4.flask数据库
1.安装MySQL
直接去下载即可,如果是windows建可以下载msi,一路next即可。我已经安装过了,这里就不再演示了。
最后使用Navicat连接测试一下,我这里是没有问题的
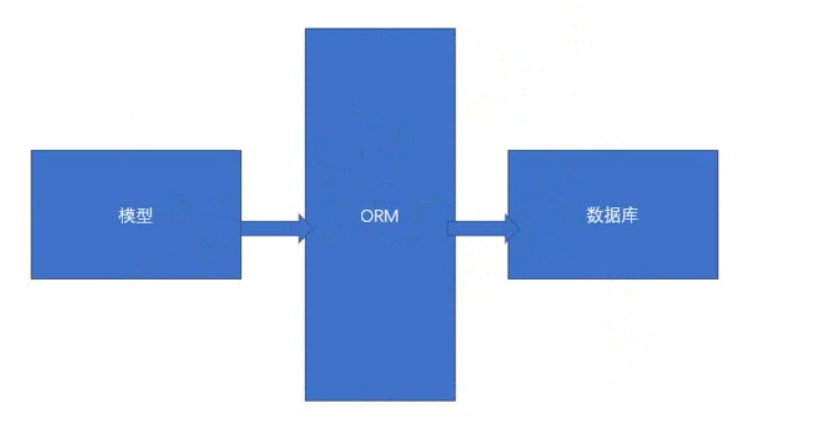
2.SQLAlchemy的介绍和基本使用
sqlalchemy是一款orm框架
注意:SQLAlchemy本身是无法处理数据库的,必须依赖于第三方插件,比方说pymysql,cx_Oracle等等
SQLAlchemy等于是一种更高层的封装,里面封装了许多dialect(相当于是字典),定义了一些组合,比方说: 可以用pymysql处理mysql,也可以用cx_Oracle处理Oracle,关键是程序员使用什么 然后会在dialect里面进行匹配,同时也将我们高层定义的类转化成sql语句,然后交给对应的DBapi去执行。
除此之外,SQLAlchemy还维护一个数据库连接池,数据库的链接和断开是非常耗时的 SQLAlchemy维护了一个数据库连接池,那么就可以拿起来直接用
首先要安装sqlalchemy和pymysql,直接pip install 即可
我在mysql新建了一个名为satori的数据库
# 连接数据库需要创建引擎
from sqlalchemy import create_engine
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
# 连接方式:数据库+驱动://用户名:密码@ip:端口/数据库
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
# 测试连接是否成功
conn = engine.connect()
# 我们直接可以使用conn去获取数据
data = conn.execute("show databases")
print(data.fetchall()) # [('information_schema',), ('mysql',), ('performance_schema',), ('sakila',), ('satori',), ('sys',), ('world',)]
显然是可以获取成功的
3.orm介绍
orm: object relation mapping,就是可以把我们写的类转化成表。将类里面的元素映射到数据库表里面
4.定义orm模型并映射到数据库中
from sqlalchemy import create_engine
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
# 需要以下步骤
'''
1.创建一个orm模型,这个orm模型必须继承SQLAlchemy给我们提供好的基类
2.在orm中创建一些属性,来跟表中的字段进行一一映射,这些属性必须是SQLAlchemy给我们提供好的数据类型
3.将创建好的orm模型映射到数据库中
'''
# 1.创建orm,继承基类
from sqlalchemy.ext.declarative import declarative_base
# 这个declarative_base只是一个函数,我们需要传入engine,然后返回基类
Base = declarative_base(engine)
class Girls(Base):
# 首先是表名,创建表要指定名字,如何指定呢?
__tablename__ = "girls" # __tablename__就是我们的表名,我们指定为girls
# 2.创建属性,来跟表中的字段一一映射
# 首先我们需要有列,还要有字段的属性。注意:我这里是为了演示,工作中要写在开头。
from sqlalchemy import Column, Integer, String
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(30)) # String也是一个类,里面可以传入数字表示最多可以存多少字节的字符串
age = Column(Integer)
gender = Column(String(1))
anime = Column(String(50))
# 3.创建完毕,那么接下来就要映射到数据库中
Base.metadata.create_all() # 表示将Base的所有子类的模型映射到数据库中,一旦映射,即使改变模型之后再次执行,也不会再次映射。
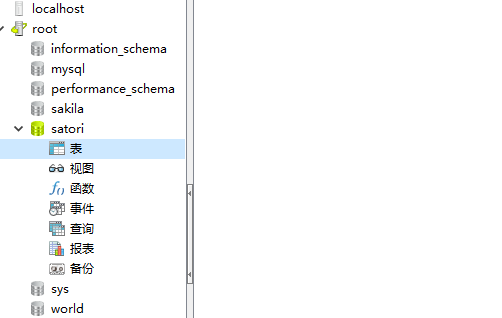
此时里面还没有表,我们执行一下看看
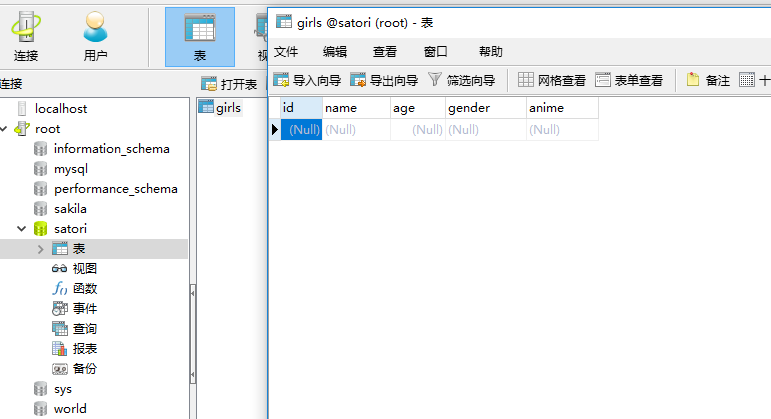
我们刚才创建的表已经在里面了
5.SQLAlchemy对数据的增删改查操作
from sqlalchemy import create_engine
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
class Girls(Base):
__tablename__ = "girls"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(30))
age = Column(Integer)
gender = Column(String(1))
anime = Column(String(50))
# 实例化一个对象,是用来增删改查数据的
girls =Girls()
# 会得到一个Session类
Session = sessionmaker(bind=engine)
# 然后实例化得到一个Session对象,这个session使用来提交操作的
session = Session()
增:
girls.name = "satori"
girls.age = 16
girls.gender = "f"
girls.anime = "东方地灵殿"
# 这两步表示将girls做的操作全部提交上去执行
session.add(girls)
session.commit()
# 也可以批量操作
session.add_all([Girls(name="koishi", age=15, gender="f", anime="东方地灵殿"),
Girls(name="mashiro", age=16, gender="f", anime="樱花庄的宠物女孩"),
Girls(name="matsuri", age=400, gender="f", anime="sola"),
Girls(name="kurisu", age=20, gender="f", anime="命运石之门")])
session.commit()

查:
# session.query得到的是一个query对象,调用filter_by依旧是一个query对象 # 调用first方法获取第一条查询记录,如果不存在则为None girls = session.query(Girls).filter_by(gender="f").first() print(girls.name, girls.age, girls.anime) # satori 16 东方地灵殿
改:
# 改和查比较类似 # 还是先获取相应的记录 girls = session.query(Girls).filter_by(gender="f").first() # 直接修改即可 girls.name = "古明地觉" # 一旦涉及到数据的变更,那么就必须要进行提交,查不涉及所以不需要 # 如何提交呢?我们只是改,所以不需要add,直接使用commit即可 session.commit()
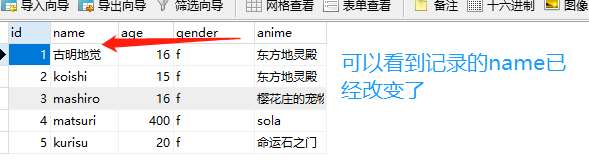
删:
# 筛选出要删除的字段 girl = session.query(Girls).filter_by(name="古明地觉").first() # 添加用add,删除用delete session.delete(girl) # 别忘了提交 session.commit()

