11g SPA (sql Performance Analyze) 进行升级测试
注;转自http://ju.outofmemory.cn/entry/77139
11G的新特性SPA(SQL Performance Analyze)现在被广泛的应用到升级和迁移的场景。当然还有一些其他的场景可以考虑使用,比如(参数修改,I/O子系统变更),但是主要是为了帮助我们检测升级之后性能退化的那些SQL语句,用以防止升级后SQL性能退化导致无法使用的问题。如下图所示:
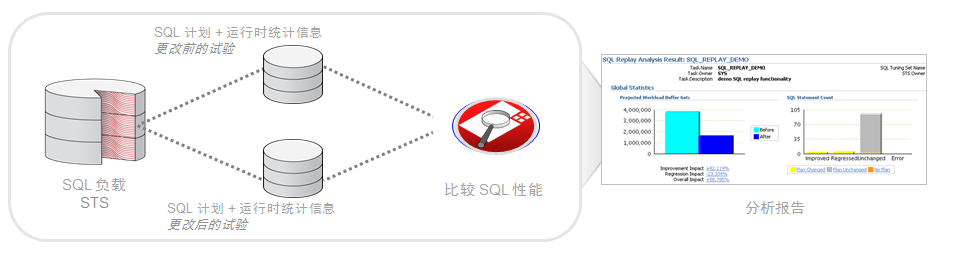
SPA的主要功能集实施步骤如下:
- 在生产系统上捕捉SQL负载,并生成SQL Tuning Set;
- 创建一个中转表,将SQL Tuning Set导入到中转表,导出中转表并传输到测试库;
- 导入中转表,并解压中转表的数据到SQL Tuning Set;
- 创建SPA任务,先生成10g的trail,然后在11g中再生成11g的trail;
- 执行比较任务,再生成SPA报告;
- 分析性能退化的SQL语句;
在使用SPA的时候,首先我们一定要阅读文档:Using Real Application Testing Functionality in Earlier Releases (文档 ID 560977.1),主要是阅读Table 3: SQL Performance Analyzer Availability Information。这个表格告诉我们,我们可以确认从那个源端版本到那个目标版本做SPA需要安装那些必要的补丁。
1.在生产系统上捕捉SQL负载,并生成SQL Tuning Set
这个步骤其实不是很复杂,我的一篇文章介绍过关于这个采集的过程。其实采集的方法有很多种,主要是:
- cursor cache
- awr snapshots
- awr baseline
- another sql set
- 10046 trace file(11g+)
我们一般使用的是游标采集和AWR历史资料库采集的方式。游标采集可以最大限度的帮助我们采集到更多的SQL语句。为了保证采集到更多的SQL,我们需要进行一个长期的捕捉,每天捕捉好几次。我们在一个生产环境做的是捕捉4次/天。而AWR历史资料库可以帮我们采集到TOP的SQL语句。我们生产环境的项目里面是采集的是一个月的AWR数据。这两份的合集加在一起基本上是系统中一个比较完整的SQL清单。
【注】采集的过程中可能因为有literal sql,这会导致我们的SQLSET的结果集非常大,因为相关的表涉及到一些CLOB字段,如果结果集过大的话,将导致转换成中间表非常的慢。转换到一半因为UNDO不够大,还还会导致出现ORA-01555错误。为了解决这个问题,我建议在采集的过程中实施过滤。具体参考我写的文档:SPA游标采集之去除重复
--------------新建spa用户及赋权
SQL> create user spa identified by spa default tablespace spa;
User created.
SQL> grant connect ,resource to spa;
Grant succeeded.
SQL> grant ADMINISTER SQL TUNING SET to spa;
Grant succeeded.
SQL> grant execute on dbms_sqltune to spa;
Grant succeeded.
SQL> grant select any dictionary to spa;
Grant succeeded.
-------------创建sql优化集
SQL> exec dbms_sqltune.create_sqlset('sql_test');
PL/SQL procedure successfully completed.
