http协议、web服务器、并发服务器(上)
1. HTTP格式
每个HTTP请求和响应都遵循相同的格式,一个HTTP包含Header和Body两部分,其中Body是可选的。HTTP协议是一种文本协议,所以,它的格式也非常简单。
1.1 HTTP GET请求的格式:
GET /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
1.2 HTTP POST请求的格式:
POST /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...
当遇到连续两个\r\n时,Header部分结束,后面的数据全部是Body。
1.3 HTTP响应的格式:
HTTP/1.1 200 OK
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...
HTTP响应如果包含body,也是通过\r\n\r\n来分隔的。
请再次注意,Body的数据类型由Content-Type头来确定,如果是网页,Body就是文本,如果是图片,Body就是图片的二进制数据。
当存在Content-Encoding时,Body数据是被压缩的,最常见的压缩方式是gzip,所以,看到Content-Encoding: gzip时,需要将Body数据先解压缩,才能得到真正的数据。压缩的目的在于减少Body的大小,加快网络传输。
2. Web静态服务器-显示固定的页面
import socket
def handle_client(new_client):
"""处理客户端请求"""
recv_data = new_client.recv(1024)
print(recv_data)
# 组装响应的内容
response_headers = "HTTP/1.1 200 OK\r\n"
response_headers += "\r\n"
response_body = "6666"
response = response_headers + response_body
new_client.send(response.encode("utf-8"))
new_client.close()
def main():
# 创建套接字
tcp_socket_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定本地消息
tcp_socket_server.bind(("", 8090))
# 套接字由主动变被动
tcp_socket_server.listen(128)
while True:
# 接收新的请求
new_client, client_addr = tcp_socket_server.accept()
handle_client(new_client)
# 关闭套接字
tcp_socket_server.close()
if __name__ == "__main__":
main()
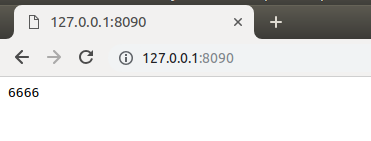
如上的代码仅仅只是向浏览器发送了简单的文本内容:6666
在浏览器中访问:
3. Web静态服务器-显示需要的页面
import socket
import re
def handle_client(new_client):
"""处理客户端请求"""
recv_data = new_client.recv(1024).decode("utf-8")
# GET / HTTP/1.1
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line)
http_request_line = request_header_lines[0];
get_file_name = re.match("[^/]+(/[^ ]*)", http_request_line).group(1)
print("file name is -> " + get_file_name)
# print(recv_data)
if get_file_name == "/":
get_file_name = "/index.html"
root_path = "./html"
get_file_name = root_path + get_file_name;
try:
f = open(get_file_name, "rb")
except:
response_headers = "HTTP/1.1 404 NOT FOUND\r\n"
response_headers += "\r\n"
response_body = b"page not found"
else:
# 组装响应的内容
response_headers = "HTTP/1.1 200 OK\r\n"
response_headers += "\r\n"
response_body = f.read()
f.close()
new_client.send(response_headers.encode("utf-8"))
new_client.send(response_body)
new_client.close()
def main():
# 创建套接字
tcp_socket_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定本地消息
tcp_socket_server.bind(("", 8090))
# 套接字由主动变被动
tcp_socket_server.listen(128)
while True:
# 接收新的请求
new_client, client_addr = tcp_socket_server.accept()
handle_client(new_client)
# 关闭套接字
tcp_socket_server.close()
if __name__ == "__main__":
main()
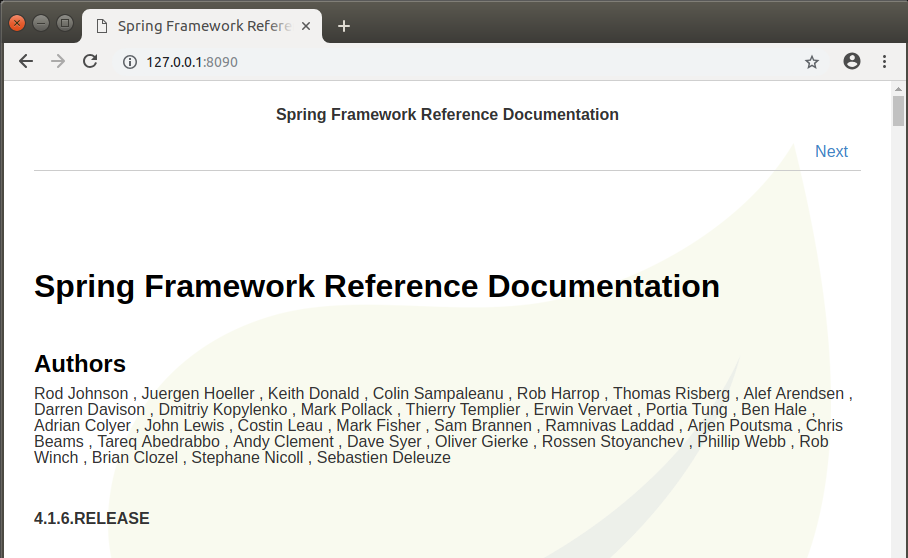
在浏览器中访问:
4. Web静态服务器-多进程版
import socket
import re
import multiprocessing
def handle_client(new_client):
"""处理客户端请求"""
recv_data = new_client.recv(1024).decode("utf-8")
# GET / HTTP/1.1
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line)
http_request_line = request_header_lines[0];
get_file_name = re.match("[^/]+(/[^ ]*)", http_request_line).group(1)
print("file name is -> " + get_file_name)
# print(recv_data)
if get_file_name == "/":
get_file_name = "/index.html"
root_path = "./html"
get_file_name = root_path + get_file_name;
try:
f = open(get_file_name, "rb")
except:
response_headers = "HTTP/1.1 404 NOT FOUND\r\n"
response_headers += "\r\n"
response_body = b"page not found"
else:
# 组装响应的内容
response_headers = "HTTP/1.1 200 OK\r\n"
