Linux高级命令进阶(week1_day2)--技术流ken
输出重定向
场景:一般命令的输出都会显示在终端中,有些时候需要将一些命令的执行结果想要保存到文件中进行后续的分析/统计,则这时候需要使用到的输出重定向技术。
>:覆盖输出,会覆盖掉原先的文件内容
>>:追加输出,不会覆盖原始文件内容,会在原始内容末尾继续添加
2>:错误输出,会覆盖掉原先的文件内容
2>>:错误追加输出,会覆盖掉原始文件内容,会在原始内容末尾继续添加
&>:将标准输出与错误输出共同写入到文件中。覆盖原有内容
&>>:将标准输出与错误输出共同写入到文件中(追加到原有内容的后面)
标准输入重定向(STDIN,文件描述符为0):默认从键盘输入,也可从其他文件或命令中输入。
标准输出重定向(STDOUT,文件描述符为1):默认输出到屏幕。
错误输出重定向(STDERR,文件描述符为2):默认输出到屏幕。
案例1:使用覆盖输出(覆盖原文内容)
[root@ken ~]# vim test
[root@ken ~]# cat test
this is ken
[root@ken ~]# echo "this is oscar" > test
[root@ken ~]# cat test
this is oscar
案例2:使用追加输出(原文中追加)
[root@ken ~]# cat test
this is oscar
[root@ken ~]# echo "this is ken" >> test
[root@ken ~]# cat test
this is oscar
this is ken
案例3:使用错误输出重定向
默认错误输出会输出倒终端之上
[root@ken ~]# cat klkl > test #使用输出重定向无法使错误输出导入到文本中
cat: klkl: No such file or directory
[root@ken ~]# cat klkl > test #需要使用2>错误输出重定向
[root@ken ~]# cat test
cat: klkl: No such file or directory
案例4:将标准输出与错误输出共同写入到文件中
[root@ken ~]# cat klkl &> test
[root@ken ~]# cat test
cat: klkl: No such file or directory
输入重定向
工作中用到的比较少,了解即可,输入重定向的作用是把文件直接导入到命令中。
案例:统计文本行数
[root@ken ~]# wc -l < /etc/passwd
管道符
管道命令符(|)的作用是把前一个命令原本要输出到屏幕的标准正常数据当作是后一个命令的标准输入。
例如我们需要统计passwd文件包含root的行数
[root@ken ~]# cat /etc/passwd | grep "root" | wc -l
把搜索命令的输出值传递给统计命令,即把原本要输出到屏幕的用户信息列表再交给wc命令作进一步的加工,因此只需要把管道符放到两条命令之间即可
通配符
为Linux运维人员,我们有时候也会遇到明明一个文件的名称就在嘴边但就是想不起来的情况。如果就记得一个文件的开头几个字母,想遍历查找出所有以这个关键词开头的文件,该怎么操作呢?
通配符就是通用的匹配信息的符号,比如
- 星号(*)代表匹配零个或多个字符(可以为0个)
- 问号(?)代表匹配单个字符(单个字符必须存在)
- 中括号内加上数字[0-9]代表匹配0~9之间的单个数字的字符,
- 中括号内加上字母[abc]则是代表匹配a、b、c三个字符中的任意一个字符。
案例1:查看dev目录下所有以sda开头的文件
[root@ken ~]# ls /dev/sda*
/dev/sda /dev/sda1 /dev/sda2
案例2:查看dev目录下以sda开头,后面有一个字符的文件
[root@ken ~]# ls /dev/sda?
