将Excel导出为SQL语句
需求说明:公司做项目前进行需求分析,确定表结构后需要建表,如果照着表格去敲,那就太麻烦了,所以想到了自动生成SQL语句。
思路大概就是:解析Excel,拼接SQL语句,输出SQL文件。
第三方jar包:POI(解析Excel)
先建立一个maven项目。
pom依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.transition</groupId>
<artifactId>excel-to-sql</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.17</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi-ooxml -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.17</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi-ooxml-schemas -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>3.17</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.xmlbeans/xmlbeans -->
<dependency>
<groupId>org.apache.xmlbeans</groupId>
<artifactId>xmlbeans</artifactId>
<version>2.6.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/dom4j/dom4j -->
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
</dependencies> <build>
<plugins>
<!-- 编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build> </project>
目录结构
Keys.Java
package com.transition.core.common;
public class Keys {
public static final String TABLE_PRE = "DROP TABLE IF EXISTS ";
public static final String TABLE_SUFF = "ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=";
public static final String C_T = "CREATE TABLE ";
public static final String N_N = " NOT NULL ";
public static final String A_I = "AUTO_INCREMENT";
public static final String P_K = "PRIMARY KEY ";
public static final String F_K = " FOREIGN KEY ";
public static final String COMMENT = " COMMENT ";
public static final String DEFAULT = " DEFAULT ";
}
DataTable.Java
package com.transition.core.entity; import java.util.ArrayList;
import java.util.List; /**
* 数据库表
*/
public class DataTable { private String tableName; // 数据库表名
private String comment; //数据库注释
private List<TableField> fields = new ArrayList<>(); public DataTable() {
} public DataTable(String tableName, String comment) {
this.tableName = tableName;
this.comment = comment;
} public String getTableName() {
return tableName;
} public void setTableName(String tableName) {
this.tableName = tableName;
} public String getComment() {
return comment;
} public void setComment(String comment) {
this.comment = comment;
} public List<TableField> getFields() {
return fields;
} public void setFields(List<TableField> fields) {
this.fields = fields;
} @Override
public String toString() {