6.SQLAlchemy属性常用数据类型
SQLAlchemy常用数据类型:
Integer:整形,映射到数据库是int类型
Float:浮点型,映射到数据库是float类型,占32位。
Boolean:布尔类型,传递True or False,映射到数据库是tinyint类型
DECIMAL:顶点类型,一般用来解决浮点数精度丢失的问题
Enum:枚举类型,指定某个字段只能是枚举中指定的几个值,不能为其他值,
Date:传递datetime.date()进去,映射到数据库中是Date类型
DateTime:传递datetime.datetime()进去,映射到数据库中也是datatime类型
String:字符类型,映射到数据库中varchar类型
Text:文本类型,可以存储非常长的文本
LONGTEXT:长文本类型(只有mysql才有这种类型),可以存储比Text更长的文本
7.Column常用参数
default:默认值,如果没有传值,则自动为我们指定的默认值
nullable:是否可空,False的话,表示不可以为空,那么如果不传值则报错
primary_key:是否为主键
unique:是否唯一,如果为True,表示唯一,那么传入的值存在的话则报错
autoincrement:是否自动增长
name:该属性在数据库中的字段映射,如果不写,那么默认为赋值的变量名。
8.query查询
1.模型,指定查找这个模型中所有的对象
2.模型中的属性,可以指定查找模型的某几个属性
3.聚合函数
func.count:统计行的数量
func.avg:求平均值
func.max:求最大值
func.min:求最小值
func.sum:求总和
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, func
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
# 以上这些都是必须的
class Girls(Base):
__tablename__ = "girls"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(30))
age = Column(Integer)
gender = Column(String(1))
anime = Column(String(50))
# 以后就不会打印一个query对象了,而是会打印返回值
def __repr__(self):
return f"{self.name}--{self.age}--{self.anime}"
Session = sessionmaker(bind=engine)
session = Session()
# 这里指定了Girls,也就是模型,那么会查找所有的模型对象
for girl in session.query(Girls).all():
print(girl)
'''
koishi--15--东方地灵殿
mashiro--16--樱花庄的宠物女孩
matsuri--400--sola
kurisu--20--命运石之门
'''
# 但如果我不想要所有属性,而是要部分属性怎么办呢?比如我只想要name和age,就可以这样
# 会获取一个有元组组成的字典
print(session.query(Girls.name, Girls.age).all()) # [('koishi', 15), ('mashiro', 16), ('matsuri', 400), ('kurisu', 20)]
# 聚合函数
# 得到query对象虽然只有一条数据,但还是要加上first
print(session.query(func.count(Girls.name)).first()) # (4,)
print(session.query(func.avg(Girls.age)).first()) # (Decimal('112.7500'),)
print(session.query(func.max(Girls.age)).first()) # (400,)
print(session.query(func.min(Girls.age)).first()) # (15,)
print(session.query(func.sum(Girls.age)).first()) # (Decimal('451'),)
9.filter方法常用过滤条件
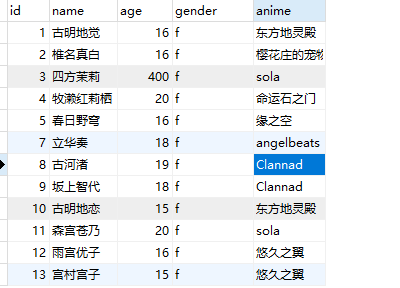
为了方便演示,我这里有多建了几条数据
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
class Girls(Base):
__tablename__ = "girls"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(30))
age = Column(Integer)
gender = Column(String(1))
anime = Column(String(50))
# 以后就不会打印一个query对象了,而是会打印返回值
def __repr__(self):
return f"{self.name}--{self.age}--{self.anime}"
Session = sessionmaker(bind=engine)
session = Session()
# 关于过滤,有两种方法,一种是filter,另一种是filter_by
# filter需要使用类名.属性的方式,filter_by只需要属性即可,这就意味着后者使用简单,但前者可以写出更复杂的查询
# 下面来看看都有哪些查询方法
# 1、==,由于可能有多条,我们只选择一条。
print(session.query(Girls).filter(Girls.age == 16).first()) # 古明地觉--16--东方地灵殿
# 2、!=
print(session.query(Girls).filter(Girls.age != 16).first()) # 四方茉莉--400--sola
# 3、like,%和sql里的一样。除此之外还要ilike,不区分大小写
print(session.query(Girls).filter(Girls.anime.like("%久%")).all()) # [雨宫优子--16--悠久之翼, 宫村宫子--15--悠久之翼]
# 4、in_,至于为什么多了多了一个_,这个bs4类似,为了避免和python里的关键字冲突。为什么不是_in,如果放在前面那代表不想被人访问
print(session.query(Girls).filter(Girls.age.in_([16, 400])).all()) # [古明地觉--16--东方地灵殿, 椎名真白--16--樱花庄的宠物女孩, 四方茉莉--400--sola, 春日野穹--16--缘之空, 雨宫优子--16--悠久之翼]
# 5、notin_,等价于~Girls.age.in_()
print(session.query(Girls).filter(Girls.age.notin_([16, 20, 400])).all()) # [立华奏--18--angelbeats, 古河渚--19--Clannad, 坂上智代--18--Clannad, 古明地恋--15--东方地灵殿, 宫村宫子--15--悠久之翼]
# 6、isnull
print(session.query(Girls).filter(Girls.age is None).first()) # None
# 7、isnotnull
print(session.query(Girls).filter(Girls.age is not None).first()) # 古明地觉--16--东方地灵殿
# 8、and
print(session.query(Girls).filter(and_(Girls.age == 16, Girls.anime == "樱花庄的宠物女孩")).first()) # 椎名真白--16--樱花庄的宠物女孩
# 9、or
print(session.query(Girls).filter(or_(Girls.age == 15, Girls.anime == "悠久之翼")).all()) # [古明地恋--15--东方地灵殿, 雨宫优子--16--悠久之翼, 宫村宫子--15--悠久之翼]
10.外键及其四种约束
在mysql中,外键可以使表之间的关系更加紧密。而SQLAlchemy中也同样支持外键,通过ForforeignKey来实现,并且可以指定表的外键约束
外键约束有以下几种:
1.RESTRICT:父表数据被删除,会阻止删除
2.NO ACTION:在mysql中,等同于RESTRICT
3.CASCADE:级联删除
4.SET NULL:父表数据被删除,zishuju字表数据会跟着删除,也就是设置为NULL
既然如此的话,我们是不是要有两张表啊,我这里新创建两张表
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import sessionmaker
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
# 我现在新建两张表
# 表People--表language ==》父表--子表
class People(Base):
__tablename__ = "People"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
class Language(Base):
__tablename__ = "Language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(String(20), nullable=False)
# 这个pid指的是People里面的id,所以要和People里的id保持一致
pid = Column(Integer, ForeignKey("People.id")) # 引用的表.引用的字段
Base.metadata.create_all()
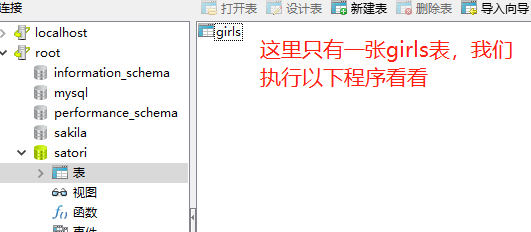
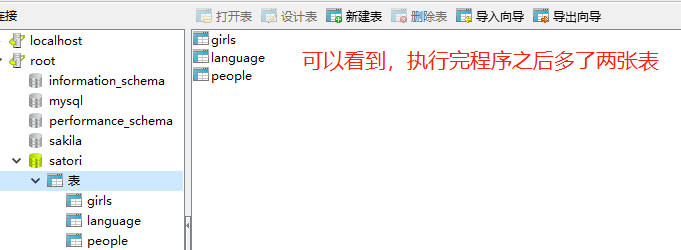
我们也可以看看表的创建语法
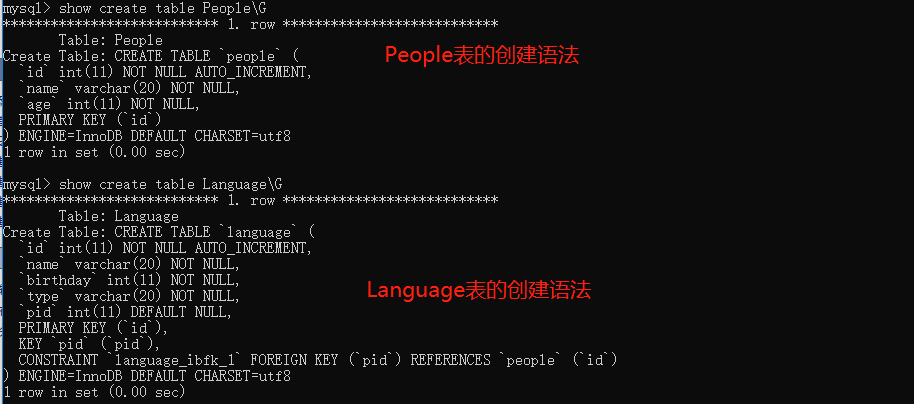
那么下面添加记录
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import sessionmaker
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
class People(Base):
__tablename__ = "People"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
class Language(Base):
__tablename__ = "Language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(String(20), nullable=False)
# 还记得约束的种类吗
# 1.RESTRICT:父表删除数据,会阻止。
'''
因为在子表中,引用了父表的数据,如果父表的数据删除了,那么字表就会懵逼,不知道该找谁了。
'''
# 2.NO ACTION
'''
和RESTRICT作用类似
'''
# 3.CASCADE
'''
级联删除:我们Language表的pid关联了People的id。如果People中id=1的记录被删除了,那么Language中关联id=1的记录也会被删除
就是我们关联了,我的pid关联了你的id,如果你删除了一条记录,那么根据你删除记录的id,我也会相应的删除一条,要死一块死。
'''
# 4.SET NULL
'''
设置为空:和CASCADE类似,就是我的pid关联你的id,如果id没了,那么pid会被设置为空,不会像CASCADE那样,把相应pid所在整条记录都给删了
'''
# 那么如何设置呢?在ForeignKey中有一个onedelete参数,可以接收上面四种中的一种
pid = Column(Integer, ForeignKey("People.id", ondelete="RESTRICT"))
# 由于我们之前已经创建了,所以再次创建已不会修改,所以只能先删除,然后再次创建
Base.metadata.drop_all()
Base.metadata.create_all()
# 然后添加几条记录吧
Session = sessionmaker(bind=engine)
session = Session()
session.add_all([People(name="Guido van Rossum", age=62),
People(name="Dennis Ritchie", age=77),
People(name="James Gosling", age=63),
Language(name="Python", birthday=1991, type="解释型", pid=1),
Language(name="C", birthday=1972, type="编译型", pid=2),
Language(name="Java", birthday=1995, type="解释型", pid=3)])
session.commit()
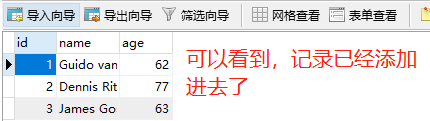
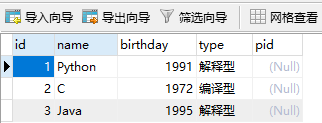
我们下面删除数据,直接在Navicat里面演示
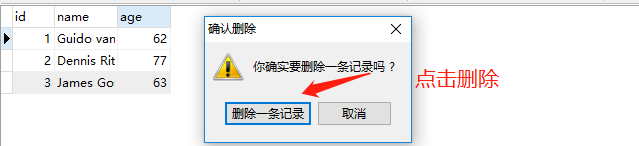
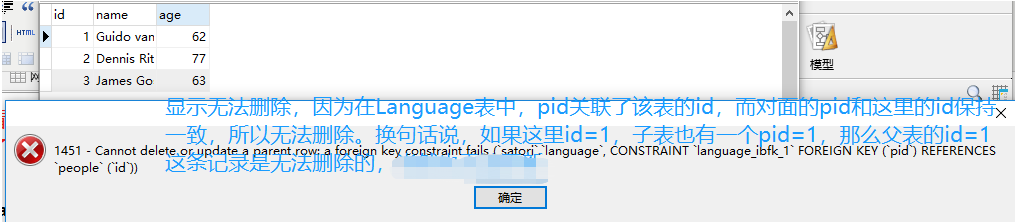
剩下的便不再演示了,都是比较类似的。另外,如果再ForeignKey中不指定onedelete,那么默认就是RESTRICT
11.ORM层外键和一对多关系
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
class People(Base):
__tablename__ = "People"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
class Language(Base):
__tablename__ = "Language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(String(20), nullable=False)
pid = Column(Integer, ForeignKey("People.id", ondelete="RESTRICT"))
# 如果我想通过Language表查询People表的数据呢?
# 可以通过relationship进行关联
people = relationship("People")
Base.metadata.drop_all()
Base.metadata.create_all()
Session = sessionmaker(bind=engine)
session = Session()
session.add_all([People(name="Guido van Rossum", age=62),
People(name="Dennis Ritchie", age=77),
People(name="James Gosling", age=63),
Language(name="Python", birthday=1991, type="解释型", pid=1),
Language(name="C", birthday=1972, type="编译型", pid=2),
Language(name="Java", birthday=1995, type="解释型", pid=3)])
session.commit()
people = session.query(Language).all()
for i in people:
# Language的people已经和People这个表关联了,我通过language依旧可以访问
print(i.people.name, i.people.age)
'''
Guido van Rossum 62
Dennis Ritchie 77
James Gosling 63
'''
一般情况下,一们语言对应一个作者,但是一个作者可以有多个语言。