/dev/sda1 /dev/sda2
加上问号之后/dev/sda就匹配不到了
案例3:查看dev下以sda开头,后面跟上数字的文件
匹配不到sda
[root@ken ~]# ls /dev/sda[-]
/dev/sda1 /dev/sda2
案例4:查看dev下以sda开头,后面跟上字母的文件
[root@ken ~]# ls /dev/sda[a-z]
ls: cannot access /dev/sda[a-z]: No such file or directory
匹配不到任何文件,也匹配不到/dev/sda,后面跟上字符必须存在才能匹配到。
三种引号的作用
- 单引号(''):转义其中所有的变量为单纯的字符串。
- 双引号(""):保留其中的变量属性,不进行转义处理。
- 反引号(``):把其中的命令执行后返回结果。
案例1:单引号,不解释变量即所见即所得
[root@ken ~]# age=
[root@ken ~]# echo 'my age is $age'
my age is $age
案例2:双引号,解释变量
[root@ken ~]# age=
[root@ken ~]# echo "my age is $age"
my age is
案例3:反引号,用来执行命令
[root@ken ~]# name=`ls /root`
[root@ken ~]# echo $name
.txt .txt .txt .txt .txt .txt .txt .txt .txt = .txt .txt .txt .txt .txt anaconda-ks.cfg elasticsearch-6.4..tar.gz elasticsearch-6.4..tar.gz. ken kenken nohup.out redis-manager-1.1 redis-manager-1.1-release.tar.gz test test1.sh test.sh
软连接、硬连接
软连接
软连接:就是相当于windows下面的快捷方式
【软链接相当于快捷方式,硬链接相当于复制粘贴】
创建完成后,源文件、软链接和硬链接均可以查看到文件内容。
编辑源文件,软、硬链接跟着动。
删除源文件,软链接失效,硬链接无影响。再重新建一个与源文件同名的文件,软链接就直接链接到新的文件,而硬链接不变。因为软链接是按着名称进行链接。
ln -s
-s:指定源文件是谁 后面接 连接目标文件
[root@ken ~]# ln -s ken kenken
[root@ken ~]# ls
elasticsearch-6.4..tar.gz ken nohup.out redis-manager-1.1-release.tar.gz
elasticsearch-6.4..tar.gz. kenken redis-manager-1.1
往连接文件添加一些内容
[root@ken ~]# echo "this is ken" > kenken
[root@ken ~]# cat kenken
this is ken
[root@ken ~]# cat ken
this is ken
发现源文件内容同步
删除连接文件
[root@ken ~]# rm -rf kenken
[root@ken ~]# cat ken
this is ken
源文件不变
删除源文件
[root@ken ~]# rm -rf ken
[root@ken ~]# cat kenken
cat: kenken: No such file or directory
连接文件失效
再次创建源文件
[root@ken ~]# touch ken
[root@ken ~]# cat kenken
[root@ken ~]# cat ken
再重新建一个与源文件同名的文件,软链接就直接链接到新的文件。因为软链接是按着名称进行链接
总结:
软连接
ln - s 原路径 目标路径
特点:
1、就是相当于win中的快捷方式
2、删除链接文件,源文件无影响
3、删除源文件,链接文件失效
4、修改源文件\链接文件,内容都发生改变
硬链接
ln 源文件 目标文件
[root@ken ~]# ln ken ken1
[root@ken ~]# ls
elasticsearch-6.4..tar.gz ken kenken redis-manager-1.1
elasticsearch-6.4..tar.gz. ken1 nohup.out redis-manager-1.1-release.tar.gz
总结:
1、删除链接文件,源文件无影响
2、删除源文件,链接文件无影响
3、修改源文件\链接文件,内容都发生改变
一切从“/”开始
