3commons-byteco ...
- 一个用微软官方的OpenXml读写Excel 目前网上不太普及的方法。
新版本的xlsx是使用新的存储格式,貌似是处理过的XML. 传统的excel处理方法,我真的感觉像屎.用Oldeb不方便,用com组件要实际调用excel打开关闭,很容易出现死. 对于OpenXML我 ...
- Git学习笔记(9)——自定义配置
本文主要记录了Git的一些易用化的配置和别名的使用 配置Git的命令输出带有颜色,更加醒目 //配置输出颜色 $ git config --global color.ui true //取消输出颜色 ...
- UISwitch
UISwitch *noticeSwtich = [[UISwitch alloc] initWithFrame:CGRectMake(0, 0, 51, 31)]; // noticeSwtich. ...
- 如何获得PRINCE2认证
PRINCE2认证考试共有两种:基础级和从业级 一. 基础级考试 基础级考试是一种低水平的认证.如果想要进行从业级考试,必须要参加并通过该考试,或者已经获得pmp资质.基础级考试包括以下关键点: 1. ...
- EF架构~引入规约(Specification)模式,让程序扩展性更强
回到目录 规约(Specification)模式:第一次看到这东西是在microsoft NLayer项目中,它是微软对DDD的解说,就像petshop告诉了我们MVC如何使用一样,这个规约模式最重要 ...
- EF架构~在T4模版中为所有属性加默认值
回到目录 在项目开发过程中,出现了一个问题,就是新添加一个非空字段后,原来的程序逻辑需要被重新修改,即将原来的字段添加到程序里,这种作法是非常不提倡的,所以,我通过T4模版将原来的实体类小作修改,解决 ...
- 使用Sublime Text 2 编辑Markdown
http://www.ituring.com.cn/article/6815 一.安装 下载Sublime Text 2 安装 二.安装Package Control 按Ctrl + ` 打开cons ...