response_headers += "\r\n"
response_body = f.read()
f.close()
new_client.send(response_headers.encode("utf-8"))
new_client.send(response_body)
new_client.close()
def main():
# 创建套接字
tcp_socket_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定本地消息
tcp_socket_server.bind(("", 8090))
# 套接字由主动变被动
tcp_socket_server.listen(128)
while True:
# 接收新的请求
new_client, client_addr = tcp_socket_server.accept()
p = multiprocessing.Process(target=handle_client, args=(new_client,))
p.start()
new_client.close()
# 关闭套接字
tcp_socket_server.close()
if __name__ == "__main__":
main()
5. Web静态服务器-多线程版
import socket
import re
import threading
def handle_client(new_client):
"""处理客户端请求"""
recv_data = new_client.recv(1024).decode("utf-8")
# GET / HTTP/1.1
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line)
http_request_line = request_header_lines[0];
get_file_name = re.match("[^/]+(/[^ ]*)", http_request_line).group(1)
print("file name is -> " + get_file_name)
# print(recv_data)
if get_file_name == "/":
get_file_name = "/index.html"
root_path = "./html"
get_file_name = root_path + get_file_name;
try:
f = open(get_file_name, "rb")
except:
response_headers = "HTTP/1.1 404 NOT FOUND\r\n"
response_headers += "\r\n"
response_body = b"page not found"
else:
# 组装响应的内容
response_headers = "HTTP/1.1 200 OK\r\n"
response_headers += "\r\n"
response_body = f.read()
f.close()
new_client.send(response_headers.encode("utf-8"))
new_client.send(response_body)
new_client.close()
def main():
# 创建套接字
tcp_socket_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定本地消息
tcp_socket_server.bind(("", 8090))
# 套接字由主动变被动
tcp_socket_server.listen(128)
while True:
# 接收新的请求
new_client, client_addr = tcp_socket_server.accept()
t = threading.Thread(target=handle_client, args=(new_client,))
t.start()
# 关闭套接字
tcp_socket_server.close()
if __name__ == "__main__":
main()
6. Web静态服务器-gevent版
import socket
import re
import gevent
from gevent import monkey
monkey.patch_all()
def handle_client(new_client):
"""处理客户端请求"""
recv_data = new_client.recv(1024).decode("utf-8")
# GET / HTTP/1.1
request_header_lines = recv_data.splitlines()
for line in request_header_lines:
print(line)
http_request_line = request_header_lines[0];
get_file_name = re.match("[^/]+(/[^ ]*)", http_request_line).group(1)
print("file name is -> " + get_file_name)
# print(recv_data)
if get_file_name == "/":
get_file_name = "/index.html"
root_path = "./html"
get_file_name = root_path + get_file_name;
try:
f = open(get_file_name, "rb")
except:
response_headers = "HTTP/1.1 404 NOT FOUND\r\n"
response_headers += "\r\n"
response_body = b"page not found"
else:
# 组装响应的内容
response_headers = "HTTP/1.1 200 OK\r\n"
response_headers += "\r\n"
response_body = f.read()
f.close()
new_client.send(response_headers.encode("utf-8"))
new_client.send(response_body)
new_client.close()
def main():
# 创建套接字
tcp_socket_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket_server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定本地消息
tcp_socket_server.bind(("", 8090))
# 套接字由主动变被动
tcp_socket_server.listen(128)
while True:
# 接收新的请求
new_client, client_addr = tcp_socket_server.accept()
g = gevent.spawn(handle_client, new_client)
g.join()
# 关闭套接字
tcp_socket_server.close()
if __name__ == "__main__":
main()
http协议、web服务器、并发服务器(上)的更多相关文章
- web服务器-并发服务器2
阅读目录 1.Web静态服务器-5-非堵塞模式 2.Web静态服务器-6-epoll 3.Web静态服务器-7-gevent版 4.知识扩展-C10K问题 一.Web静态服务器-5-非堵塞模式 单进程 ...