from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
class People(Base):
__tablename__ = "People"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
language = relationship("Language")
def __repr__(self):
return f"{self.name}--{self.age}--{self.languages}"
class Language(Base):
__tablename__ = "Language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(String(20), nullable=False)
pid = Column(Integer, ForeignKey("People.id", ondelete="RESTRICT"))
people = relationship("People")
def __repr__(self):
return f"{self.name}--{self.birthday}--{self.type}"
Session = sessionmaker(bind=engine)
session = Session()
# 通过People里的language,查找Language表的记录
# 实际上这里的language还是所有People对象的集合
language = session.query(People).all()
# 遍历People对象
for i in language:
# People的language已经和Language这个表关联了,我通过language依旧可以访问
# 由于People和Language是一对多的关系,所以一个People记录可能对应多个Language记录,所以得到的都是一个列表
# 通过i.language,直接会去查找Language表,从而打印出结果
print(i.language)
'''
[Python--1991--解释型]
[C--1972--编译型, unix--1973--操作系统]
[Java--1995--解释型]
'''
# 这里得到是每一个People对象
for i in language:
# 这里遍历每一个People对象下的language,通过这里的language查找Language表的记录。
# 而这里的两个language是不一样的,所以我这里起名字失误了,不应该都叫language的,容易引起歧义,まぁいいや
for j in i.language:
print(i.name, j.name, j.birthday, j.type)
'''
Guido van Rossum Python 1991 解释型
Dennis Ritchie C 1972 编译型
Dennis Ritchie unix 1973 操作系统
James Gosling Java 1995 解释型
'''
在relationship中还有一个反向引用
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
class People(Base):
__tablename__ = "People"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
# 我们把这一行注释掉
# language = relationship("Language")
def __repr__(self):
return f"{self.name}--{self.age}--{self.languages}"
class Language(Base):
__tablename__ = "Language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(String(20), nullable=False)
pid = Column(Integer, ForeignKey("People.id", ondelete="RESTRICT"))
# 我们在People表中把relationship给注释掉了,但是在Language表的relationship中添加了一个backref="language",反向引用
# 意思是说,我们即便在People中不指定,也依旧可以通过People对象.language的方式来访问到Language表中的所有属性
# 因为前面指定了People表示已经和People表关联了
# 当然这里也可以不叫language,比方说我改成中文试试
'''
people = relationship("People", backref="language")
'''
people = relationship("People", backref="古明地盆")
def __repr__(self):
return f"{self.name}--{self.birthday}--{self.type}"
Session = sessionmaker(bind=engine)
session = Session()
language = session.query(People).all()
# 遍历People对象
for i in language:
print(i.古明地盆)
'''
[Python--1991--解释型]
[C--1972--编译型, unix--1973--操作系统]
[Java--1995--解释型]
'''
# 可以看到即便用中文依旧可以访问,但是工作中千万别这么干,否则被技术leader看到了,要么把你骂一顿,要么把你给开除了
12.一对一关系实现
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
class People(Base):
__tablename__ = "People"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
# 我们把这一行注释掉
# language = relationship("Language")
def __repr__(self):
return f"{self.name}--{self.age}--{self.languages}"
class Language(Base):
__tablename__ = "Language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(String(20), nullable=False)
pid = Column(Integer, ForeignKey("People.id", ondelete="RESTRICT"))
people = relationship("People", backref="language")
def __repr__(self):
return f"{self.name}--{self.birthday}--{self.type}"
Session = sessionmaker(bind=engine)
session = Session()
people = People(id=6, name="KenThompson", age=75)
language1 = Language(name="B", birthday=1968, type="编译型", pid=6)
language2 = Language(name="Go", birthday=2009, type="编译型", pid=6)
# 由于People和Language是关联的,并且通过language可以访问到Language表的属性
# 那么可以通过people.language.append将Language对象添加进去
people.language.append(language1)
people.language.append(language2)
# 然后只需要提交People对象people,就会自动将Language对象language1、language2也提交了
session.add(people)
session.commit()
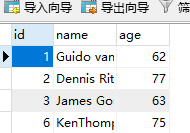
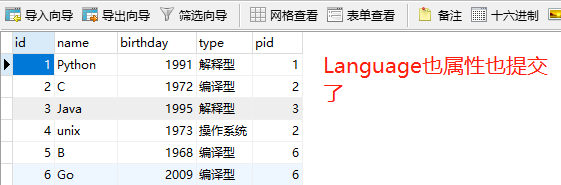
但是如果我想反向添加怎么办呢?
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
class People(Base):
__tablename__ = "People"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
# 我们把这一行注释掉
# language = relationship("Language")
def __repr__(self):
return f"{self.name}--{self.age}--{self.languages}"
class Language(Base):
__tablename__ = "Language"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False)
birthday = Column(Integer, nullable=False)
type = Column(String(20), nullable=False)
pid = Column(Integer, ForeignKey("People.id", ondelete="RESTRICT"))
people = relationship("People", backref="language")
def __repr__(self):
return f"{self.name}--{self.birthday}--{self.type}"
Session = sessionmaker(bind=engine)
session = Session()
people = People(id=7, name="松本行弘", age=53)
language = Language(name="ruby", birthday=1995, type="解释型", pid=7)
# 反向添加,刚才的是正向添加的。
# 正向:people.language.append,反向:language.people=people
# 正向里的language是backref,反向里的people是people = relationship("People", backref="language")的左值
language.people = people
# 然后只需要提交People对象people,就会自动将Language对象language1、language2也提交了
session.add(people)
session.commit()
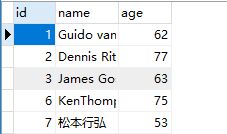
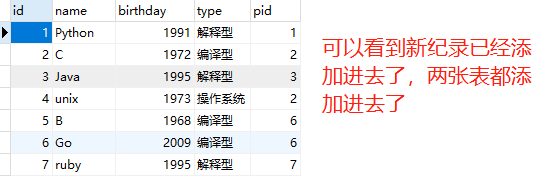
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
class People(Base):
__tablename__ = "People"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
# 表示得到的不是一个列表,因为我们是一对一,只有一个元素
extend = relationship("People_extend", uselist=False)
def __repr__(self):
return f"{self.name}--{self.age}--{self.languages}"
class People_extend(Base):
__tablename__ = "People_extend"
id = Column(Integer, primary_key=True, autoincrement=True)
country = Column(String(20))
uid = Column(Integer, ForeignKey("People.id"))
# 并且这里不需要backref了,加了会报错
people = relationship("People")
'''
people = People()
extend = People_extend()
然后通过people.extend = extend实现即可
'''
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship, backref
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
class People(Base):
__tablename__ = "People"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
# 表示得到的不是一个列表,因为我们是一对一,只有一个元素
# extend = relationship("People_extend", uselist=False)
def __repr__(self):
return f"{self.name}--{self.age}--{self.languages}"
class People_extend(Base):
__tablename__ = "People_extend"
id = Column(Integer, primary_key=True, autoincrement=True)
country = Column(String(20))
uid = Column(Integer, ForeignKey("People.id"))
# 或者把上面的注释掉,导入backref模块
people = relationship("People", backref=backref("extend", uselist=False))
'''
用法和之前的一样
people = People()
extend = People_extend()
然后通过people.extend = extend实现即可
再使用People访问的时候,直接通过people.extend.来访问即可
'''
12.多对多关系实现
比如说博客园的文章,一篇文章可能对应多个标签。同理一个标签也会有有多个文章。这就是一个多对多的关系
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
# 现在我们的两张表建好了,既然要实现多对多,需要借助第三张表。
# SQLAlchemy已经为我们提供好了一个table,让我们去使用
Article_Tag = Table("Article_Tage", Base.metadata,
Column("article_id", Integer, ForeignKey("Article.id"), primary_key=True),
Column("tag_id", Integer, ForeignKey("Tag.id"), primary_key=True)
)
class Article(Base):
__tablename__ = "Article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
tags = relationship("Tag", backref="articles", secondary=Article_Tag)
class Tag(Base):
__tablename__ = "Tag"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(50), nullable=False)
'''
总结一下:
1、先把两个需要多对多的模型建立出来
2、使用Table定义一个中间表,中间表就是包含两个模型的外键字段就可以了,并且让它们两个做一个复合主键
3、在两个需要做多对多的模型中随便选择一个模型,定义一个relationship属性,来绑定三者之间的关系,在使用relationship的时候,需要传入一个secondary="中间表"
'''
Base.metadata.create_all()
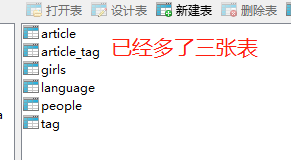
看一下表的创建过程

