folly::AtomicHashmap源码分析(一)
本文为原创,转载请注明:http://www.cnblogs.com/gistao/
Atomic的两点背景
看下这个场景,老张去厕所,发现门是锁着的,他就在门口等着里边人出来,此时小王也来了,他想了想,决定去楼上的厕所碰碰运气。
如果把门类比为一种竞争资源的话,老张就像mutex,而小王更像atomic,注意是像而已。
atomic跟传统的通过临界区加锁来避免竞争的多线程处理方式来说,它更像是一种状态机编程,根据当前的状态做出相应的逻辑。
而至于是小王还是老张谁先解决内急,无从得知,同样,mutex vs atomic 的性能对比,实测见真知。
atomic支持的数据类型有限,其他信息可以查看之前我的一篇blog:躲不开的多线程。
Atomic是否适合hashmap
hashmap的数据存储一般是array,每个元素按照自己的index(下标)存放,数据结构天然决定了非常适合lock-free(atomic)。
但hashmap有两个'讨厌'的技术点:rehash和probe。
这里的rehash是说当'空间不够时',需要重新申请一块大的内存,并对之前所有的元素重新hash计算,然后确认其新的index,最后
再一次插入的过程。rehash的同时其他操作不能并行,比如查找,试想一下,在高度并发情况下,百万级别元素的rehash操作是多么的糟糕,
当然这与选择atomic无关,并发情况下,最好不要支持rehash功能。
这里probe是说当多个key求数组下标时,冲突不可能完全避免,自然就有了解决冲突算法:probe,probe的效率相应的决定了查找的效率。
在高度并发情况下,开链比线性探查更适合,因为一个桶的冲突不会影响其他桶。当然开链没有线性探查的局部性好,代码也比线性探查复杂,
使用atomic来编写lock-free数据结构显示不是一件容易的事情,所以显然用后者更可控一些。
AtomicHashmap的关键指标
hashmap的关键指标可能是平均查询时间,也可能是较充分的内存利用。但在AtomicHashmap的设计里,我觉得并发执行效率是第一考虑因素,
所以'锁'一定发生在同一个元素操作中。
其他指标应该等同于一般的hashmap。
AtomicHashmap的使用例子
class Counters {
private:
AtomicHashMap<int64_t,int64_t> ahm;
public:
explicit Counters(size_t numCounters) : ahm(numCounters) {}
void increment(int64_t obj_id) {
auto ret = ahm.insert(make_pair(obj_id, ));
if (!ret.first) {
// obj_id already exists, increment
NoBarrier_AtomicIncrement(&ret.first->second, );
}
}
int64_t getValue(int64_t obj_id) {
auto ret = ahm.find(obj_id);
return ret != ahm.end() ? ret->second : ;
}
// Serialize the counters without blocking increments
string toString() {
string ret = "{\n";
ret.reserve(ahm.size() * );
for (const auto& e : ahm) {
ret += folly::to<string>(
" [", e.first, ":", NoBarrier_Load(&e.second), "]\n");
}
ret += "}\n";
return ret;
}
};
AtomicHashmap的实现细节
数据组织结构
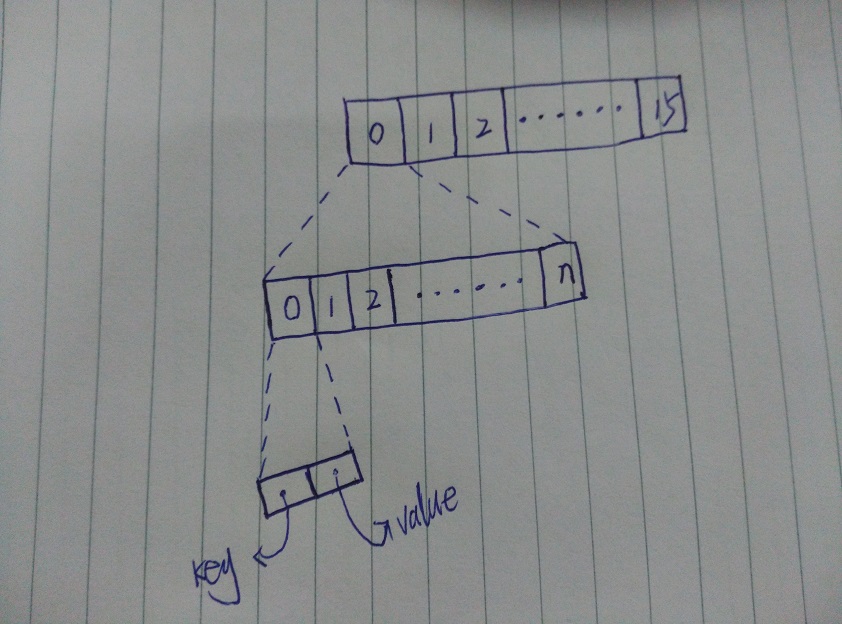
数据为二层组织结构,一级数组存储的是二级数组指针,二级数组为元素的真实存储空间,元素是[key,value]的pair。
类组织结构

AtomicHashMap类主要负责对AtomicHashArray对象的创建和管理,以及接口的封装。
AtomicHashArray是hashmap的实现类:插入、查找、删除
空间初始化
当首次插入时
//容量为size和加载因子的除数
size_t capacity = size_t(maxSize / maxLoadFactor);
size_t sz = sizeof(AtomicHashArray) + sizeof(value_type) * capacity; auto const mem = Allocator().allocate(sz);
//将对象指针绑在mem上
