Spark搭档Elasticsearch
Spark与elasticsearch结合使用是一种常用的场景,小编在这里整理了一些Spark与ES结合使用的方法。
一、 write data to elasticsearch
利用elasticsearch Hadoop可以将任何的RDD保存到Elasticsearch,不过有个前提其内容可以翻译成文件。这意味着RDD需要一个Map/JavaBean/Scala case class
Scala
在Scala中只需要以下几步:
- Spark Scala imports
- Elasticsearch-hadoop Scala imports
- Start Spark through its Scala API
- makeRDD
- index content(内容索引) index ES under spark/docs
下面是一个例子:

Scala用户可能会使用SEQ和→符号声明根对象(即JSON文件)而不是使用Map。而类似的,第一个符号的结果略有不同,不能相匹配的一个JSON文件:序列是一阶序列(换句话说,一个列表),←会创建一个Tuple(元组),或多或少是一个有序的,元素的定数。例如,一个列表的列表不能作为一个文件,因为它不能被映射到一个JSON对象;但是它可以在一个自由的使用。因此在上面的例子Map(K→V)代替SEQ(K→V)
作为一种替代上面的隐式导入,elasticsearch-hadoop支持spark的Scala用户通过org.elasticsearch.spark.rdd包作为实用类允许显式方法调用EsSpark。此外,而不是地图(这是方便,但需要一个映射,每个实例,由于它们的结构的差异),使用一个case class:
- EsSpark importrs
- 定义一个Case class名叫Trip
- 利用Trip实例创建一个RDD
- 明确RDD的index通过EsSpark
例子:

对于指定documents的id(或者其他类似于TTL或时间戳的元数据),可以设置名字为es.mapping.id的映射。下面以前的实例,Elasticsearch利用filed的id作为documents的id.更新RDD的配置configuration(也可以在SparkConf上设置全局的属性,不建议这样做)

Writing existing to Elasticsearch
如果Rdd的数据已经在Json中,elasticsearch-hadoop允许直接索引而不需要任何转换,数据直接发送到Elasticsearch.这时候elasticsearch-hadoop希望RDD包含字符或者字节数组(string[]/byte[]),假设每个条目代表一个JSON文档。如果RDD没有正确的签名,这savejsontoes方法无法应用(在Scala中他们将不可用)。
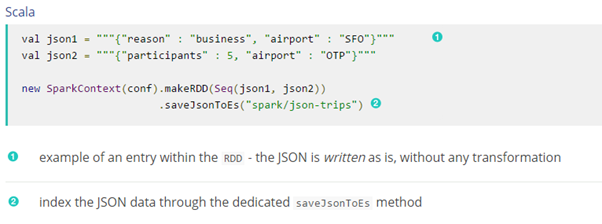
Writing to dynamic/multi-resources
当被写入ES的数据需要索引不同的buckets,可以利用es.resource.write,下面media的例子配置如下:

- 用于拆分数据的文档。任何字段都可以被声明(但要确保它在所有的文件中都是可用的)
- 保存每个对象根据其资源的模式,在这个例子的基础上media_type
每个文档或者对象被写入,Elasticsearch Hadoop将提取media_type字段,使用它的值来确定目标资源。
Handling document metadata
Elasticsearch允许每个文档有自己的元数据(metadata),正如上面所解释的,通过各种映射选项可以自定义这些参数,以便他们的值是从他们的归属文档中提取。我们甚至可以包括/排除哪些部分数据被备份到Elasticsearch,在Spark中,Elasticsearch Hadoop扩展此功能允许将元数据提供的外部文档本身给pair RDDS用。另一方面,对于包含key-value元组的RDDS,metadata可以从作为文档源的key-value中提取。