添加数据
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
# 现在我们的两张表建好了,既然要实现多对多,需要借助第三张表。
# SQLAlchemy已经为我们提供好了一个table,让我们去使用
Article_Tag = Table("Article_Tag", Base.metadata,
Column("article_id", Integer, ForeignKey("Article.id"), primary_key=True),
Column("tag_id", Integer, ForeignKey("Tag.id"), primary_key=True)
)
class Article(Base):
__tablename__ = "Article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
tags = relationship("Tag", backref="articles", secondary=Article_Tag)
class Tag(Base):
__tablename__ = "Tag"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(50), nullable=False)
'''
总结一下:
1、先把两个需要多对多的模型建立出来
2、使用table定义一个中间表,中间表就是包含两个模型的外键字段就可以了,并且让它们两个做一个复合主键
3、在两个需要做多对多的模型中随便选择一个模型,定义一个relationship属性,来绑定三者之间的关系,在使用relationship的时候,需要传入一个secondary="中间表"
'''
Base.metadata.create_all()
article1 = Article(title="article1")
article2 = Article(title="article2")
tag1 = Tag(name="tag1")
tag2 = Tag(name="tag2")
# 每一篇文章,添加两个标签
article1.tags.append(tag1)
article1.tags.append(tag2)
article2.tags.append(tag1)
article2.tags.append(tag2)
Session = sessionmaker(bind=engine)
session = Session()
# 只需添加article即可,tag会被自动添加进去
session.add_all([article1, article2])
session.commit()
获取数据
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
# 现在我们的两张表建好了,既然要实现多对多,需要借助第三张表。
# SQLAlchemy已经为我们提供好了一个table,让我们去使用
Article_Tag = Table("Article_Tag", Base.metadata,
Column("article_id", Integer, ForeignKey("Article.id"), primary_key=True),
Column("tag_id", Integer, ForeignKey("Tag.id"), primary_key=True)
)
class Article(Base):
__tablename__ = "Article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
'''
Article对象.tags获取Tag里面的属性
Tag对象.articles(backref)获取Article里面的属性
'''
tags = relationship("Tag", backref="articles", secondary=Article_Tag)
def __repr__(self):
return f"{self.title}"
class Tag(Base):
__tablename__ = "Tag"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(50), nullable=False)
def __repr__(self):
return f"{self.name}"
'''
总结一下:
1、先把两个需要多对多的模型建立出来
2、使用table定义一个中间表,中间表就是包含两个模型的外键字段就可以了,并且让它们两个做一个复合主键
3、在两个需要做多对多的模型中随便选择一个模型,定义一个relationship属性,来绑定三者之间的关系,在使用relationship的时候,需要传入一个secondary="中间表"
'''
Base.metadata.create_all()
# article1 = Article(title="article1")
# article2 = Article(title="article2")
#
# tag1 = Tag(name="tag1")
# tag2 = Tag(name="tag2")
#
# # 每一篇文章,添加两个标签
# article1.tags.append(tag1)
# article1.tags.append(tag2)
# article2.tags.append(tag1)
# article2.tags.append(tag2)
#
# Session = sessionmaker(bind=engine)
# session = Session()
#
# # 只需添加article即可,tag会被自动添加进去
# session.add_all([article1, article2])
# session.commit()
Session = sessionmaker(bind=engine)
session = Session()
tag = session.query(Tag).first()
print(tag.articles) # [article1, article2]
article = session.query(Article).first()
print(article.tags) # [tag1, tag2]
# 可以看到,相应的数据全部获取出来了
13.ORM层面删除数据注意事项
我们知道一旦关联,那么删除父表里面的数据是无法删除的,只能先删除字表的数据,然后才能删除关联的父表数据。如果在orm层面的话,可以直接删除父表数据,因为这里等同于两步。先将字表中关联的字段设置为NULL,然后删除父表中的数据,等同于这两步。为了方便演示,我这里将所有表全部删除
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
Session = sessionmaker(bind=engine)
session = Session()
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
# uid是为了建立外键,我们要和use表的id进行关联,所以类型也要和user表的id保持一致
uid = Column(Integer, ForeignKey("user.id"))
# 这个是为了我们能够通过一张表访问到另外一张表
# 以后User对象便可以通过articles来访问Articles表的属性了
author = relationship("User", backref="articles")
Base.metadata.create_all()
# 创建几条记录
user = User(username="guido van rossum")
article = Article(title="Python之父谈论python的未来")
article.author = user
# 然后使用session添加article即可,会自动添加user
session.add(article)
session.commit()

此时我们在数据库层面删除一下数据

我们试试在orm层面删除数据
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
Session = sessionmaker(bind=engine)
session = Session()
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
# uid是为了建立外键,我们要和use表的id进行关联,所以类型也要和user表的id保持一致
uid = Column(Integer, ForeignKey("user.id"))
# 这个是为了我们能够通过一张表访问到另外一张表
# 以后User对象便可以通过articles来访问Articles表的属性了
author = relationship("User", backref="articles")
Base.metadata.create_all()
# # 创建几条记录
# user = User(username="guido van rossum")
# article = Article(title="Python之父谈论python的未来")
#
# article.author = user
# # 然后使用session添加article即可,会自动添加user
# session.add(article)
# session.commit()
# 因为只有一条数据,所以直接first
user = session.query(User).first()
session.delete(user)
session.commit()


删除父表的数据,这个过程相当于先将article中的uid设置为NULL,然后删除父表的数据
但是这样也有危险,如果不熟悉SQLAlchemy的话,会造成不可避免的后果,怎么办呢?直接将uid设置为不可为空即可,加上nullable=False
14.relationship中的cascade属性
ORM层面的cascade:
首先我们知道如果如果数据库的外键设置为RESTRICT,那么在orm层面,如果删除了父表的数据,字表的数据将会被设置为NULL,如果想避免这一点,那么只需要将nullable设置为False即可
但是在SQLAlchemy中,我们只需要将一个数据添加到session中,提交之后,与其关联的数据也被自动地添加到数据库当中了,这是怎么办到的呢?其实是通过relationship的时候,其关键字参数cascade设置了这些属性:
1.save-update:默认选项,在添加一条数据的时候,会自动把与其相关联的数据也添加到数据库当中。这种行为就是save-update所影响的
2.delete:表示删除某一个模型的数据时,是否也删掉使用relationship与其相关联的数据。
3.delete-orphan:表示当对一个orm对象解除了父表中的关联对象的时候,自己便会被删掉。当然父表中的数据被删除了,自己也会被删除。这个选项只能用在一对多上,不能用在多对多以及多对一上。并且还需要在子模型的relationship中,添加一个single_parent=True的选项
4.merge:默认选项,当使用session.merge选项合并一个对象的时候,会将使用了relationship相关联的对象也进行merge操作
5.expunge:移除操作的时候,会将相关联的对象也进行移除。这个操作只会从session中删除,并不会从数据库当中移除
6.all:以上五种情况的总和
下面我来逐一演示
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
Session = sessionmaker(bind=engine)
session = Session()
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
uid = Column(Integer, ForeignKey("user.id"))
# 可以看到其他都是不变的,只是这里我们显式的指定了cascade
# 这里设置为"",这样就不会有save-update属性了。
author = relationship("User", backref="articles", cascade="")
Base.metadata.drop_all()
Base.metadata.create_all()
# 创建几条记录
user = User(username="guido van rossum")
article = Article(title="Python之父谈论python的未来")
article.author = user
# 然后使用session添加article即可,此时就不会添加user了
session.add(article)
session.commit()


from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
Session = sessionmaker(bind=engine)
session = Session()
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
uid = Column(Integer, ForeignKey("user.id"))
# 可以看到其他都是不变的,只是这里我们显式的指定了cascade
# 我们也可以手动指定save-update,当然这样和不指定cascade是一样,因为默认就是save-update
author = relationship("User", backref="articles", cascade="save-update")
Base.metadata.drop_all()
Base.metadata.create_all()
# 创建几条记录
user = User(username="guido van rossum")
article = Article(title="Python之父谈论python的未来")
article.author = user
# 然后使用session添加article即可,会添加user
session.add(article)
session.commit()