new (mem) AtomicHashArray(capacity, c.emptyKey, c.lockedKey, c.erasedKey,
c.maxLoadFactor, c.entryCountThreadCacheSize); //key全部初始化为empty
FOR_EACH_RANGE(i, , map->capacity_) {
cellKeyPtr(map->cells_[i])->store(map->kEmptyKey_,
std::memory_order_relaxed);
}
当插满时
//根据增长因子确认要分配的大小,要分配的大小<*2
size_t numCellsAllocated = (size_t)
(primarySubMap->capacity_ *
std::pow(1.0 + kGrowthFrac_, nextMapIdx - ));
size_t newSize = (int) (numCellsAllocated * kGrowthFrac_);
//初始化一个新submap
Config config;
config.emptyKey = primarySubMap->kEmptyKey_;
config.lockedKey = primarySubMap->kLockedKey_;
config.erasedKey = primarySubMap->kErasedKey_;
config.maxLoadFactor = primarySubMap->maxLoadFactor();
config.entryCountThreadCacheSize =
primarySubMap->getEntryCountThreadCacheSize();
subMaps_[nextMapIdx].store(SubMap::create(newSize, config).release(),
std::memory_order_relaxed);
插入算法
AtomicHashArray的插入算法
insertInternal(KeyT key_in, T&& value) {
//hash + %size ,获取下标
size_t idx = keyToAnchorIdx(key_in);
size_t numProbes = ;
for (;;) {
value_type* cell = &cells_[idx];
//判断cell是否被使用
if (relaxedLoadKey(*cell) == kEmptyKey_) {
if (isFull_.load(std::memory_order_acquire)) {
//已经满了,就不能插入了
//返回capacity_,告诉AtomicHashMap类:我这个submap不能再插入了
return SimpleRetT(capacity_, false);
} else {
//还没有满
if (tryLockCell(cell)) {
//tryLockCell其实是compare_exchange_strong,即当这个cell的key为empty时
//将empty状态修改为lock状态
new (&cell->second) ValueT(std::forward<T>(value));
//将cell的key字段标记为插入的key
unlockCell(cell, key_in); // Sets the new key
//已经插入的元素>=最大元素时,标记isFull_为true
//最大元素maxEntries_ == 初始化时的参数size
if (numEntries_.readFast() >= maxEntries_) {
isFull_.store(NO_NEW_INSERTS, std::memory_order_relaxed);
}
//插入成功
return SimpleRetT(idx, true);
}
//注意:线程走到这里,说明之前没有成功trylockcell
//线程继续往下走
}
}
if (kLockedKey_ == acquireLoadKey(*cell)) {
//cell还在被锁定,说明其他线程还在插入这个cell
//等待其他线程插入完成
//为什么要等待,因为其他线程插入可能会失败,也可能其他线程和本身线程插入的key一模一样,
//需要特定的逻辑
FOLLY_SPIN_WAIT(
kLockedKey_ == acquireLoadKey(*cell)
);
}
const KeyT thisKey = acquireLoadKey(*cell);
if (EqualFcn()(thisKey, key_in)) {
//比较两个key一样,那本次插入失败,因为之前已经有一个成功插入了
return SimpleRetT(idx, false);
} else if (thisKey == kEmptyKey_ || thisKey == kLockedKey_) {