SQL> select name,OWNER,CREATED,STATEMENT_COUNT from dba_sqlset;
NAME OWNER CREATED STATEMENT_COUNT
------------------------------ ------------------------------ ------------ ---------------
sql_test SPA 18-APR-14 0
--------------执行从游标采集SQL
DECLARE
mycur DBMS_SQLTUNE.SQLSET_CURSOR;
BEGIN
OPEN mycur FOR
SELECT value(P)
FROM TABLE(dbms_sqltune.select_cursor_cache('parsing_schema_name in (''ORAADMIN'')',
NULL,
NULL,
NULL,
NULL,
,
NULL,
'ALL')) p;
dbms_sqltune.load_sqlset(sqlset_name => 'sql_test',
populate_cursor => mycur,
load_option => 'MERGE');
CLOSE mycur;
END;
/关于采集,可以参考文档:How to Load Queries into a SQL Tuning Set (STS) (文档 ID 1271343.1)
2.创建一个中转表,将SQL Tuning Set导入到中转表,导出中转表并传输到测试库;
这个步骤比较简单,但是需要注意的一点是:如果你的游标数量比较多的话,需要注意在转换过程中容易出现ORA-01555的错误。建议最好把undo retention设置大一些。
-------------不要使用sys用户创建stgtab表
DBMS_SQLTUNE.create_stgtab_sqlset(table_name => 'SQLSET_TAB',
schema_name => 'SPA',
tablespace_name => 'SYSAUX');
END;
/
-------------将优化集打包到stgtab表里面
BEGIN
DBMS_SQLTUNE.pack_stgtab_sqlset(sqlset_name => 'spa_test',
sqlset_owner => 'SPA',
staging_table_name => 'SQLSET_TAB',
staging_schema_owner => 'SPA');
END;
/转换成中转表之后,我们可以再做一次去除重复的操作。当然,你也可以根据module来删除一些不必要的游标。
delete from SPA.SQLSET_TAB a where rowid !=(select max(rowid) from SQLSET_TAB b where a.FORCE_MATCHING_SIGNATURE=b.FORCE_MATCHING_SIGNATURE and a.FORCE_MATCHING_SIGNATURE<>0);
delete from SPA.SQLSET_TAB where MODULE='PL/SQL Developer';3.导入中转表,并解压中转表的数据到SQL Tuning Set;
这个步骤我们需要把我们导出的中转表的数据迁移到测试平台,然后导入数据,并再一次转换成11g的SQL Tuning Set里面;
-------------导入数据到测试系统
export NLS_LANG=American_America.zhs16gbk
imp spa/spa fromuser=spa touser=spa file=/home/oracle/spa/SQLSET_TAB.dmp feedback=100
-------------创建sqlset
SQL> connect spa/spa
Connected.
SQL> exec DBMS_SQLTUNE.create_sqlset(sqlset_name => 'sql_test');
PL/SQL procedure successfully completed.
-------------unpack到sqlset
SQL> BEGIN
DBMS_SQLTUNE.unpack_stgtab_sqlset(sqlset_name => 'sql_test',
sqlset_owner => 'SPA',
replace => TRUE,
staging_table_name => 'SQLSET_TAB',
staging_schema_owner => 'SPA');
END;
/
PL/SQL procedure successfully completed.如果在你源端和目标端SQL SET的name,或者owner不同,需要你使用remap_stgtab_sqlset方法对SQL SET的name和owner进行转换。
exec dbms_sqltune.remap_stgtab_sqlset(old_sqlset_name =>'sql_test_aaa',old_sqlset_owner => 'aaa', new_sqlset_name => 'sql_test',new_sqlset_owner => 'SPA', staging_table_name => 'SQLSET_TAB',staging_schema_owner => 'SPA');导入导出SQLSET,可以参考文档:How to Move a SQL Tuning Set from One Database to Another (文档 ID 751068.1)
4.创建SPA任务,先生成10g的trail,然后在11g中再生成11g的trail;
这个步骤一定要注意一点,先检查测试库上面有没有dblink,如果有的话一定要删除,免得连接到其他库做一些不必要的动作,然后就是在11g中生成11g的trail的时间可能比较慢,最好写成脚本放在后台执行。
-------------新建SPA任务
var tname varchar2(30);
var sname varchar2(30);
exec :sname := 'sql_test';
exec :tname := 'SPA_TEST';
exec :tname := DBMS_SQLPA.CREATE_ANALYSIS_TASK(sqlset_name => :sname, task_name => :tname);
-------------生成10g的trail
begin
DBMS_SQLPA.EXECUTE_ANALYSIS_TASK(
task_name => 'SPA_TEST',
execution_type => 'CONVERT SQLSET',
execution_name => 'CONVERT_10G');
end;
/
-------------清空shared pool和buffer cache
alter system flush shared_pool;
alter system flush BUFFER_CACHE;
-------------生成11g的trail
begin
DBMS_SQLPA.EXECUTE_ANALYSIS_TASK(
task_name => 'SPA_TEST',
execution_type => 'TEST EXECUTE',
execution_name => 'EXEC_11G');
end;
/5.执行比较任务,再生成SPA报告;
我们可以从三个维度来进行对比,包括执行时间、CPU_TIME、Buffer_GET等.