return "DataTable{" +
"tableName='" + tableName + '\'' +
", comment='" + comment + '\'' +
", fields=" + fields +
'}';
}
}
TableField.Java
package com.transition.core.entity; /**
* 表字段
*/
public class TableField { private String fieldName; // 字段名
private String fieldType; // 字段类型
private String isNull; // 是否为空
private String defaultValue;// 默认值
private String comment; // 注释 public TableField() {
} public TableField(String fieldName, String fieldType, String isNull, String defaultValue, String comment) {
this.fieldName = fieldName;
this.fieldType = fieldType;
this.isNull = isNull;
this.defaultValue = defaultValue;
this.comment = comment;
} public String getFieldName() {
return fieldName;
} public void setFieldName(String fieldName) {
this.fieldName = fieldName;
} public String getFieldType() {
return fieldType;
} public void setFieldType(String fieldType) {
this.fieldType = fieldType;
} public String getIsNull() {
return isNull;
} public void setIsNull(String isNull) {
this.isNull = isNull;
} public String getDefaultValue() {
return defaultValue;
} public void setDefaultValue(String defaultValue) {
this.defaultValue = defaultValue;
} public String getComment() {
return comment;
} public void setComment(String comment) {
this.comment = comment;
} @Override
public String toString() {
return "TableField{" +
"fieldName='" + fieldName + '\'' +
", fieldType='" + fieldType + '\'' +
", isNull='" + isNull + '\'' +
", defaultValue='" + defaultValue + '\'' +
", comment='" + comment + '\'' +
'}';
}
}
Core
package com.transition.core; import com.transition.core.common.Keys;
import com.transition.core.entity.DataTable;
import com.transition.core.entity.TableField;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.CellType;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook; import java.io.*;
import java.util.ArrayList;
import java.util.List; public class Core { private static int tableNum = 0;
private static int sentry = -1; // 哨兵 public static List<DataTable> readXlsx(String path){
List<DataTable> list = new ArrayList<>();
System.out.println("读取...");
InputStream in = null;
try {
in = new FileInputStream(path);
XSSFWorkbook xss = new XSSFWorkbook(in); for(int i = 0; i < xss.getNumberOfSheets(); i++){
XSSFSheet sheet = xss.getSheetAt(i);
if(sheet == null)
continue; for(int r = 0; r <= sheet.getLastRowNum(); r++){