//两个key不一样,状态又不是插入成功的状态,那么continue了
continue;
}
++numProbes;
if (UNLIKELY(numProbes >= capacity_)) {
//所有的元素空间都遍历一遍了,还是没成功插入,只有失败了
return SimpleRetT(capacity_, false);
}
//线性探测
idx = probeNext(idx, numProbes);
}
}
当AtomicHashArray插入失败,AtomicHashmap会创建一个新的submap,继续插入,周而复始,直至失败。
查找算法
AtomicHashArray的查找算法
findInternal(const KeyT key_in) {
//查找失败,那么遍历查找
for (size_t idx = keyToAnchorIdx(key_in), numProbes = ;
;
idx = probeNext(idx, numProbes)) {
//根据下标,获取key,如果一致,那么查找成功
const KeyT key = acquireLoadKey(cells_[idx]);
if (LIKELY(EqualFcn()(key, key_in))) {
return SimpleRetT(idx, true);
}
//key是个空,说明之前并没有插入过
if (UNLIKELY(key == kEmptyKey_)) {
return SimpleRetT(capacity_, false);
}
++numProbes;
//最坏的情况,全部遍历了一遍,还是没查找,所以失败了
if (UNLIKELY(numProbes >= capacity_)) {
return SimpleRetT(capacity_, false);
}
}
}
这里查找有三个关键点
- 要查的key发生过冲突,那么查找最好的情况是往后遍历一个或者几个找到元素或者发现空元素,然后结束查找,而最坏的情况是遍历查找一遍,当然这种可能性很小,取决于填充因子
- 要查的key并没有插入过,那么最好的情况是遍历到空元素结束,最坏的情况是遍历查找一遍
- 要查的key已经被删除了,这种情况同上
当AtomicHashArray查找失败,AtomicHashmap会寻找下一个被初始化过的submap进行查找,周而复始,直至失败。
删除算法
AtomicHashArray的删除算法
erase(KeyT key_in) {
//遍历删除
for (size_t idx = keyToAnchorIdx(key_in), numProbes = ;
;
idx = probeNext(idx, numProbes)) {
//获取下标的key
value_type* cell = &cells_[idx];
KeyT currentKey = acquireLoadKey(*cell);
//如果key是空的,说明不存在
//如果key正在被插入,那么也是不存在的
if (currentKey == kEmptyKey_ || currentKey == kLockedKey_) {
return ;
}
if (EqualFcn()(currentKey, key_in)) {
//找到了元素
KeyT expect = currentKey;
if (cellKeyPtr(*cell)->compare_exchange_strong(expect, kErasedKey_)) {
numErases_.fetch_add(, std::memory_order_relaxed);
//将key标记为erase
//为什么没有释放内存,为什么不再把key标记为empty
//因为查找的时候,是把value的指针给的用户,没有时机做那些
return ;
}
//别的线程已经搞定了删除,那么本线程返回就可以了
//返回0?应该返回1
return ;
}
//key不一样,说明之前冲突过
//那么遍历往下找吧
++numProbes;
if (UNLIKELY(numProbes >= capacity_)) {
return ;
}
}
}
当AtomicHashArray删除失败,AtomicHashmap会寻找下一个被初始化过的submap进行删除,周而复始,直至失败
AtomicHashmap的限制
- key只支持32和64位
- 当插入元素数量超过初始化的大小后,性能呈线性下降
- 元素被删除后,空间并没有释放,并且不能再次使用
folly::AtomicHashmap源码分析(一)的更多相关文章
- folly::AtomicHashmap源码分析(二)
本文为原创,转载请注明:http://www.cnblogs.com/gistao/ 背景 上一篇只是细致的把源码分析了一遍,而源码背后的设计思想并没有写,设计思想往往是最重要的,没有它,基本无法做整 ...