-------------从elapsed_time来进行比较
begin
DBMS_SQLPA.EXECUTE_ANALYSIS_TASK(
task_name => 'SPA_TEST',
execution_type => 'COMPARE PERFORMANCE',
execution_name => 'Compare_elapsed_time',
execution_params => dbms_advisor.arglist('execution_name1', 'CONVERT_10G', 'execution_name2', 'EXEC_11G', 'comparison_metric', 'elapsed_time') );
end;
/
-------------从cpu_time来进行比较
begin
DBMS_SQLPA.EXECUTE_ANALYSIS_TASK(
task_name => 'SPA_TEST',
execution_type => 'COMPARE PERFORMANCE',
execution_name => 'Compare_CPU_time',
execution_params => dbms_advisor.arglist('execution_name1', 'CONVERT_10G', 'execution_name2', 'EXEC_11G', 'comparison_metric', 'CPU_TIME') );
end;
/
-------------从buffer_gets来进行比较
begin
DBMS_SQLPA.EXECUTE_ANALYSIS_TASK(
task_name => 'SPA_TEST',
execution_type => 'COMPARE PERFORMANCE',
execution_name => 'Compare_BUFFER_GETS_time',
execution_params => dbms_advisor.arglist('execution_name1', 'CONVERT_10G', 'execution_name2', 'EXEC_11G', 'comparison_metric', 'BUFFER_GETS') );
end;
-------------生成SPA报告
set trimspool on
set trim on
set pages 0
set long 999999999
set linesize 1000
spool spa_report_elapsed_time.html
SELECT dbms_sqlpa.report_analysis_task('SPA_TEST', 'HTML', 'ALL','ALL', top_sql=>300,execution_name=>'Compare_elapsed_time') FROM dual;
spool off;
spool spa_report_CPU_time.html
SELECT dbms_sqlpa.report_analysis_task('SPA_TEST', 'HTML', 'ALL','ALL', top_sql=>300,execution_name=>'Compare_CPU_time') FROM dual;
spool off;
spool spa_report_buffer_time.html
SELECT dbms_sqlpa.report_analysis_task('SPA_TEST','HTML','ALL','ALL',top_sql=>300,execution_name=>'Compare_BUFFER_GETS_time') FROM dual;
spool off;
spool spa_report_errors.html
SELECT dbms_sqlpa.report_analysis_task('SPA_TEST', 'HTML', 'errors','summary') FROM dual;
spool off;
spool spa_report_unsupport.html
SELECT dbms_sqlpa.report_analysis_task('SPA_TEST', 'HTML', 'unsupported','all') FROM dual;
spool off;
/6.分析性能退化的SQL语句;
生成完报告后,一共有5份,都需要我们逐一的去分析。我们从ELAPSED_TIME、CPU_TIME、Buffer_GET这三个报告中,我们可以查看到性能下降的SQL。有的SQL可能是CPU TIME有所升高,有的SQL可能是buffer gets有所升高,有的SQL可能这三方面都有所升高。这都是我们需要检查的。这些SQL的性能的退化,有可能执行计划发生了变化,有可能执行计划未变,要找出执行计划变化的原因,这需要我们对SQL优化和优化器、统计信息等有一个很深入的研究。
还有2份报告是errors和unsupport的语句,这类语句我们还是要看一下,一般情况就是有些是因为数据有差异,会出现invalid ROWID等情况。这些不用过多去关注,因为并不是所有的语句都能够精确分析,还有一些insert语句是unsupport的,我们只要分析大部分语句的问题即可。
参考文档:
How to Load Queries into a SQL Tuning Set (STS) (文档 ID 1271343.1)
How to Move a SQL Tuning Set from One Database to Another (文档 ID 751068.1)
Oracle? Database Real Application Testing User’s Guide 11g Release 2 (11.2)
11g SPA (sql Performance Analyze) 进行升级测试的更多相关文章
- 实战:ORACLE SQL Performance Analyzer
通过 SPA,您能够依据各种更改类型(如初始化參数更改.优化器统计刷新和数据库升级)播放特定的 SQL 或整个 SQL 负载,然后生成比較报告,帮助您评估它们的影响. 在 Oracle Databas ...