XSSFRow row = sheet.getRow(r);
if(row != null){
// 如果哨兵等于0,代表这一行是不需要读取的。continue之后自减1
if (sentry-- == 0){
continue;
}
/*
_NONE(-1),
NUMERIC(0),
STRING(1),
FORMULA(2),
BLANK(3),
BOOLEAN(4),
ERROR(5);
*/
CellType cellType2 = row.getCell(2).getCellTypeEnum();
CellType cellType3 = row.getCell(3).getCellTypeEnum();
CellType cellType4 = row.getCell(4).getCellTypeEnum();
if (cellType2 == CellType.BLANK && cellType3 == CellType.BLANK && cellType4 == CellType.BLANK){
++tableNum;
sentry = 0; String name = row.getCell(0).getStringCellValue().toLowerCase();
String comment = row.getCell(1).getStringCellValue(); list.add(new DataTable(name, comment));
System.out.println("----------------------Table-------------------");
System.out.println("表名:" + name + ",注释:" + comment);
continue;
} if(cellType3 == CellType.NUMERIC)
list.get(list.size()-1).getFields().add(new TableField(row.getCell(0).getStringCellValue(),
row.getCell(1).getStringCellValue(),
row.getCell(2).getStringCellValue(),
Math.round(row.getCell(3).getNumericCellValue())+"",
row.getCell(4).getStringCellValue()));
else
list.get(list.size()-1).getFields().add(new TableField(row.getCell(0).getStringCellValue(),
row.getCell(1).getStringCellValue(),
row.getCell(2).getStringCellValue(),
row.getCell(3).getStringCellValue(),
row.getCell(4).getStringCellValue())); } } }
in.close(); } catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return list;
} public static void exportToSQL(List<DataTable> list, String sqlPath) throws IOException {
final List<String> sql = new ArrayList<>();
list.forEach(e -> {
sentry = 1;
StringBuilder sb = new StringBuilder();
sb.append(Keys.TABLE_PRE + "`" + e.getTableName() + "`;\n");
sb.append(Keys.C_T + "`" + e.getTableName() + "` (\n");
e.getFields().forEach(c -> {
// 只有主键有自增
if (sentry == 1){
sb.append("`" + c.getFieldName().toLowerCase() + "` " + c.getFieldType().toLowerCase() + Keys.N_N + Keys.A_I + Keys.COMMENT + "'" + c.getComment() + "',\n");
sentry = 0;
}else {
// 如果无默认值
if (c.getDefaultValue() == null || c.getDefaultValue().equals("")){
// 如果不为空,或者无标志,一律按照不为空处理
if ("N".equals(c.getIsNull()) || "".equals(c.getIsNull()) || c.getIsNull() == null)
sb.append("`" + c.getFieldName().toLowerCase() + "` " + c.getFieldType().toLowerCase() + Keys.N_N + Keys.COMMENT + "'" + c.getComment() + "',\n");
else