- ABP源码分析一:整体项目结构及目录
ABP是一套非常优秀的web应用程序架构,适合用来搭建集中式架构的web应用程序. 整个Abp的Infrastructure是以Abp这个package为核心模块(core)+15个模块(module ...
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
- nginx源码分析之网络初始化
nginx作为一个高性能的HTTP服务器,网络的处理是其核心,了解网络的初始化有助于加深对nginx网络处理的了解,本文主要通过nginx的源代码来分析其网络初始化. 从配置文件中读取初始化信息 与网 ...
- zookeeper源码分析之五服务端(集群leader)处理请求流程
leader的实现类为LeaderZooKeeperServer,它间接继承自标准ZookeeperServer.它规定了请求到达leader时需要经历的路径: PrepRequestProcesso ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
- zookeeper源码分析之三客户端发送请求流程
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的 ...
- java使用websocket,并且获取HttpSession,源码分析
转载请在页首注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6238826.html 一:本文使用范围 此文不仅仅局限于spring boot,普通的sprin ...
- ABP源码分析二:ABP中配置的注册和初始化
一般来说,ASP.NET Web应用程序的第一个执行的方法是Global.asax下定义的Start方法.执行这个方法前HttpApplication 实例必须存在,也就是说其构造函数的执行必然是完成 ...
随机推荐
- 《AngularJS权威教程》中关于指令双向数据绑定的理解
在<AngularJS权威教程>中,自定义指令和DOM双向数据绑定有一个在线demo,网址:http://jsbin.com/IteNita/1/edit?html,js,output,具 ...
- Python学习06——列表的操作(2)
笨办法学Python第39节 之前用的第三版的书,昨天发现内容不对,八块腹肌又给我下了第四版,这次的内容才对上.本节的代码如下: ten_things = "Apples Oranges C ...
- 编程key note
一些日常发现的code better的要点.不断更新. * #include <assert.h> 使用断言* 每个模块(文件)应该有一个唯一的一个前缀,模块导出的所有全局名字都应以此前缀 ...
- React之Composition Vs inheritance 组合Vs继承
React的组合 composition: props有个特殊属性,children,组件可以通过props.children拿到所有包含在内的子元素, 当组件内有子元素时,组件属性上的child ...
- range()和xrange()
range(): range([start,] stop[, step]) 如: range(10) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] range()默认起始点为0 且ra ...
- 在非spring组件中注入spring bean
1.在spring中配置如下<context:spring-configured/> <context:load-time-weaver aspectj-weaving=&q ...
- leetcode 日记 4sum java
整体思路同之前的一样,依然采取降低维度的方式进行 public List<List<Integer>> solution(int nums[], int target) { L ...
- a primary example for Functional programming in javascript
background In pursuit of a real-world application, let’s say we need an e-commerce web applicationfo ...
- ASP.NET 缓存技术分析
缓存功能是大型网站设计一个很重要的部分.由数据库驱动的Web应用程序,如果需要改善其性能,最好的方法是使用缓存功能.可能的情况下尽量使用缓存,从内存中返回数据的速度始终比去数据库查的速度快,因而可以大 ...
- iOS socket保持后台连接 ios9.0 xcode8.0
可以保持后台,但申请上架是肯定会被拒的 本教程是基于AsyncSocket库的简单开发! socket机制今天就不说了,毕竟百度上太多太详尽了! 1.先new一个工程: 2.要写socket的界面遵 ...