from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
Session = sessionmaker(bind=engine)
session = Session()
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
uid = Column(Integer, ForeignKey("user.id"))
# 可以看到其他都是不变的,只是这里我们显式的指定了cascade
# 我们试一下delete,先说一下,可以设置多个属性,属性之间使用英文的逗号分隔
# 这样指定之后,如果当我删除了Article表的数据,那么与之相关联的User表中的数据也会被删除
author = relationship("User", backref="articles", cascade="save-update,delete")
Base.metadata.drop_all()
Base.metadata.create_all()
# 创建几条记录
user = User(username="guido van rossum")
article = Article(title="Python之父谈论python的未来")
article.author = user
# 如果不加delete,那么我删除Article表的数据,User表的数据依旧会坚挺在那里
# 但是我现在加上了delete,那么当我删除Article表的数据,User表的数据也会被删除
session.add(article)
session.commit()
15.三种排序方式
1.order_by
正序:session.query(table).order_by("table.column").all() ,或者 session.query(table).order_by("column").all()
倒序:session.query(table).order_by("table.column.desc").all() 或者 session.query(table).order_by("-column").all()
2.在模型中定义
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
age = Column(Integer)
# 就以User为例,在SQLAlchemy中有一个属性叫做__mapper_args__
# 是一个字典,我们可以指定一个叫做order_by的key,value则为一个字段
__mapper_args__ = {"order_by": age}
# 倒序的话,__mapper_args__ = {"order_by": age.desc()}
# 以后再查找的时候直接session.query(table).all()即可,自动按照我们指定的排序
3.使用backref
16.limit、offset以及切片操作
limit:session.query(table).limit(10).all(),从开头开始取十条数据
offset:session.query(table).offset(10).limit(10).all(),从第十条开始取10条数据
slice:session.query(table).slice(1, 8).all(),从第一条数据开始取到第八条数据。或者session.query(table)[1:8]这样更简单,连all()都不用了
17.数据查询懒加载技术
在一对多或者多对多的时候,如果想要获取多的这一部分数据的时候,往往通过一个属性就可以全部获取了。比如有一个作者,如果想要获取这个作者的所有文章,那么通过user.articles就可以全部获取了。但有时候我们不想获取所有的数据,比如只获取这个作者今天发表的文章,那么这个时候就可以给relationship传递一个lazy=“dynamic”,以后通过user.articles获取到的就不是一个列表,而是一个AppendQuery对象了。以后就可以对这个对象再进行过滤和排序工作。
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
from pprint import pprint
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
Session = sessionmaker(bind=engine)
session = Session()
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
age = Column(Integer)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
uid = Column(Integer, ForeignKey("user.id"))
author = relationship("User", backref=backref("articles"))
Base.metadata.drop_all()
Base.metadata.create_all()
user = User(username="guido", age=63)
for i in range(10):
article = Article(title=f"title{i}")
article.author = user
session.add(article)
session.commit()
user = session.query(User).first()
pprint(user.articles)
'''
[<__main__.Article object at 0x000001B73F8A5208>,
<__main__.Article object at 0x000001B73F8A5278>,
<__main__.Article object at 0x000001B73F8A52E8>,
<__main__.Article object at 0x000001B73F8A5358>,
<__main__.Article object at 0x000001B73F8A53C8>,
<__main__.Article object at 0x000001B73F8A5438>,
<__main__.Article object at 0x000001B73F8A54A8>,
<__main__.Article object at 0x000001B73F8A5550>,
<__main__.Article object at 0x000001B73F8A55F8>,
<__main__.Article object at 0x000001B73F804400>]
'''
以上获取了全部数据,如果只获取一部分呢?
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_
from sqlalchemy import Column, Integer, String, ForeignKey, Table
from sqlalchemy.orm import sessionmaker, relationship, backref
from pprint import pprint
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
Session = sessionmaker(bind=engine)
session = Session()
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
age = Column(Integer)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
uid = Column(Integer, ForeignKey("user.id"))
# 如果转化成一个AppendQuery对象,获取部分数据呢?只需要加上一个lazy="dynamic"即可
# 注意这里一定要写在backref里面,我们的目的是为了通过user取article,把article转成一个AppendQuery对象,所以要写在backref里面
# 如果写在了外面,那么就相当于通过article去找user,把user变成一个AppendQuery对象了
# 所以我们要导入backref,表示反向引用。backref="articles",是为了通过user取得article,所以明明定义在article里面,却反过来被user使用
# 同理backref=backref("articles")和backref="articles"是一样的,但是之所以要加上里面的这个backref,是为了给user提供更好的属性,比如这里的懒加载
# 是为了让user找article的时候进行懒加载,如果没有这个backref,那么这个lazy属性我们可能要定义在user里面了,这样很麻烦
# 但是通过导入backref,我们可以直接在article里面定义,反过来让user去使用,一旦定义在了外面,不反向了就变成article的了
# 等于通过article找user进行懒加载
author = relationship("User", backref=backref("articles", lazy="dynamic"))
def __repr__(self):
return f"{self.title}"
Base.metadata.drop_all()
Base.metadata.create_all()
user = User(username="guido", age=63)
for i in range(10):
article = Article(title=f"title{i}")
article.author = user
session.add(article)
session.commit()
user = session.query(User).first()
# 此时不再是InstrumentList,而是一个AppendQuery对象
print(type(user.articles)) # <class 'sqlalchemy.orm.dynamic.AppenderQuery'>
# 查看一下源码发现,AppenderQuery这个类继承在Query这个类,也就是说Query可使用的,它都能使用
print(user.articles.filter(Article.id > 5).all()) # [title5, title6, title7, title8, title9]
# 也可以动态添加数据
article = Article(title="100")
user.articles.append(article)
session.commit() # 不用add,直接commit
print(user.articles.filter(Article.id > 5).all()) # [title5, title6, title7, title8, title9, 100]
'''
lazy有以下参数:
1.select:默认选项,以user.articles为例,如果没有访问user.articles属性,那么SQLAlchemy就不会从数据库中查找文章。一旦访问,就会查找所有文章,最为InstrumentList返回
2.dynamic:返回的不是一个InstrumentList,而是一个AppendQuery对象。
主要使用这两种情况
'''
18.group_by和having字句
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_, func
from sqlalchemy import Column, Integer, String, ForeignKey, Table, Enum
from sqlalchemy.orm import sessionmaker, relationship, backref
from pprint import pprint
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
Session = sessionmaker(bind=engine)
session = Session()
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
age = Column(Integer)
gender = Column(Enum("male", "female","secret"), default="male")
Base.metadata.drop_all()
Base.metadata.create_all()
user1 = User(username="神田空太", age=16, gender="male")
user2 = User(username="椎名真白", age=16, gender="female")
user3 = User(username="四方茉莉", age=400, gender="female")
user4 = User(username="木下秀吉", age=15, gender="secret")
user5 = User(username="牧濑红莉栖", age=18, gender="female")
session.add_all([user1, user2, user3, user4, user5])
session.commit()
# group_by:分组,比方说我想查看每个年龄对应的人数
print(session.query(User.age, func.count(User.id)).group_by(User.age).all())
'''
输出结果:
[(15, 1), (16, 2), (18, 1), (400, 1)]
'''
# having:在group_by分组的基础上进行进一步查询,比方说我想查看年龄大于16的每一个年龄段对应的人数
print(session.query(User.age, func.count(User.id)).group_by(User.age).having(User.age > 16).all())
'''
输出结果:
[(18, 1), (400, 1)]
'''
# 如果想看看底层的语句是什么写的,可以不加上all()进行查看
print(session.query(User.age, func.count(User.id)).group_by(User.age).having(User.age > 16))
'''
SELECT user.age AS user_age, count(user.id) AS count_1
FROM user GROUP BY user.age
HAVING user.age > %(age_1)s
从user表中选出age,计算count(user.id)作为count_1,按照user.age分组,并且user.age要大于我们指定的值
'''
19.join实现复杂查询
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_, func
from sqlalchemy import Column, Integer, String, ForeignKey, Table, Enum
from sqlalchemy.orm import sessionmaker, relationship, backref
from pprint import pprint
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
Session = sessionmaker(bind=engine)
session = Session()
class User(Base):
__tablename__ = "user"
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
class Article(Base):
__tablename__ = "article"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
uid = Column(Integer, ForeignKey("user.id"))
author = relationship("User", backref=backref("articles", lazy="dynamic"))
def __repr__(self):
return f"{self.title}"
Base.metadata.drop_all()
Base.metadata.create_all()
user1 = User(username="guido")
user2 = User(username="ken")
article1 = Article(title="python")
article1.author = user1
article2 = Article(title="B")
article2.author = user2
article3 = Article(title="go")
article3.author = user2
session.add_all([article1, article2, article3])
session.commit()

在数据库层面上进行查询,查询每个作者发表了多少文章,因为id是不重复的,所以对id进行count即可

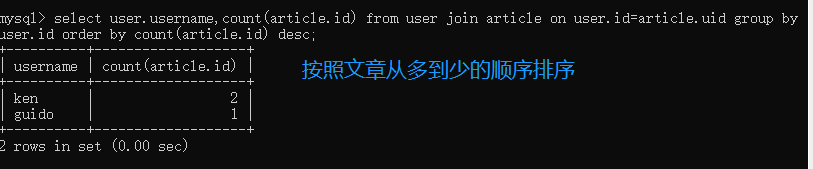
# 找到所有用户,按照发表文章的数量进行排序
res = session.query(User.username, func.count(Article.id)).join(Article, User.id == Article.uid).\
group_by(User.id).order_by(func.count(Article.id))
print(res)
'''
SELECT user.username AS user_username, count(article.id) AS count_1
FROM user INNER JOIN article ON user.id = article.uid GROUP BY user.id ORDER BY count(article.id)
'''
print(res.all())
'''
[('guido', 1), ('ken', 2)]
'''
20.subquery实现复杂查询
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, and_, or_, func
from sqlalchemy import Column, Integer, String, ForeignKey, Table, Enum
from sqlalchemy.orm import sessionmaker, relationship, backref
from pprint import pprint
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
Session = sessionmaker(bind=engine)
session = Session()
class Girl(Base):
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(50), nullable=False)
anime = Column(String(50), nullable=False)
age = Column(Integer, nullable=False)
def __repr__(self):
return f"{self.name}--{self.anime}--{self.age}"
Base.metadata.create_all()
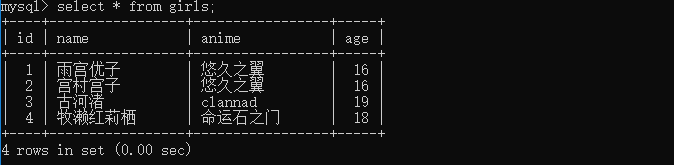
girl1 = Girl(name="雨宫优子", anime="悠久之翼", age=16)
girl2 = Girl(name="宫村宫子", anime="悠久之翼", age=16)
girl3 = Girl(name="古河渚", anime="clannad", age=19)
girl4 = Girl(name="牧濑红莉栖", anime="命运石之门", age=18)
session.add_all([girl1, girl2, girl3, girl4])
session.commit()
# 下面要寻找和雨宫优子在同一anime,并且age相同的记录 girl = session.query(Girl).filter(Girl.name == "雨宫优子").first() # Girl.anime == girl.anime, Girl.age == girl.age,girl是我们查找的name="雨宫优子"的记录,Girl则是整个表 # 查找整个表中的anime等于girl.anime 并且 age等于girl.age的记录 expect_girls = session.query(Girl).filter(Girl.anime == girl.anime, Girl.age == girl.age, Girl.name != "雨宫优子").all() print(expect_girls) # [宫村宫子--悠久之翼--16]