sb.append("`" + c.getFieldName().toLowerCase() + "` " + c.getFieldType().toLowerCase() + Keys.COMMENT + "'" + c.getComment() + "',\n");
} else{
// 如果不为空,或者无标志,一律按照不为空处理
if ("N".equals(c.getIsNull()) || "".equals(c.getIsNull()) || c.getIsNull() == null)
sb.append("`" + c.getFieldName().toLowerCase() + "` " + c.getFieldType().toLowerCase() + Keys.N_N + Keys.DEFAULT + "'" + c.getDefaultValue() + "'" + Keys.COMMENT + "'" + c.getComment() + "',\n");
else
sb.append("`" + c.getFieldName().toLowerCase() + "` " + c.getFieldType().toLowerCase() + Keys.DEFAULT + "'" + c.getDefaultValue() + "'" + Keys.COMMENT + "'" + c.getComment() + "',\n");
} } });
sb.append(Keys.P_K + "(`" + e.getFields().get(0).getFieldName().toLowerCase() + "`)\n" +
") " + Keys.TABLE_SUFF + "'" + e.getComment() + "';\n\n");
System.out.println(sb.toString());
sql.add(sb.toString());
}); File file = new File(sqlPath);
FileOutputStream out = new FileOutputStream(file);
sql.forEach(s -> {
try {
out.write(s.getBytes());
} catch (IOException e) {
e.printStackTrace();
}
});
out.close();
} public static int getTableNum() {
return tableNum;
}
}
RunApplication
package com.transition.core; import com.transition.core.entity.DataTable; import java.io.IOException;
import java.util.List; public class RunApplication { public static void main(String[] args) throws IOException {
List<DataTable> tables = Core.readXlsx("table2.xlsx");
// tables.forEach(e -> System.out.println(e));
Core.exportToSQL(tables,"test.sql");
System.out.println("TableNumber : " + Core.getTableNum());
}
}
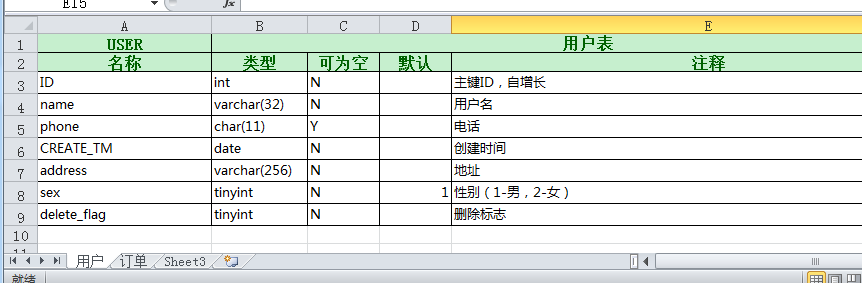
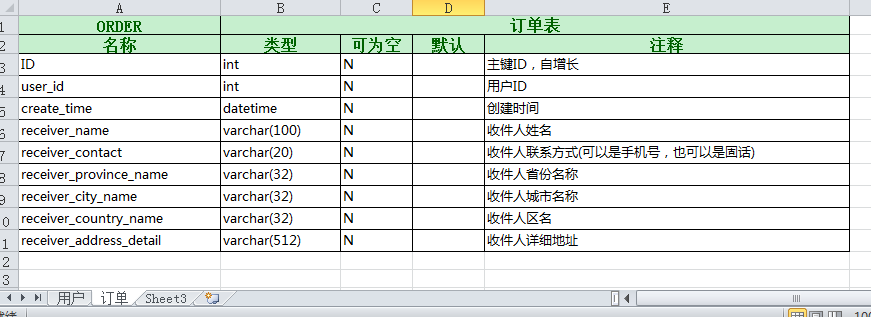
我要读取table2.xlsx,输出到test.sql
运行,输出结果:
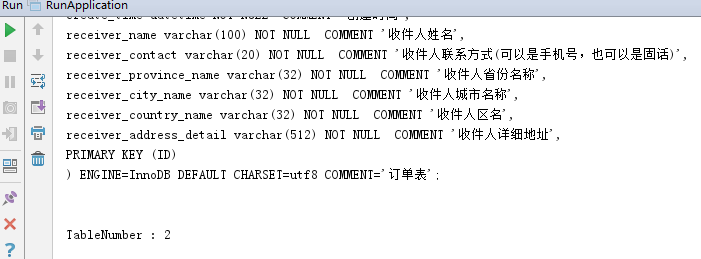
查看sql文件
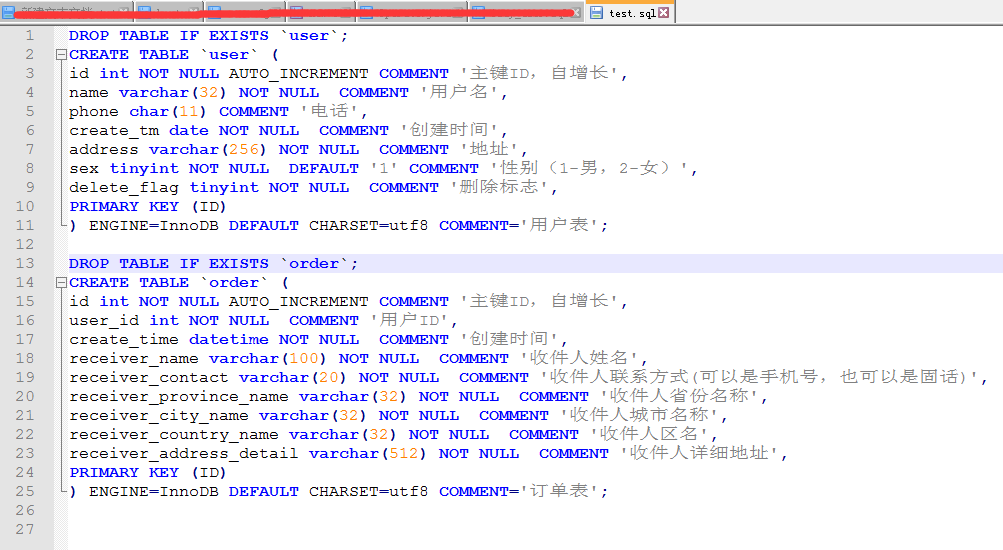
在Navicat里面运行这个sql文件

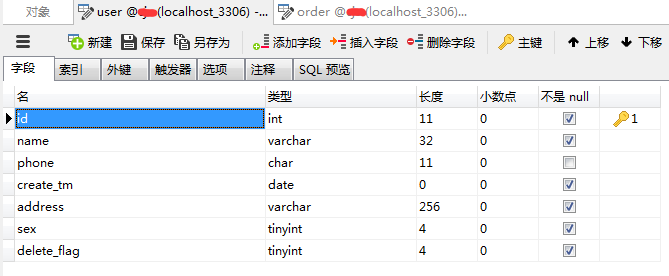
可以看到,字段名全部是小写,类型,长度,字段注释都正确设置,是否为空也符合要求。
不过有个事情:如果你要添加外键依赖,触发器之类的要自己手动去配置。另外,这个代码有点特定为这种格式的表格,如果你不是这种结果的表格,很可能不成功。
如果你不会改就叫我好了
不过,如果你有很多表的话,帮你生成已经节省很多时间了,还要啥自行车啊
将Excel导出为SQL语句的更多相关文章
- Mysql中文乱码以及导出为sql语句和Excel问题解决
Mysql中文乱码以及导出为sql语句和Excel问题解决 这几天基于Heritrix写了一个爬虫,用到mysql,在导入导出数据时,遇到一些乱码问题,好不容易解决了,记录一下,以备查看.一.导出数据 ...
- Excel数据生成Sql语句的方法
选中想要生成的列,套用表格格式,选中表包含标题的选项确定,然后在最右边的一列第二行处,点击函数功能,选择CONCATENATE,在文本里输入想要的结构即可 代码如下 复制代码 ,=CONCATENA ...
- 在Excel中使用SQL语句查询和筛选
本文转自:http://blog.sina.com.cn/s/blog_5fc375650102e1g5.html 今天在微博上看到@数据分析精选 分享的一篇文章,是关于<在Excel中使用SQ ...
