【转载】深入理解PHP Opcode缓存原理
转载地址:深入理解PHP Opcode缓存原理
什么是opcode缓存?
当解释器完成对脚本代码的分析后,便将它们生成可以直接运行的中间代码,也称为操作码(Operate Code,opcode)。Opcode cache的目地是避免重复编译,减少CPU和内存开销。如果动态内容的性能瓶颈不在于CPU和内存,而在于I/O操作,比如数据库查询带来的磁盘I/O开销,那么opcode cache的性能提升是非常有限的。但是既然opcode cache能带来CPU和内存开销的降低,这总归是好事。
现代操作码缓存器(Optimizer+,APC2.0+,其他)使用共享内存进行存储,并且可以直接从中执行文件,而不用在执行前“反序列化”代码。这将带来显着的性能加速,通常降低了整体服务器的内存消耗,而且很少有缺点。
为什么要使用Opcode缓存?
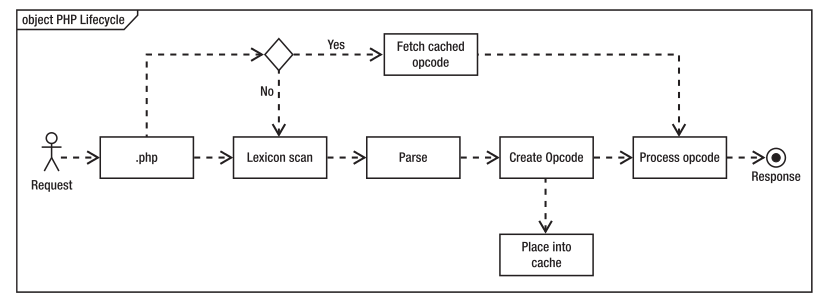
这得从PHP代码的生命周期说起,请求PHP脚本时,会经过五个步骤,如下图所示:

Zend引擎必须从文件系统读取文件、扫描其词典和表达式、解析文件、创建要执行的计算机代码(称为Opcode),最后执行Opcode。每一次请求PHP脚本都会执行一遍以上步骤,如果PHP源代码没有变化,那么Opcode也不会变化,显然没有必要每次都重行生成Opcode,结合在Web中无所不在的缓存机制,我们可以把Opcode缓存下来,以后直接访问缓存的Opcode岂不是更快,启用Opcode缓存之后的流程图如下所示:
有那些PHP opcode缓存插件?
Optimizer+(Optimizer+于2013年3月中旬改名为Opcache,PHP 5.5集成Opcache,其他的会不会消失?)、eAccelerator、xcache、APC ...
PHP opcode原理
Opcode是一种PHP脚本编译后的中间语言,就像Java的ByteCode,或者.NET的MSL,举个例子,比如你写下了如下的PHP代码:
<?php
echo "Hello World";
$a = 1 + 1;
echo $a;
?>
PHP执行这段代码会经过如下4个步骤(确切的来说,应该是PHP的语言引擎Zend)
- Scanning(Lexing) ,将PHP代码转换为语言片段(Tokens)
- Parsing, 将Tokens转换成简单而有意义的表达式
- Compilation, 将表达式编译成Opocdes
- Execution, 顺次执行Opcodes,每次一条,从而实现PHP脚本的功能
题外话:现在有的Cache比如APC,可以使得PHP缓存住Opcodes,这样,每次有请求来临的时候,就不需要重复执行前面3步,从而能大幅的提高PHP的执行速度。
那什么是Lexing? 学过编译原理的同学都应该对编译原理中的词法分析步骤有所了解,Lex就是一个词法分析的依据表。 Zend/zend_language_scanner.c会根据Zend/zend_language_scanner.l(Lex文件),来输入的 PHP代码进行词法分析,从而得到一个一个的“词”,PHP4.2开始提供了一个函数叫token_get_all,这个函数就可以讲一段PHP代码 Scanning成Tokens;
如果用这个函数处理我们开头提到的PHP代码,将会得到如下结果:
Array
(
[0] => Array
(
[0] => 367
[1] => Array
(
[0] => 316
[1] => echo
)
[2] => Array
(
[0] => 370
[1] =>
)
[3] => Array
(
[0] => 315
[1] => "Hello World"
)
[4] => ;
[5] => Array
(
[0] => 370
[1] =>
)
[6] => =
[7] => Array
(
[0] => 370
[1] =>
)
[8] => Array
(
[0] => 305
[1] => 1
)
[9] => Array
(
[0] => 370
[1] =>
)
[10] => +