在Linux系统中,目录、字符设备、块设备、套接字等都被抽象成了文件,Linux系统中一切都是文件。既然平时我们打交道的都是文件,那么又应该如何找到它们呢?在Windows操作系统中,想要找到一个文件,我们要依次进入该文件所在的磁盘分区(假设这里是D盘),然后在进入该分区下的具体目录,最终找到这个文件。但是在Linux系统中并不存在C/D/E/F等盘符,Linux系统中的一切文件都是从“根(/)”目录开始的,并按照文件系统层次化标准(FHS)采用树形结构来存放文件,以及定义了常见目录的用途。另外,Linux系统中的文件和目录名称是严格区分大小写的。例如,root、rOOt、Root、rooT均代表不同的目录,并且文件名称中不得包含斜杠(/)。Linux系统中的
文件存储结构如图6-1所示。
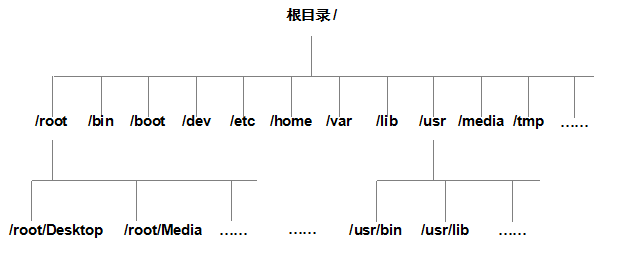
FHS是根据以往无数Linux系统用户和开发者的经验而总结出来的,是用户在Linux系统中存储文件时需要遵守的规则,用于指导我们应该把文件保存到什么位置,以及告
诉用户应该在何处找到所需的文件。但是,FHS对于用户来讲只能算是一种道德上的约束,有些用户就是懒得遵守,依然会把文件到处乱放,有些甚至从来没有听说过它。
Linux系统中常见的目录名称以及相应内容
|
目录名称 |
应放置文件的内容 |
|
/boot |
开机所需文件—内核、开机菜单以及所需配置文件等 |
|
/dev |
以文件形式存放任何设备与接口 |
|
/etc |
配置文件 |
|
/home |
用户主目录 |
|
/bin |
存放单用户模式下还可以操作的命令 |
|
/lib |
开机时用到的函数库,以及/bin与/sbin下面的命令要调用的函数 |
|
/sbin |
开机过程中需要的命令 |
|
/media |
用于挂载设备文件的目录 |
|
/opt |
放置第三方的软件 |
|
/root |
系统管理员的家目录 |
|
/srv |
一些网络服务的数据文件目录 |
|
/tmp |
任何人均可使用的“共享”临时目录 |
|
/proc |
虚拟文件系统,例如系统内核、进程、外部设备及网络状态等 |
|
/usr/local |
用户自行安装的软件 |
|
/usr/sbin |
Linux系统开机时不会使用到的软件/命令/脚本 |
|
/usr/share |
帮助与说明文件,也可放置共享文件 |
|
/var |
主要存放经常变化的文件,如日志 |
| /lost+found |
当文件系统发生错误时,将一些丢失的文件片段存放在这里 |
绝对路径vs相对路径
在Linux系统中另外还有一个重要的概念—路径。
路径指的是如何定位到某个文件,分为绝对路径与相对路径。
绝对路径指的是从根目录(/)开始写起的文件或目录名称
相对路径则指的是相对于当前路径的写法。
Linux高级命令进阶(week1_day2)--技术流ken的更多相关文章
- Linux高级命令进阶(week1_day2)
Linux高级命令进阶(week1_day2)--技术流ken 输出重定向 场景:一般命令的输出都会显示在终端中,有些时候需要将一些命令的执行结果想要保存到文件中进行后续的分析/统计,则这时候 ...
- Linux高级命令进阶
输出重定向 场景:一般命令的输出都会显示在终端中,有些时候需要将一些命令的执行结果想要保存到文件中进行后续的分析/统计,则这时候需要使用到的输出重定向技术. >:覆盖输出,会覆盖掉原先的文件内容 ...
- Redis基础认识及常用命令使用(一)--技术流ken
Redis简介 redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合)和zset(有序集 ...
- 20190402Linux高级命令进阶(week1_day2
Linux高级命令进阶(week1_day2) 输出重定向 场景:一般命令的输出都会显示在终端中,有些时候需要将一些命令的执行结果想要保存到文件中进行后续的分析/统计,则这时候需要使用到的输出重定向技 ...
- Redis Cluster集群架构实现(四)--技术流ken
Redis集群简介 通过前面三篇博客的介绍<Redis基础认识及常用命令使用(一)--技术流ken>,<Redis基础知识补充及持久化.备份介绍(二)--技术流ken>,< ...
- Redis基础知识补充及持久化、备份介绍(二)--技术流ken
Redis知识补充 在上一篇博客<Redis基础认识及常用命令使用(一)--技术流ken>中已经介绍了redis的一些基础知识,以及常用命令的使用,本篇博客将补充一些基础知识以及redis ...