- 14_Web服务器-并发服务器
1.服务器概述 1.硬件服务器(IBM,HP): 主机 集群 2.软件服务器(HTTPserver Django flask): 网络服务器,在后端提供网络功能逻辑处理数据处理的程序或者架构等 3.服 ...
- Python复习笔记(十)Http协议--Web服务器-并发服务器
1. HTTP协议(超文本传输协议) 浏览器===>服务器发送的请求格式如下:(浏览器告诉服务器,浏览器的信息) GET / HTTP/1.1 Host: www.baidu.com Conne ...
- Web服务器-并发服务器-Epoll(3.4.5)
@ 目录 1.介绍 2.代码 关于作者 1.介绍 epoll是一种解决方案,nginx就是用的这个 中心思想:不要再使用多进程,多线程了,使用单进程,单线程去实现并发 在上面博客实现的代码中使用过的轮 ...
- Web服务器-并发服务器-单进程单线程非堵塞方式(3.4.3)
@ 目录 1.分析 2.代码 关于作者 1.分析 当socket去监听的时候,是堵塞的状态 通过tcp_sever_socket.setblocking(False)去设置不堵塞 当socket发现没 ...
- Web服务器-并发服务器-长连接(3.4.4)
@ 目录 1.说明 2.代码 关于作者 1.说明 每次new_socket都被强制关闭,造成短连接 所提不要关闭套接字 但是不关闭的话,浏览器不知道发完没有啊 此时用到header的属性Content ...
- Web服务器-并发服务器-协程 (3.4.2)
@ 目录 1.分析 2.代码 关于作者 1.分析 随着网站的用户量越来愈多,通过多进程多线程的会力不从心 使用协程可以缓解这一问题 只要使用gevent实现 2.代码 from socket impo ...
- Web服务器-并发服务器-多进程(3.4.1)
@ 目录 1.优化分析 2.代码 3. 关于作者 1.优化分析 在单进程的时候,相当于 是来一个客户,派一个人去服务一下 效率低,现在使用多进程来服务 假设场景 100个人同时访问页面 单进程:一次处 ...
- linux学习之多高并发服务器篇(一)
高并发服务器 高并发服务器 并发服务器开发 1.多进程并发服务器 使用多进程并发服务器时要考虑以下几点: 父最大文件描述个数(父进程中需要close关闭accept返回的新文件描述符) 系统内创建进程 ...
- 手把手让你实现开源企业级web高并发解决方案(lvs+heartbeat+varnish+nginx+eAccelerator+memcached)
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://freeze.blog.51cto.com/1846439/677348 此文凝聚 ...
随机推荐
- redis & memcache 性能比较
redis和memcache非常像的,都是key,value的方式,将数据存放内存中.最近在学习redis,在网上看了一些这方面的资料,有三种观点: redis读写内存比memcache快 memca ...
- Java中线程同步锁和互斥锁有啥区别?看完你还是一脸懵逼?
首先不要钻概念牛角尖,这样没意义. 也许java语法层面包装成了sycnchronized或者明确的XXXLock,但是底层都是一样的.无非就是哪种写起来方便而已. 锁就是锁而已,避免多个线程对同一个 ...
- Android 自定义 View 绘制
在 Android 自定义View 里面,介绍了自定义的View的基本概念.同时在 Android 控件架构及View.ViewGroup的测量 里面介绍了 Android 的坐标系 View.Vie ...
- (转载)Javascript 中的非空判断 undefined,null, NaN的区别
原文地址:https://blog.csdn.net/oscar999/article/details/9353713 在介绍这三个之间的差别之前, 先来看一下JS 的数据类型. 在 Java ,C ...
- 第39节:Java当中的IO
Java当中的IO IO的分类 第一种分:输入流和输出流 第二种分:字节流和字符流 第三种分:节点流和处理流 节点流处理数据,处理流是节点流基础上加工的. IO中的重点: InputStream Ou ...
- CSS3——:nth-child选择器基本用法简述
注:n 是从1开始的 :nth-child 是 CSS3 提供的一个好用的选择器,因为在项目中经常用到,所以简单总结了它的常用方法 下面示例代码截图用的是同一个例子,p元素的父元素都是body p ...
- ansible中include_tasks和import_tasks
简介 本文主要总结下ansible里task调用的方法有哪些和它们的主要区别 随着要管理的服务不断增多,我们又没将task放到roles里,会发现playbook文件越来越大,内容也越来越多,管理起 ...
- Winginx nginx 启动提示80端口被占用
第一步:查看80端口占用信息 win键+R运行命令:cmd-->netstat -aon|findstr "80" 2.结束任务 找到 pin=4272这个进程,将进程结束 ...
- python 输入一个字符串,打印出它所有的组合
import itertools str = input('请输入一个字符串:') lst = [] for i in range(1, len(str)+1): lst1 = [''.join(x) ...
- pyengine介绍及使用
一个可以通过HTTP请求动态执行Python 代码的HTTP服务器,还自带一个装饰器来执行时间较长的任务. 使用方法 1 pip install pyengine 2 pyengine run -d ...