[11] => Array
(
[0] => 370
[1] =>
)
[12] => Array
(
[0] => 305
[1] => 1
)
[13] => ;
[14] => Array
(
[0] => 370
[1] =>
)
[15] => Array
(
[0] => 316
[1] => echo
)
[16] => Array
(
[0] => 370
[1] =>
)
[17] => ;
)
分析这个返回结果我们可以发现,源码中的字符串,字符,空格,都会原样返回。每个源代码中的字符,都会出现在相应的顺序处。而,其他的比如标签,操作符,语句,都会被转换成一个包含俩部分的Array: Token ID (也就是在Zend内部的改Token的对应码,比如,T_ECHO,T_STRING),和源码中的原来的内容。
接下来,就是Parsing阶段了,Parsing首先会丢弃Tokens Array中的多于的空格,然后将剩余的Tokens转换成一个一个的简单的表达式
echo a constant string
add two numbers together
store the result of the prior expression to a variable
echo a variable
然后就改Compilation阶段了,它会把Tokens编译成一个个op_array, 每个op_arrayd包含如下5个部分:
- Opcode数字的标识,指明了每个op_array的操作类型,比如add , echo
- 结果 存放Opcode结果
- 操作数1 给Opcode的操作数
- 操作数2
- 扩展值1个整形用来区别被重载的操作符
比如,我们的PHP代码会被Parsing成:
- * ZEND_ECHO 'Hello World'
- * ZEND_ADD ~0 1 1
- * ZEND_ASSIGN !0 ~0
- * ZEND_ECHO !0
你可能会问了,我们的$a去那里了?
这个要介绍操作数了,每个操作数都是由以下俩个部分组成:
- op_type : 为IS_CONST, IS_TMP_VAR, IS_VAR, IS_UNUSED, or IS_CV b)
- u,一个联合体,根据op_type的不同,分别用不同的类型保存了这个操作数的值(const)或者左值(var)
而对于var来说,每个var也不一样
IS_TMP_VAR, 顾名思义,这个是一个临时变量,保存一些op_array的结果,以便接下来的op_array使用,这种的操作数的u保存着一个指向变量表的一个句柄(整数),这种操作数一般用~开头,比如~0,表示变量表的0号未知的临时变量
IS_VAR 这种就是我们一般意义上的变量了,他们以$开头表示
IS_CV 表示ZE2.1/PHP5.1以后的编译器使用的一种cache机制,这种变量保存着被它引用的变量的地址,当一个变量第一次被引用的时候,就会被CV起来,以后对这个变量的引用就不需要再次去查找active符号表了,CV变量以!开头表示。
这么看来,我们的$a被优化成!0了。
参考:http://www.laruence.com/2008/06/18/221.html
【转载】深入理解PHP Opcode缓存原理的更多相关文章
- 黄聪:深入理解PHP Opcode缓存原理
什么是opcode缓存? 当解释器完成对脚本代码的分析后,便将它们生成可以直接运行的中间代码,也称为操作码(Operate Code,opcode).Opcode cache的目地是避免重复编译,减少 ...
- 深入理解PHP Opcode缓存原理
什么是opcode缓存? 当解释器完成对脚本代码的分析后,便将它们生成可以直接运行的中间代码,也称为操作码(Operate Code,opcode).Opcode cache的目地是避免重复编译,减少 ...
- 深入了解php opcode缓存原理
什么是opcode opcode(operate code)是计算机指令中的一部分,用于指定要执行的操作,指令的格式和规范由处理器的指定规范指定 opcode是一种php脚本编译后的中间语言,就像ja ...
