包含utf8字符的 pickle 转 json的大坑处理过程
背景:希望将pickle转换为json,由于pickle里有utf8的字符,因此转换失败。
转换代码如下:
'''
Convert a pkl file into json file
'''
import sys
import os
import pickle
import json def convert_dict_to_json(file_path):
with open(file_path, 'rb') as fpkl, open('%s.json' % file_path, 'w') as fjson:
data = pickle.load(fpkl)
json.dump(data, fjson, ensure_ascii=False, sort_keys=True, indent=4) def main():
if sys.argv[1] and os.path.isfile(sys.argv[1]):
file_path = sys.argv[1]
print("Processing %s ..." % file_path)
convert_dict_to_json(file_path)
else:
print("Usage: %s abs_file_path" % (__file__)) if __name__ == '__main__':
main()
修正后的代码:因为pickle自身是latin编码,需要转换为utf8再给json编码。
# -*- coding: utf-8 -*- '''
Convert a pkl file into json file
'''
import sys
import os
import pickle
import json
import io def convert_dict_to_json(file_path):
out_file = "vocab_dict.json"
with open(file_path, 'rb') as fpkl, io.open(out_file, 'w', encoding='utf8') as fjson:
data = pickle.load(fpkl)
out_data = data["valid_chars"]
out_data["__MAX_DOC_LEN__"] = data["max_len"]
out_data["__VOLCAB_SIZE__"] = data["volcab_size"]
out = {}
for k,v in out_data.items():
#print k.decode("latin1").encode("utf8")
out[k.decode("latin1").encode("utf8")] = v
data = json.dumps(out, ensure_ascii=False, encoding="utf8", sort_keys=True, indent=4)
fjson.write(data) def main():
if sys.argv[1] and os.path.isfile(sys.argv[1]):
file_path = sys.argv[1]
print("Processing %s ..." % file_path)
convert_dict_to_json(file_path)
else:
print("Usage: %s abs_file_path" % (__file__))
尤其注意:
python2的json是无法处理,包含utf8和unicode两种编码的!比如仅仅包含unicode的可以处理很好:
# -*- coding: utf-8 -*- import json
from codecs import open o = { 'text': u'木村' } with open('foo.json', 'w', encoding= 'utf-8') as fp:
json.dump(o, fp, ensure_ascii= False) with open('foo.json', 'r', encoding= 'utf-8') as fp:
print json.load(fp)['text'].encode('utf-8')
但是:
o = { 'text': u'木村', 'text2': '再加一个utf8的python json就熄火了,会有编码错误异常。。。' }
具体见下文:
python2 json的大坑
介绍一下背景
最近项目中有一个接口,是通过redis队列做的。我将对方需要的数据通过json 字符串的形式,push到redis list队列中,对方监听并消费(题外话, 我对这种形式的交互有点看法吧,双方既然是接口,但是很难保证格式的统一,比使用rpc框架强验证风险大的多)。
由于对端也是用python做的消费者,所以也是相安无事。随着一个需求的变更,我在自己调试pop的数据发现,我写的json字符串是,酱事儿的:
|
1
|
{"title": "\\u6211\\u7231\\u5317\\u4eac\\u5929\\u5b89\\u95e8"}
|
当时我就懵逼了,这是什么鬼…
很显然这个是unicode字符串嘛,但是我明明就编码成了UTF8啦,怎么最后是这个鬼样子,更奇怪的是对方能正确解码吗?这明明是四不像啊。
我试着自己重现了整个过程。
首先,我将utf8形式的字符串 我爱北京天安门 dumps成json:
|
1
2
|
In [10]: json.dumps({"title":"我爱北京天安门"})
Out[10]: '{"title": "\\u6211\\u7231\\u5317\\u4eac\\u5929\\u5b89\\u95e8"}'
|
果然,确实变成了这个样子,看来是json库搞得鬼。
先不管他,看看这个结果load出来什么样子:
|
1
2
|
In [9]: json.loads('{"title": "\\u6211\\u7231\\u5317\\u4eac\\u5929\\u5b89\\u95e8"}')
Out[9]: {u'title': u'\u6211\u7231\u5317\u4eac\u5929\u5b89\u95e8'}
|
确实load没问题,但是可以看到,最后的结果和我当时dumps的出入蛮大的,由原来的utf8 str形式,变为了unicode形式,就连字典的key也都是unicode了。
好吧,所以现在就有了两个问题。
- 为什么utf8字符串, json dumps后不是原来形式?
- 为什么loads回来的数据全是unicode形式?
为什么utf8字符串, json dumps后不是原来形式?