# 使用subquery
# 这里也可以使用label取个别名,当然我这里取得还是anime
ygyz = session.query(Girl.anime.label("anime"), Girl.age).filter(Girl.name == "雨宫优子").subquery()
# 这里的ygyz.c的c代指的是column,是一个简写
res = session.query(Girl).filter(Girl.anime == ygyz.c.anime, Girl.age == ygyz.c.age)
print(res)
'''
SELECT girls.id AS girls_id, girls.name AS girls_name, girls.anime AS girls_anime, girls.age AS girls_age
FROM girls, (SELECT girls.anime AS anime, girls.age AS age
FROM girls
WHERE girls.name = %(name_1)s) AS anon_1
WHERE girls.anime = anon_1.anime AND girls.age = anon_1.age
可以看到除了起了一些名字之外,SQLAlchemy生成的sql语句与我们之前写的几乎类似
'''
print(res.all())
'''
[雨宫优子--悠久之翼--16, 宫村宫子--悠久之翼--16]
'''
和我们之前写的代码貌似没啥区别,也要两步,而且这个貌似代码量还多一些。但是倒数据库里面,我们现在写的只需要进行一次查询,效率更高一些。
21.Flask-SQLAlchemy的使用
Flask-SQLAlchemy的一个插件,可以更加方便我们去使用,SQLAlchemy是可以独立于flask而存在的,这个插件是将SQLAlchemy集成到flask里面来。我们之前使用SQLAlchemy的时候,要定义Base,session,各个模型之类,使用这个插件可以简化我们的工作
这个插件首先要安装,直接pip install flask-sqlalchemy即可
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
db_url = f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}"
# 这个配置不直接与我们的SQLAlchemy这个类发生关系,而是要添加到app.config里面,这一步是少不了的
# 至于这里的key,作者规定就是这么写的
app.config["SQLALCHEMY_DATABASE_URI"] = db_url
# 并且还要加上这一段,不然会弹出警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
# 接收一个app,从此db便具有了app的功能
db = SQLAlchemy(app)
# 建立模型,肯定要继承,那么继承谁的,继承自db.Module,相当于之前的Base。这里操作简化了,不需要我们去创建了
class User(db.Model):
__tablename__ = "user"
# 可以看到,之前需要导入的通通不需要导入了,都在db下面。不过本质上调用的还是sqlalchemy模块里的类。
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(50), nullable=False)
class Article(db.Model):
__tablename__ = "article"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
title = db.Column(db.String(50), nullable=False)
uid = db.Column(db.Integer, db.ForeignKey("user.id"))
authror = db.relationship("User", backref="articles")
# 所以我们发现这和SQLAlchemy框架中的使用方法基本上是一致的,只不过我们在SQLAlchemy中需要导入的,现在全部可以通过db来访问
# 那么如何映射到数据库里面呢?这里也不需要Base.metadata了,直接使用db即可。
db.drop_all()
db.create_all()
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
db_url = f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}"
# 这个配置不直接与我们的SQLAlchemy这个类发生关系,而是要添加到app.config里面,这一步是少不了的
# 至于这里的key,作者规定就是这么写的
app.config["SQLALCHEMY_DATABASE_URI"] = db_url
# 并且还要加上这一段,不然会弹出警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
# 接收一个app,从此db便具有了app的功能
db = SQLAlchemy(app)
# 建立模型,肯定要继承,那么继承谁的,继承自db.Module,相当于之前的Base。这里操作简化了,不需要我们去创建了
class User(db.Model):
__tablename__ = "user"
# 可以看到,之前需要导入的通通不需要导入了,都在db下面。不过本质上调用的还是sqlalchemy模块里的类。
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(50), nullable=False)
class Article(db.Model):
__tablename__ = "article"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
title = db.Column(db.String(50), nullable=False)
uid = db.Column(db.Integer, db.ForeignKey("user.id"))
author = db.relationship("User", backref="articles")
# 所以我们发现这和SQLAlchemy框架中的使用方法基本上是一致的,只不过我们在SQLAlchemy中需要导入的,现在全部可以通过db来访问
# # 那么如何映射到数据库里面呢?这里也不需要Base.metadata了,直接使用db即可。
# db.drop_all()
# db.create_all()
# 下面添加数据
user = User(name="guido")
article = Article(title="python之父谈python的未来")
user.articles.append(article)
db.session.add(user)
'''
或者
article.author = user
db.session.add(article)
'''
db.session.commit()
# 跟我们之前使用SQLAlchemy的流程基本一致

from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
db_url = f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}"
# 这个配置不直接与我们的SQLAlchemy这个类发生关系,而是要添加到app.config里面,这一步是少不了的
# 至于这里的key,作者规定就是这么写的
app.config["SQLALCHEMY_DATABASE_URI"] = db_url
# 并且还要加上这一段,不然会弹出警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
# 接收一个app,从此db便具有了app的功能
db = SQLAlchemy(app)
# 建立模型,肯定要继承,那么继承谁的,继承自db.Module,相当于之前的Base。这里操作简化了,不需要我们去创建了
class User(db.Model):
__tablename__ = "user"
# 可以看到,之前需要导入的通通不需要导入了,都在db下面。不过本质上调用的还是sqlalchemy模块里的类。
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(50), nullable=False)
def __repr__(self):
return f"{self.name}"
class Article(db.Model):
__tablename__ = "article"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
title = db.Column(db.String(50), nullable=False)
uid = db.Column(db.Integer, db.ForeignKey("user.id"))
author = db.relationship("User", backref="articles")
def __repr__(self):
return f"{self.tit }"
# 如何查找数据呢?
# 首先我们可以想到db.session.query(User),这毫无疑问是可以的,但是我们的模型继承了db.Model,那么我们有更简单的方法
# 直接使用User.query即可,就等价于db.session.query(User)
users = User.query.all()
print(users) # [guido]
'''
排序:User.query.order_by(User.id.desc()).all()
过滤:User.query.filter(User.id == 1).all()
修改:User.query.filter(User.id == 1).first().name == "guido van rossum"
删除:删除的话还是要依赖db.session()的,找到user,db.session.delete(user)
'''
# 另外忘记提了,如果没有指定表名,也就是__tablename__,那么默认会将模型的名字转成小写当成表名。
'''
User-->user
但如果是驼峰命名法,UserModel-->user_model
但是不推荐这样使用,还是显示的指定比较好,也符合python之禅,明言胜于暗喻。
'''
22.alembic数据库迁移工具的使用
alembic是SQLAlchemy作者所写的一款用于做ORM与数据库的迁移和映射的一个框架,类似于git。
首先肯定要安装,pip install alembic
这是我的项目结构,一个文件夹,里面一个py文件

进入文件夹里面,输入alembic init xxxx
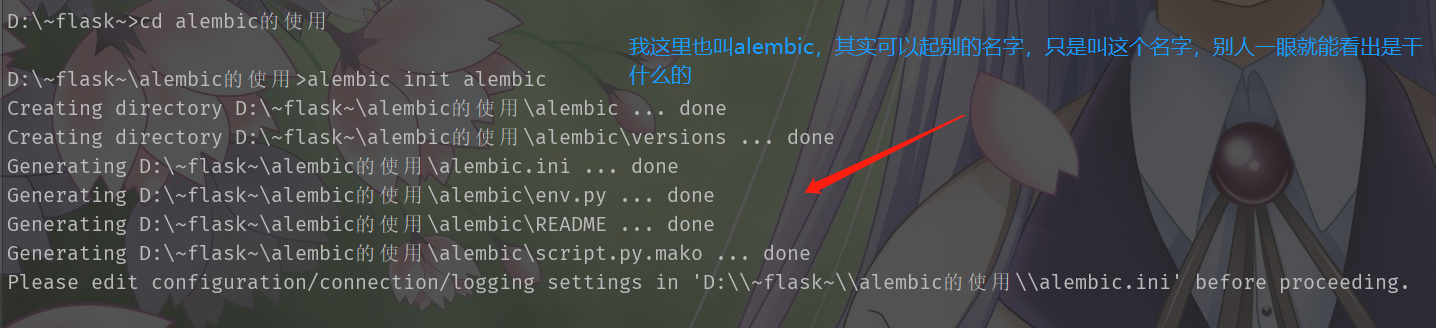

接下来建立模型,这个是独立于flask的,所以我们这次还是使用SQLAlchemy做演示
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine, func
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
engine = create_engine(f"{dialect}+{driver}://{username}:{password}@{hostname}:{port}/{database}")
Base = declarative_base(engine)
class People(Base):
__tablename__ = "People"
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(20), nullable=False) # 不可为空
age = Column(Integer, nullable=False)
def __repr__(self):
return f"{self.name}--{self.age}"
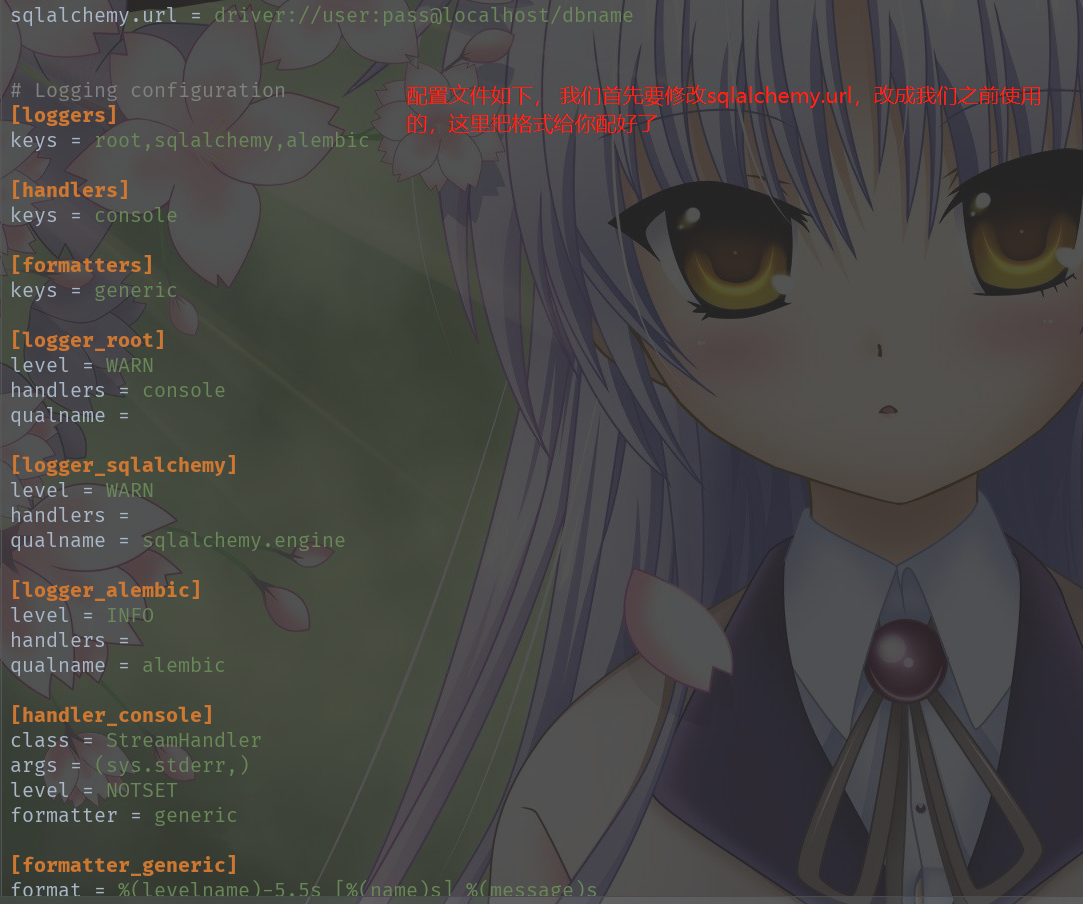
下面修改配置文件,alembic.ini