- Excel 中使用sql语句查询
将Excel连接Oracle数据库 Excel选项板中"数据"—"自其他来源"下拉菜单中有有个可以连接其它数据库的选项"来自数据连接向导"和 ...
- Visio2010建立ER图并直接导出为SQL语句
Visio2010建立ER图并直接导出为SQL语句 2013年08月20日 ⁄ 综合 ⁄ 共 2581字 ⁄ 字号 小 中 大 ⁄ 评论关闭 建立数据库时我们需要考虑数据之间的关系,为了理清数据之间的 ...
- 通过Excel生成批量SQL语句
项目中有时会遇到这样的要求:用户给发过来一些数据,要我们直接给存放到数据库里面,有的是Insert,有的是Update等等,少量的数据我们可以采取最原始的办法,也就是在SQL里面用Insert int ...
- 在EXCEL中使用SQL语句查询
SQL语句在数据库使用中十分重要. 在EXCEL中可以不打开工作簿,就获取数据,对多工作簿操作很用,也很快. 对大量数据处理,比循环快很多,但是比词典方法还有点距离(可惜我还没有学会词典). 对数据库 ...
- [转]在Excel中使用SQL语句实现精确查询
本文转自:http://blog.sina.com.cn/s/blog_5fc375650102e1g5.html 今天在微博上看到@数据分析精选 分享的一篇文章,是关于<在Excel中使用SQ ...
- 【分享】通过Excel生成批量SQL语句,处理大量数据的好办法
我们经常会遇到这样的要求:用户给发过来一些数据,要我们直接给存放到数据库里面,有的是Insert,有的是Update等等,少量的数据我们可以采取最原始的办法,也就是在SQL里面用Insert into ...
随机推荐
- docker学习笔记二
知识点: 1)手动构建镜像 2)Dockerfile快速构建镜像 阿里云yum源https://opsx.alibaba.com/mirror 镜像制作nginx镜像实例 创建并运行centos容器 ...
- 记一次tomcat7.0版本启动项目失败问题
测试项目在tomcat7中启动失败,报错如下: @794314bc3 Error during job execution (jobs.Bootstrap) Oops: VerifyError ~ p ...
- git和svn的區別
https://blog.csdn.net/bmicnj/article/details/78413058
- git 提交的步骤
1. git init //初始化仓库 2. git add .(文件name) //添加文件到本地仓库 3. git commit -m "first commit" / ...
- essential-phone的相关体验
一.adb环境配置 1.下载adb工具 工具网上一搜一大把,注意路径不能有中文. 2.系统配置环境变量 找到环境变量,点击新建.变量名根据自己的习惯随便建,变量值为下载的adb工具解压后存放的路径. ...
- josn的格式化
public String formatJson(Object obj) { com.alibaba.fastjson.JSONObject json=(com.alibaba.fastjson.JS ...
- Simple Use IEnumerable<T>
Private static IEnumerable<T> FunDemo(T para) { while(...) { .... yield return Obj; } } static ...
- poj-2337(欧拉回路输出)
题意:给你n个字符串,每个字符串可以和另一个字符串连接的前提是,前一个字符串的尾字符等于后一个字符串的首字符,问你存不存在欧拉通路并输出 解题思路:基本标准流程,建图:把一个字符串可以看作一条首字符指 ...
- Django auth认证系统
Django自带的用户认证 我们在开发一个网站的时候,无可避免的需要设计实现网站的用户系统.此时我们需要实现包括用户注册.用户登录.用户认证.注销.修改密码等功能,这还真是个麻烦的事情呢. Djang ...
- 大学jsp实验4include,forword
一.实验目的与要求 1.掌握常用JSP动作标记的使用. 二.实验内容 1.include动作标记的使用 编写一个名为shiyan4_1.jsp的JSP页面,页面内容自定,但要求使用include动作标 ...