看下官方文档: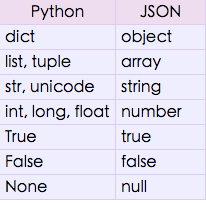
json.dumps方法做的就是将python数据格式按照上图的映射方式转换为json格式。Python
str和unicode都可以转换成json
的string形式,我们知道str和unicode差别很大啊,如果一个python字典中,同时有str和unicode的时候,json
dump怎么处理呢?试一下:
|
1
2
|
In [12]: json.dumps({"title_str":"我爱北京天安门", "title_unicode":u"我爱北京天安门"})
Out[12]: '{"title_unicode": "\\u6211\\u7231\\u5317\\u4eac\\u5929\\u5b89\\u95e8", "title_str": "\\u6211\\u7231\\u5317\\u4eac\\u5929\\u5b89\\u95e8"}'
|
没有异常,并且都是最后按照unicode的方式统一处理的。看来python是先将str decode为unicode,然后再用unicode进行编码的。
这样本来无可厚非,自己统一好编码格式就行了,loads的时候按照编码的方式,反过来解码。但是问题是,和我们进行交互的人未必也用的python啊,当他用其他的语言对json解码的时候,还原回来就是一堆乱码了,我们能不能让json库,确实编码成utf8形式呢?
官方文档如是说:
If ensure_ascii is True (the default), all non-ASCII characters in the output are escaped with \uXXXX sequences, and the results are str instances consisting of ASCII characters only. If ensure_ascii is False, a result may be a unicode instance. This usually happens if the input contains unicode strings or the encoding parameter is used.
看来是 ensure_ascii 参数为 True 的时候,确保了所有非ASCII字符都转义成 \uXXXX 的ASCII序列。
如果我们设置为False,就可以还原本来面目了吗?试试:
|
1
2
|
In [14]: json.dumps({"title_str":"我爱北京天安门"}, ensure_ascii=False)
Out[14]: '{"title_str": "\xe6\x88\x91\xe7\x88\xb1\xe5\x8c\x97\xe4\xba\xac\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8"}'
|
果然哦,我们干脆看看python json库源码怎么实现的吧, 主要就是下列这个判断
|
1
2
3
4
|
200 if self.ensure_ascii:
201 return encode_basestring_ascii(o) # 先将字符串根据encoding参数的编码统一转化为unicode,然后连接字符串
202 else:
203 return encode_basestring(o) # 直接连接字符串
|
既然ensure_ascii = False时, 没有做类型的转换,所以我们原来是什么,编码后就是什么。但这带来了以下副作用:
如果我们要转换的python数据类型,如果既包含str又包含unicode,在连接字符串的时候肯定会抛出编码异常
12In [13]: json.dumps({"title_str":"我爱北京天安门", "title_unicode":u"我爱北京天安门"}, ensure_ascii=False)"UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 1: ordinal not in range(128)"如果全部都是unicode进行字符串连接,返回值也是unicode
12In [3]: json.dumps({"title_str":u"我爱北京天安门", "title":u"我爱世界"}, ensure_ascii=False)Out[3]: u'{"title": "\u6211\u7231\u4e16\u754c", "title_str": "\u6211\u7231\u5317\u4eac\u5929\u5b89\u95e8"}'如果全部都是str进行字符串连接,返回值也是str
12In [2]: json.dumps({"title_str":"我爱北京天安门", "title":"我爱世界"}, ensure_ascii=False)Out[2]: '{"title": "\xe6\x88\x91\xe7\x88\xb1\xe4\xb8\x96\xe7\x95\x8c", "title_str": "\xe6\x88\x91\xe7\x88\xb1\xe5\x8c\x97\xe4\xba\xac\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8"}'
为了能将json字符串通用的和其他语言交换,我们不得不保证,原始python数据类型必须是统一的。要么全是UTF8的str类型,要么全部是unicode,最后在encode为utf8, 否则就会有异常 这个也是动态类型要付出的代价吧。
为什么loads回来的数据全是unicode形式?
看下官方文档: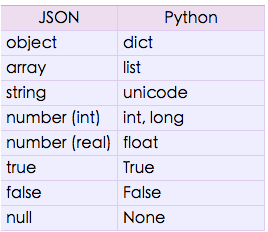
与dumps相反,
json.loads 方法做的就是将json数据格式按照上图的映射方式转换为python类型。我们可以看json string
转换回来只有一种格式,那就是unicode,这样就能解释我们看到的现象了,就连dict key都是unicode的。
好麻烦啊,怎么根本的解决这个问题呢?