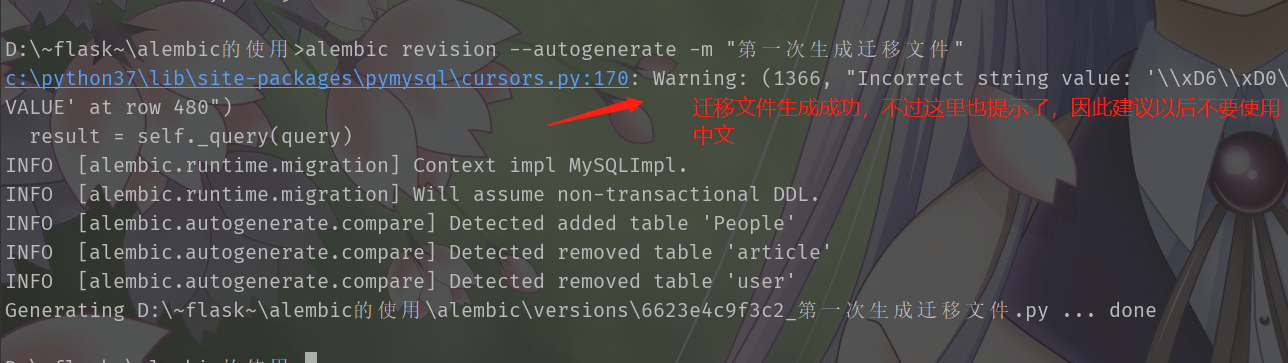
接下来生成迁移文件,alembic revision --autogenerate -m "message",这里的message是我们注释信息
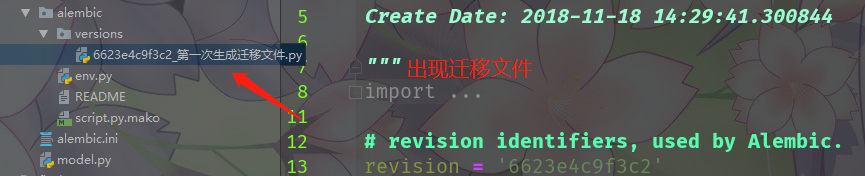
下面就要更新数据库了,将刚才生成的迁移文件映射到数据库。至于为什么需要迁移文件,那是因为无法直接映射orm模型,需要先转化为迁移文件,然后才能映射到数据库当中。
alembic upgrade head,将刚刚生成的迁移文件映射到数据库当中
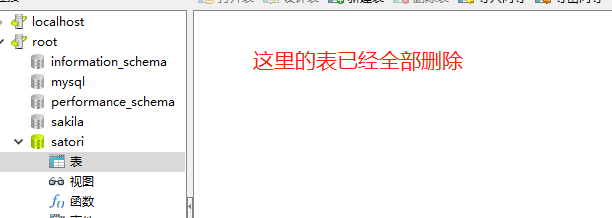
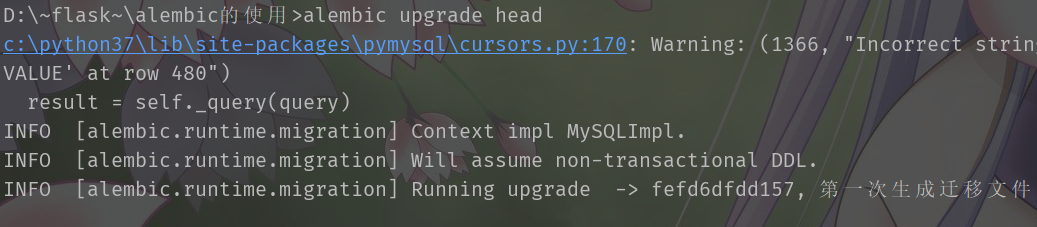

如果需要修改表的结构,不需要再drop_all,create_all了,如果里面有大量数据,不可能清空之后重新创建。那么在修改之后,直接再次生成迁移文件然后映射到数据库就可以了
总结一下,就是五个步骤:
1.定义好自己的模型
2.使用alembic init 仓库名,创建一个仓库
3.修改两个配置文件,在alembic.ini中配置数据库的连接方式,在env中修改target_metada=Base.metadata
4.生成迁移文件
5.将迁移文件映射到数据库
可以看出,这和Django非常类似。如果以后修改模型,那么重复4和5
23.alembic常用命令和经典错误解决办法
常用命令:
init:创建一个alembic仓库
revision:创建一个新的版本文件
--autogenerate:自动将当前模型的修改,生成迁移脚本
-m:本次迁移做了哪些修改,用户可以指定这个参数,方便回顾
upgrade:将指定版本的迁移文件映射到数据库中,会执行版本文件中的upgrade函数。如果有多个迁移脚本没有被映射到数据库中,那么会执行多个迁移脚本
[head]:代表最新的迁移脚本的版本号
downgrade:降级,我们每一个迁移文件都有一个版本号,如果想退回以前的版本,直接使用alembic downgrade version_id
heads:展示head指向的脚本文件
history:列出所有的迁移版本及其信息
current:展示当前数据库的版本号
经典错误:
FAILED:Target database is not up to date。原因:主要是heads和current不相同。current落后于heads的版本。解决办法:将current移动到head上,alembic upgrade head
FAILED:can’t locate revision identified by “78ds75ds7s”。原因:数据库中村的版本号不在迁移脚本文件中。解决办法:删除数据库中alembic_version表的数据,然后重新执行alembic upgrade head
执行upgrade head 时报某个表已经存在的错误。解决办法:1.删除version中所有的迁移文件的代码,修改迁移脚本中创建表的代码
24.Flask-SQLAlchemy下alembic的配置
重新建一个项目
config.py,用于存放配置文件
hostname = "localhost"
port = 3306
database = "satori"
username = "root"
password = "zgghyys123"
dialect = "mysql"
driver = "pymysql"
SQLALCHEMY_DATABASE_URI = f"mysql+pymysql://{username}:{password}@{hostname}:{port}/{database}"
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
import config
app = Flask(__name__)
app.config.from_object(config)
db = SQLAlchemy(app)
@app.route("/index")
def hello():
return "hello world"
class User(db.Model):
__tablename__ = "user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
username = db.Column(db.String(50), nullable=False)
if __name__ == '__main__':
app.run()
alembic.ini
# A generic, single database configuration. [alembic] # path to migration scripts script_location = alembic # template used to generate migration files # file_template = %%(rev)s_%%(slug)s # timezone to use when rendering the date # within the migration file as well as the filename. # string value is passed to dateutil.tz.gettz() # leave blank for localtime # timezone = # max length of characters to apply to the # "slug" field #truncate_slug_length = 40 # set to 'true' to run the environment during # the 'revision' command, regardless of autogenerate # revision_environment = false # set to 'true' to allow .pyc and .pyo files without # a source .py file to be detected as revisions in the # versions/ directory # sourceless = false # version location specification; this defaults # to alembic/versions. When using multiple version # directories, initial revisions must be specified with --version-path # version_locations = %(here)s/bar %(here)s/bat alembic/versions # the output encoding used when revision files # are written from script.py.mako # output_encoding = utf-8 sqlalchemy.url = mysql+pymysql://root:zgghyys123@localhost:3306/satori # Logging configuration [loggers] keys = root,sqlalchemy,alembic [handlers] keys = console [formatters] keys = generic [logger_root] level = WARN handlers = console qualname = [logger_sqlalchemy] level = WARN handlers = qualname = sqlalchemy.engine [logger_alembic] level = INFO handlers = qualname = alembic [handler_console] class = StreamHandler args = (sys.stderr,) level = NOTSET formatter = generic [formatter_generic] format = %(levelname)-5.5s [%(name)s] %(message)s datefmt = %H:%M:%S
from __future__ import with_statement
from alembic import context
from sqlalchemy import engine_from_config, pool
from logging.config import fileConfig
import sys, os
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
import start
# this is the Alembic Config object, which provides
# access to the values within the .ini file in use.
config = context.config
# Interpret the config file for Python logging.
# This line sets up loggers basically.
fileConfig(config.config_file_name)
# add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
target_metadata = start.db.metadata
# other values from the config, defined by the needs of env.py,
# can be acquired:
# my_important_option = config.get_main_option("my_important_option")
# ... etc.
def run_migrations_offline():
"""Run migrations in 'offline' mode.
This configures the context with just a URL
and not an Engine, though an Engine is acceptable
here as well. By skipping the Engine creation
we don't even need a DBAPI to be available.
Calls to context.execute() here emit the given string to the
script output.
"""
url = config.get_main_option("sqlalchemy.url")
context.configure(
url=url, target_metadata=target_metadata, literal_binds=True)
with context.begin_transaction():
context.run_migrations()
def run_migrations_online():
"""Run migrations in 'online' mode.
In this scenario we need to create an Engine
and associate a connection with the context.
"""
connectable = engine_from_config(
config.get_section(config.config_ini_section),
prefix='sqlalchemy.',
poolclass=pool.NullPool)
with connectable.connect() as connection:
context.configure(
connection=connection,
target_metadata=target_metadata
)
with context.begin_transaction():
context.run_migrations()
if context.is_offline_mode():
run_migrations_offline()
else:
run_migrations_online()
生成迁移文件