- php的opcode缓存原理
opcode是什么? 它是一种PHP脚本编译后的中间语言,类似java的字节码. PHP代码执行(Zend引擎)的步骤如下: 1.Scanning(Lexing) ,将PHP代码转换为语言片段(T ...
- ahjesus 前端缓存原理 转载
LAMP缓存图 从图中我们可以看到网站缓存主要分为五部分 服务器缓存:主要是基于web反向代理的静态服务器nginx和squid,还有apache2的mod_proxy和mod_cache模 浏览器缓 ...
- PHP-深入理解Opcode缓存
1.什么是opcode缓存? 当解释器完成对脚本代码的分析后,便将它们生成可以直接运行的中间代码,也称为操作码(Operate Code,opcode).Opcode cache的目地是避免重复编译, ...
- MyBatis 源码分析 - 缓存原理
1.简介 在 Web 应用中,缓存是必不可少的组件.通常我们都会用 Redis 或 memcached 等缓存中间件,拦截大量奔向数据库的请求,减轻数据库压力.作为一个重要的组件,MyBatis 自然 ...
- Atitit 深入理解耦合Coupling的原理与attilax总结
Atitit 深入理解耦合Coupling的原理与attilax总结 耦合是指两个或两个以上的电路元件或电网络等的输入与输出之间存在紧密配合与相互影响,并通过相互作用从一侧向另一侧传输能量的现 ...
- ch01.深入理解C#委托及原理(转)
ch01..深入理解C#委托及原理_<没有控件的ASPDONET> 一.委托 设想,如果我们写了一个厨师做菜方法用来做菜,里面有 拿菜.切菜.配菜.炒菜 四个环节,但编写此方法代码的人想让 ...
随机推荐
- [ACM] POJ 2409 Let it Bead (Polya计数)
参考:https://blog.csdn.net/sr_19930829/article/details/38108871 #include <iostream> #include < ...
- LeetCode算法1—— 两数之和
给定一个整数数组和一个目标值,找出数组中和为目标值的两个数. 你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用. 示例: 给定 nums = [2, 7, 11, 15], target ...
- TCD产品技术参考资料
1.Willis环 https://en.wikipedia.org/wiki/Circle_of_Willis 2.TCD仿真软件 http://www.transcranial.com/index ...
- Quartz,启动不立即执行问题
我的Quartz 是2.2版本, 在java程序中写了两个加入计划方法 //// 添加简单计划任务 author:iresearch.com.cn -- jackical public static ...
- Linux 之vi与vim
vi 三种模式: 『一般模式』: 光标 『编辑模式』:i,o,a,r 『指令列命令模式』「:/ ?」 例子: 1. 请在/tmp 这个目录下建立一个名为vitest 的目录: 2. 将/etc/man ...
- P2966 [USACO09DEC]牛收费路径Cow Toll Paths
P2966 [USACO09DEC]牛收费路径Cow Toll Paths 题目描述 Like everyone else, FJ is always thinking up ways to incr ...
- idea离线安装lombock插件
技术交流群:233513714 安装过程 1.首先找到插件包 插件包可以在两个地方下载,分别是IDEA的官方插件仓库和GitHub里lombok-intellij-plugin仓库中的release包 ...
- OrCAD把原理图中的器件添加到原理图库
1. 在使用OrCAD的时候,有时需要把别人的原理图里面的器件添加到自己的原理图库,方便以后使用,具体操作如下,依次选择Design Cache---元器件--Copy 2. 选中要存放的原理图库,鼠 ...
- c#根据ip获取城市地址
用的API是百度.新浪.淘宝: 1.首先是一个检测获取的值是不是中文的方法,因为有的ip只能识别出来某省,而城市名称则为空返回的json里会出现null或undefined. public stati ...
- Java并发基础--多线程基础
一.多线程基础知识 1.进程和线程 进程:是指一个内存中运行的应用程序,每个进程都有一个独立的内存空间,一个应用程序可以同时运行多个进程:进程也是程序的一次执行过程,是系统运行程序的基本单位:系统运行 ...