当有更多的Id需要被指定时,可以使用scala.collection.Map来接收 org.elasticsearch.spark.rdd.Metadata的key的类型:
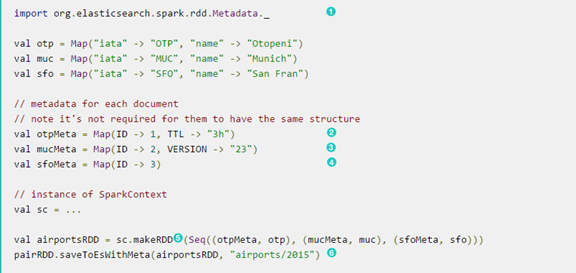
当有更多的Id需要被指定时,可以使用ava.util.Map来接收 org.elasticsearch.spark.rdd.Metadata的key的类型:

二、 Reading data from elasticsearch
读数据需要定义一个EsRDD,将数据流从ES读到Spark

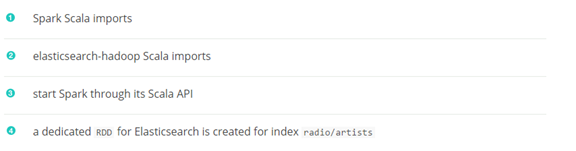
该方法可以被重载来指定一个额外的查询或配置图(overriding sparkconf):
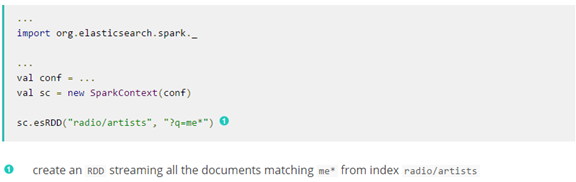
从Elasticsearch返回的文件,默认情况下,作为一个tuple2,包含第一个元素是文档ID和第二个元素实际文件通过Scala集合来表示,名字类似于Map[Sting,Any],其中key是字段名称和value是各自的值。
elasticsearch-hadoop自动转换spark内置类型作为Elasticsearch类型,如下表: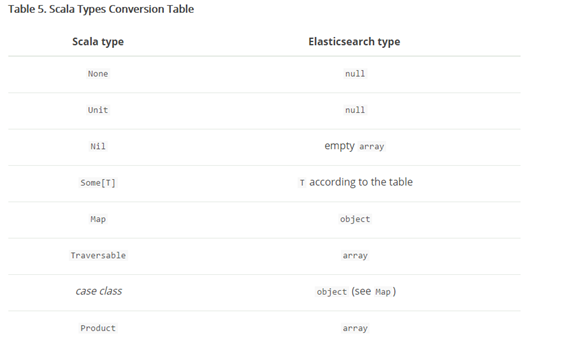
SaprkSQL on support
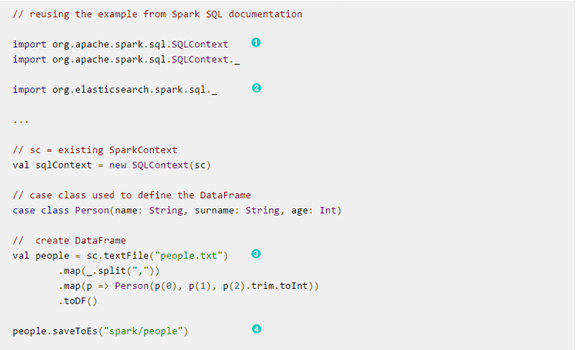
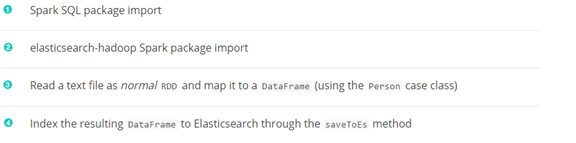
直接看下面的例子:
Spark搭档Elasticsearch的更多相关文章
- 使用spark访问elasticsearch的数据
使用spark访问elasticsearch的数据,前提是spark能访问hive,hive能访问es http://blog.csdn.net/ggz631047367/article/detail ...
- Spark 整合ElasticSearch
Spark 整合ElasticSearch 因为做资料搜索用到了ElasticSearch,最近又了解一下 Spark ML,先来演示一个Spark 读取/写入 ElasticSearch 简单示例. ...
- 数据湖应用解析:Spark on Elasticsearch一致性问题
摘要:脏数据对数据计算的正确性带来了很严重的影响.因此,我们需要探索一种方法,能够实现Spark写入Elasticsearch数据的可靠性与正确性. 概述 Spark与Elasticsearch(es ...
- spark操作elasticsearch数据的限制
对于复杂的数据类型,比如IP和GeoPoint,只是在elasticsearch中有效,用spark读取时会转换成常用的String类型. Geo types. It is worth mention ...
- 使用spark与ElasticSearch交互
使用 elasticsearch-hadoop 包,可在 github 中搜索到该项目 项目地址 example import org.elasticsearch.spark._ import org ...
- spark对elasticsearch增删查改
增 新建一个 dataframe ,插入到索引 _index/_type ,直接调用 saveToEs ,让 _id 为自己设定的 id: import org.elasticsearch.spark ...
- spark 集成elasticsearch
pyspark读写elasticsearch依赖elasticsearch-hadoop包,需要首先在这里下载,版本号可以通过自行修改url解决. """ write d ...