答: 使用python3
包含utf8字符的 pickle 转 json的大坑处理过程的更多相关文章
- python 序列化 pickle shelve json configparser
1. 什么是序列化 我们把变量从内存中变成可存储或传输的过程称之为序列化. 序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上. 反过来,把变量内容从序列化的对象重新读到内存里称 ...
- poco json 中文字符,抛异常JSON Exception -->iconv 转换 备忘录。
起因 最近linux服务器通信需要用到json. jsoncpp比较出名,但poco 1.5版本以后已经带有json库,所以决定使用poco::json(linux 上已经用到了poco这一套框架). ...
- php怎么解析utf-8带BOM编码的json数据,php解析json数据返回NULL
今天遇到一个问题,json_decode解析json数据返回null,试了各种方法都不行,最后发现,原来是json文件编码的问题. 当json_decode解析utf-8带BOM格式的json数据时, ...
- UTF-8字符C2A0引起的问题
今天遇到一个问题: 网页上的一段文字中有几个空格,把这段文字当作文件名称保存为一个windows系统下的文件后,文件名中本来是空格的地方变成了问号,另外一个C#程序打开这个文件,也提示找不到文件. 初 ...
- ASCII,Unicode,GBK和UTF-8字符编码的区别和联系
如果经常写python2,肯定会遇到各种“奇怪”的字符编码问题,每次都通过谷歌解决了,但是为什么会造成这种乱码.decode/encode失败等等,本文就字符和字符编码做一个总结,更加清晰区分诸多的编 ...
- mysql查询某一个字段是否包含中文字符
在使用mysql时候,某些字段会存储中文字符,或是包含中文字符的串,查询出来的方法是: SELECT col FROM table WHERE length(col)!=char_length(col ...
- Java检查字符串是否包含中文字符
转自:https://blog.csdn.net/zhanghan18333611647/article/details/80038629 强烈推荐一个大神的人工智能的教程:http://www.ca ...
- FromBase64String 输入的不是有效的 Base-64 字符串,因为它包含非 Base-64 字符、两个以上的填充字符,或者填充字符间包含非法字符
js前台: <input id="upload_img_input" v-on:change="onFileChange" type="file ...
- SQL判断某列中是否包含中文字符、英文字符、纯数字 (转)
一.包含中文字符 select * from 表名 where 列名 like '%[吖-座]%' 二.包含英文字符 select * from 表名 where 列名 like '%[a-z]%' ...
随机推荐
- 正则表达式提取String子串
最近遇到了一个字符串处理的功能,忽然发现了正则表达式的强大,深深的被她的迷人魅力所吸引,以前只是听说,今天亲眼所见,亲身经历,真的彻底折服. 言归正传:java中String类里面封装了很多字符串处理 ...
- shell编程之grep命令的使用
大家在学习正则表达式之前,首先要明确一点,并把它牢牢记在心里,那就是: 在linux中,通配符是由shell解释的,而正则表达式则是由命令解释的,不要把二者搞混了.切记!!! 通常有三种文本处理工具/ ...
- sratookit
sratookit 下载后解压 tar -zxvf sratoolkit.2.8.2-1-ubuntu64.tar.gz 移动到专门安装生物信息软件的目录下 mv sratoolkit.2.8.2-1 ...
- numpy.tile()
numpy.tile()是个什么函数呢,说白了,就是把数组沿各个方向复制 比如 a = np.array([0,1,2]), np.tile(a,(2,1))就是把a先沿x轴(就这样称呼吧)复制 ...
- 洛谷——P4014 分配问题
P4014 分配问题 题目描述 有 nn 件工作要分配给 nn 个人做.第 ii 个人做第 jj 件工作产生的效益为 c_{ij}cij .试设计一个将 nn 件工作分配给 nn 个人做的分配方案, ...
- 网际协议IP简述
最近花了些时间重新回顾了谢希仁教授主编的<计算机网络>关于网络层的章节,这是一本高校教材,里面关于计算机网络的内容比较基础,并且讲的很细致,笔者针对网际协议IP地址部分觉得有必要进行阅读后 ...
- 【JAVA】AES加密
import java.security.SecureRandom; import javax.crypto.Cipher; import javax.crypto.KeyGenerator; imp ...
- Problem 42
Problem 42 https://projecteuler.net/problem=42 The nth term of the sequence of triangle numbers is g ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- PKI 的组成
PKI(Public Key Infrastructure)公钥基础设施是提供公钥加密和数字签名服务的系统或平台,目的是为了管理密钥和证书.一个机构通过采用PKI 框架管理密钥和证书可以建立一个安全的 ...