- 进阶!基于CentOS7系统使用cobbler实现单台服务器批量自动化安装不同版本系统(week3_day5_part2)-技术流ken
前言 在上一篇博文<cobbler批量安装系统使用详解-技术流ken>中已经详细讲解了cobbler的使用以及安装,本篇博文将会使用单台cobbler实现自动化批量安装不同版本的操作系统. ...
- 网站集群架构(LVS负载均衡、Nginx代理缓存、Nginx动静分离、Rsync+Inotify全网备份、Zabbix自动注册全网监控)--技术流ken
前言 最近做了一个不大不小的项目,现就删繁就简单独拿出来web集群这一块写一篇博客.数据库集群请参考<MySQL集群架构篇:MHA+MySQL-PROXY+LVS实现MySQL集群架构高可用/高 ...
- Docker网络(五)--技术流ken
本章内容 1.dokcer默认自带的几种网络介绍 2. 自定义网络 3. 容器间通信 4. 容器与外界交互 docker网络分为单个主机上的容器网络和多个主机上的哇网络,本文主要讲解单个主机上的容器网 ...
随机推荐
- BZOJ_3261_最大异或和_可持久化trie
BZOJ_3261_最大异或和_可持久化trie Description 给定一个非负整数序列{a},初始长度为N. 有M个操作,有以下两种操作类型: 1.Ax:添加操作,表示在序列末尾添加一个数x, ...
- C++解析头文件-Qt自动生成信号声明
目录 一.瞎白话 二.背景 三.思路分析 四.代码讲解 1.类图 2.内存结构声明 3.QtHeaderDescription 4.私有函数讲解 五.分析结果 六.下载 一.瞎白话 时间过的ZTMK, ...
- 『这是一篇干货blog』
更新记录一些很好的干货博客以及工具网站. 各文章,工具网站版权归原作者所有,侵删. Articles 浅谈C++ IO优化--读优输优方法集锦 浅谈斜率优化 思维导图好助手--开心食用Xmind Ty ...
- [区块链|非对称加密] 对数字证书(CA认证)原理的回顾
摘要:文中首先解释了加密解密的一些基础知识和概念,然后通过一个加密通信过程的例子说明了加密算法的作用,以及数字证书的出现所起的作用.接着对数字证书做一个详细的解释,并讨论一下windows中数字证书的 ...
- springboot中HandlerMethodArgumentResolver的使用
springboot项目中在所有的controller方法中想增加token验证,即所有的方法都必须登陆有token之后才能访问.springboot封装了SpringMVC中的HandlerMeth ...
- 带你找到五一最省的旅游路线【dijkstra算法推导详解】
前言 五一快到了,小张准备去旅游了! 查了查到各地的机票 因为今年被扣工资扣得很惨,小张手头不是很宽裕,必须精打细算.他想弄清去各个城市的最低开销. [嗯,不用考虑回来的开销.小张准备找警察叔叔说自己 ...
- [深度应用]·实战掌握Dlib人脸识别开发教程
[深度应用]·实战掌握Dlib人脸识别开发教程 个人网站--> http://www.yansongsong.cn/ 项目GitHub地址--> https://github.com/xi ...
- Web前后端分离
第一篇博客:见谅 用自己的通俗语言讲web工程的前后端分离: 只是从自己的角度去分析,我眼中的前后端分离(可能不对) 首先要明白我们服务器和浏览器之前传输和接受的是什么: 静态文件(html,css, ...
- 使用Ninject的一般步骤
以下为DI控制反转个人理解烦请各位大牛指教~ 编写程序时我们应当遵循抵耦合高内聚的原则(各个功能模块互不依赖). 我们可以利用面向对象里面接口的特性来进行DI控制反转,让功能模块全部依赖接口,而不依赖 ...
- Angular(01)-- 架构概览
声明 本系列文章内容梳理自以下来源: Angular 官方中文版教程 官方的教程,其实已经很详细且易懂,这里再次梳理的目的在于复习和巩固相关知识点,刚开始接触学习 Angular 的还是建议以官网为主 ...