- 用 Spark 为 Elasticsearch 导入搜索数据
越来越健忘了,得记录下自己的操作才行! ES和spark版本: spark-1.6.0-bin-hadoop2.6 Elasticsearch for Apache Hadoop 2.1.2 如果是其 ...
- 分布式处理与大数据平台(RabbitMQ&Celery&Hadoop&Spark&Storm&Elasticsearch)
热门的消息队列中间件RabbitMQ,分布式任务处理平台Celery,大数据分布式处理的三大重量级武器:Hadoop.Spark.Storm,以及新一代的数据采集和分析引擎Elasticsearch. ...
随机推荐
- 【luogu P2319 [HNOI2006]超级英雄】 题解
题目链接:https://www.luogu.org/problemnew/show/P2319 #include <cstdio> #include <cstring> #i ...
- 【luogu P3376 网络最大流】 模板
题目链接:https://www.luogu.org/problemnew/show/P3376 #include <iostream> #include <cstdio> # ...
- 将某页面中ajax中获取到的信息放置到sessionStorage中保存,并在其他页面调用这些数据。
A页面代码: var obj = data.data; var infostr = JSON.stringify(obj);//转换json sessionStorage.obj = infostr; ...
- sudo cd的错误
问题说明 今天用MySQL建了库,想看看. 当到了这步,心里的第一个感觉就是电脑坏了.后来查了查才知道了原因. 原因 cd不是一个应用程序而是Linux内建的命令,而sudo仅仅只对应用程序起作用. ...
- Centos6.9 安装Oracle11gR2
最近在学习怎么安装Centos,在Centos6.9版本安装Oracle数据库.参考了网络上很多文章,终于可以不报错的完成安装了,在这里记录一下 一.需要用到的安装文件 Centos6.9 ps: ...
- BigDecimal运算(加、减、乘、除)
public class BigDecimalOperation { private BigDecimalOperation(){ } public static BigDecimal add(dou ...
- 构建高可靠hadoop集群之2-机栈
本文主要参考 http://hadoop.apache.org/docs/r2.8.0/hadoop-project-dist/hadoop-common/RackAwareness.html had ...
- MySQL 修改主键
网上顺便查了下 ,要先删除 再创建,如果是添加复合主键,则复合主键值不能为空 alter table table_name drop primary key; alter table table_na ...
- spring的事务处理
说到事务,无非就是事务的提交commit和回滚rollback. 事务是一个操作序列,这些操作要么全部都执行成功,事务去提交,要么就是有一个操作失败,事务去回滚. 要知道事务的4大特性ACID.即原子 ...
- 批处理,%~d0 cd %~dp0 代表什么意思
批处理,%~d0 cd %~dp0 代表什么意思 ~dp0 “d”为Drive的缩写,即为驱动器,磁盘.“p”为Path缩写,即为路径,目录cd是转到这个目录,不过我觉得cd /d %~dp0 还 ...