映射到数据库


25.flask-script讲解
flask-script的作用是可以通过命令行的方式来操作flask。例如通过命令来跑一个开发版本的服务器,设置数据库,定时任务等等。要使用的话,首先要安装,pip install flask-script

这个多了一个manage.py,可以类比Django,如果我们把所有东西都写在一个py文件里面,会非常的凌乱。那这个manage.py是干什么的呢?可以让我们通过命令行来工作
start.py
from flask import Flask
app = Flask(__name__)
@app.route("/index")
def index():
return "hello satori"
if __name__ == '__main__':
manager.run() # 注意这里是manager.run(),不是app.run()
manage.py
from flask_script import Manager
from start import app
manager = Manager(app)
@manager.command
def hello():
print("你好啊")
if __name__ == '__main__':
app.run()

from flask_script import Manager
from start import app
manager = Manager(app)
@manager.command
def hello():
return "你好啊"
@manager.option("--name", dest="username")
@manager.option("--age", dest="age")
def foo(username, age):
# 类似于python里的optparse,可以见我的python常用模块,里面有介绍
print(f"name={username}, age={age}")
if __name__ == '__main__':
manager.run()

不传参,使用command,传参使用option
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
import config
app = Flask(__name__)
app.config.from_object(config)
db = SQLAlchemy(app)
class BackendUser(db.Model):
__tablename__ = "backend_user"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
username = db.Column(db.String(50), nullable=False)
email = db.Column(db.String(50), nullable=False)
# alembic很强大,但这里就不用了,直接使用create_all
db.create_all()
@app.route("/index")
def index():
return "hello satori"
if __name__ == '__main__':
app.run()
from flask_script import Manager
from start import app, BackendUser, db
manager = Manager(app)
@manager.command
def hello():
return "你好啊"
@manager.option("--name", dest="username")
@manager.option("--email", dest="email")
def add_user(username, email):
user = BackendUser(username=username, email=email)
db.session.add(user)
db.session.commit()
if __name__ == '__main__':
manager.run()
以后就可以通过终端来添加了
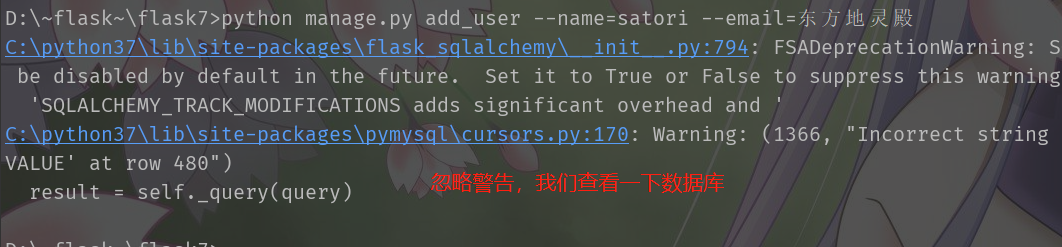
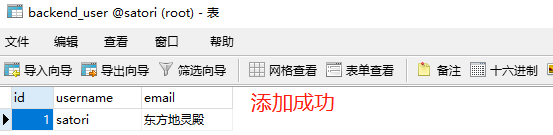
而且我们还可以模拟数据库迁移,映射等等。Django的manage.py不就是这么做的吗?python manage.py makemigrations迁移,然后再python manage.py migrate映射。
26.flask-migrate
在实际的数据库开发中,经常会出现数据表修改的行为。一般我们不会手动修改数据库,而是去修改orm模型,然后再把模型映射到数据库中。这个时候如果能有一个工具专门做这件事情就非常好了,而flask-migrate就是用来干这个的。flask-migrate是基于alembic的一个封装,并集成到flask当中,而所有的操作都是alembic做的,它能跟踪模型的变化,并将模型映射到数据库中。
from flask_migrate import Migrate, MigrateCommand
manager = Manager(app, db) # 绑定app和db到flask_migrate
manager.add_command("db", MigrateCommand) # 添加Migrate的所有子命令到db下
1.初始化一个环境:python manage.py db init
2.自动检测模型,生成迁移脚本,python manage.py db migrate
3.将迁移脚本映射到数据库中,python manage.py db upgrade
4.flask数据库的更多相关文章
- 实验3、Flask数据库操作-如何使用Flask与数据库
1. 实验内容 数据库的使用对于可交互的Web应用程序是极其重要的,本节我们主要学习如何与各种主要数据库进行连接和使用,以及ORM的使用 2. 实验要点 掌握Flask对于各种主要数据库的连接方法 掌 ...
- 细说flask数据库迁移
什么情况下要用数据库迁移? 在开发过程中,需要修改数据库模型,而且还要在修改之后更新数据库.最直接的方式就是删除旧表,但这样会丢失数据. 更好的解决办法是使用数据库迁移框架,它可以追踪数据库模式的变化 ...
- flask数据库迁移理解及命令
前言: 使用数据库迁移,可以直接建表,而不用我们自己写sql语句用来建表.就是将关系型数据库的一张张表转化成了Python的一个个类. 在开发中经常会遇到需要修改原来的数据库模型,修改之后更新数据库, ...
- 03 flask数据库操作、flask-session、蓝图
ORM ORM 全拼Object-Relation Mapping,中文意为 对象-关系映射.主要实现模型对象到关系数据库数据的映射. 1.优点 : 只需要面向对象编程, 不需要面向数据库编写代码. ...
- flask~数据库
flask与数据库的连接基于flaks_sqlaichemy 扩展 首先要连接数据库的时候必须得先下载 pip install flask-sqlalchemy 这个扩展 flask框架与数据库的连接 ...
- flask数据库操作
Python 数据库框架 大多数的数据库引擎都有对应的 Python 包,包括开源包和商业包.Flask 并不限制你使用何种类型的数据库包,因此可以根据自己的喜好选择使用 MySQL.Postgres ...
- Flask数据库
一 数据库的设置 Web应用中普遍使用的是关系模型的数据库,关系型数据库把所有的数据都存储在表中,表用来给应用的实体建模,表的列数是固定的,行数是可变的.它使用结构化的查询语言.关系型数据库的列定义了 ...
- Flask 数据库迁移
在开发过程中,需要修改数据库模型,而且还要在修改之后更新数据库.最直接的方式就是删除旧表,但这样会丢失数据. 更好的解决办法是使用数据库迁移框架,它可以追踪数据库模式的变化,然后把变动应用到数据库中. ...
- Flask数据库基本操作
数据库基本操作 在Flak-SQLAlchemy中,插入.修改.删除操作,均由数据库会话管理. 会话用db.session表示.在准备把数据写入数据库前,需要先将数据添加到会话中然后调用commit( ...
随机推荐
- Leetcode 54. Spiral Matrix & 59. Spiral Matrix II
54. Spiral Matrix [Medium] Description Given a matrix of m x n elements (m rows, n columns), return ...
- LINUX系统下Java和Scala的环境配置
最近,笔者在研究一个有关“自然语言处理”的项目,在这个项目中,需要我们用Spark进行编程.而Spark内核是由Scala语言开发的,所以在使用Spark之前,我们必须配置好Scala,而Scala又 ...
- 基于twemproxy和vip实现redis集群的无感知弹性扩容
目标是实现redis集群的无感知弹性扩容 关键点 1.是无感知,即对redis集群的用户来说服务ip和port保持不变 2.弹性扩容,指的是在需要时刻可以按照业务扩大redis存储容量. 1.业务场景 ...
- LTE/EPC中,MME怎么找到UE的HSS的?
http://bbs.c114.net/forum.php?mod=viewthread&tid=486247 HSS---归属用户服务器,我的理解:一般来说只有一个,或者是一个分布式数据库. ...
- JavaScript内置对象常用
Math 提供了数学中常用的属性和方法,使用时直接用Math.属性/方法,而不需要new一个Math对象 Date 使用Date对象来对日期和时间进行操作.使用时,必须用new创建一个实例 windo ...
- Thread.currentThread().getContextClassLoader().loadClass(className)和Class.forName(className)的区别
一.正文: 有去看开源框架的童鞋,应该会经常看到如下代码:Thread.currentThread().getContextClassLoader().loadClass(className),那这个 ...
- 框架开发中的junit单元测试
首先写一个测试用的公共类,如果要搭建测试环境,只要继承这个公共类就能很容易的实现单元测试,代码如下 import org.junit.runner.RunWith; import org.spring ...
- BZOJ4537 HNOI2016最小公倍数(莫队+并查集)
考虑边只有一种权值的简化情况.那么当且仅当两点可以通过边权<=x的边连通,且连通块内最大边权为x时,两点间存在路径max为x的路径.可以发现两种权值是类似的,当且仅当两点可以通过边权1<= ...
- Netscaler工作流程
Netscaler工作流程 http://blog.51cto.com/caojin/1898310 Citrix Netscaler有很多功能模块来满足应用交付的需求,为了能够做好的配置和排错工作, ...
- 【算法】高斯消元&线性代数
寒假作业~就把文章和题解3道题的代码扔在这里啦——链接: https://pan.baidu.com/s/1kWkGnxd 密码: bhh9 1.HNOI2013游走 #include <bit ...