- Oracle 11g 中SQL性能优化新特性之SQL性能分析器(SQLPA)
Oracle11g中,真实应用测试选项(the Real Application Testing Option)提供了一个有用的特点,叫SQL性能分析器(SQL Performance Analyze ...
- SQL Performance Analyzer
SQL Performance Analyzer 系统发生变更,比如升级数据库.增加索引,都会可能导致sql的执行计划发生改变,从而影响sql的性能. 如果能预知系统变更会对sql的性能的影响,就可以 ...
- 30 分钟快快乐乐学 SQL Performance Tuning
转自:http://www.cnblogs.com/WizardWu/archive/2008/10/27/1320055.html 有些程序员在撰写数据库应用程序时,常专注于 OOP 及各种 fra ...
- Oracle 11g实时SQL监控 v$sql_monitor
Oracle 11g实时SQL监控: 前面提到,在Oracle Database 11g中,v$session视图增加了一些新的字段,这其中包括SQL_EXEC_START和SQL_EXEC_ID, ...
- [转]SQL SERVER整理索引碎片测试
SQL SERVER整理索引碎片测试 SQL SERVER整理索引的方法也就这么几种,而且老是自作聪明的加入智能判断很不爽,还是比DBMS_ADVISOR差远了: 1SQL SERVER 2000/2 ...
- SQL Server 2008 R2升级到SQL Server 2012 SP1
1.建议对生产环境对的数据库升级之前做好备份,以防不测. 2.从SQL Server 2008 R2 升级到SQL Server 2012 SP1,需要先安装SQL Server 2008 R2 的S ...
- (2.4)Mysql之SQL基础——下载与使用测试库
(2.4)SQL基础——下载与使用测试库 1.查看与下载测试数据库 2.查看安装向导视图 3.安装 [1]安装:解压后用 mysql 命令安装(记得加上set autocommit=1) [2]核验: ...
- A simple way to monitor SQL server SQL performance.
This is all begins from a mail. ... Dear sir: This is liulei. Thanks for your help about last PM for ...
随机推荐
- javascript中startswith和endsWidth 与 es6中的 startswith 和 endsWidth
在javascript中使用String.startswith和String.endsWidth 一.String.startswith 和 String.endsWidth 功能介绍 String. ...
- JavaScript 比较 和 逻辑运算符
比较运算符 比较运算符在逻辑语句中使用,以测定变量或值是否相等. === 绝对等于(值和类型均相等) != 不等于 !== 不绝对等于(值和类型有一个不相等,或两个都不相等) > 大于 & ...
- BUG -Failed to compile.
检查代码发现: 图片的路径写错了 改回正确路径页面可以正常显示
- Java中array、List、Set互相转换
数组转List String[] staffs = new String[]{"A", "B", "C"}; List staffsList ...
- CNN中,1X1卷积核到底有什么作用呢?
CNN中,1X1卷积核到底有什么作用呢? https://www.jianshu.com/p/ba51f8c6e348 Question: 从NIN 到Googlenet mrsa net 都是用了这 ...
- VR技术了解(作业)
增强现实技术 概念:将现实世界和虚拟世界无缝集成的新技术. 突出特点: 真实世界与虚拟的信息集成 实时交互 三维空间中增添定位虚拟物 应用 医疗领域:医生可以利用增强现实技术,轻易地进行手术部位的精确 ...
- android默认开启adb调试方法分析
用adb调试android时,每次接入usb线,都会提示一个确认打开usb调试功能的窗口,有时候,我们需要默认打开usb调试功能.或者无需弹出对话框,直接默认开启.这个我们需要分析adb的流程了. a ...
- Java:JavaBean和BeanUtils
本文内容: 什么是JavaBean JavaBean的使用 BeanUitls 利用DBUtils从数据库中自动加载数据到javabean对象中 首发日期:2018-07-21 什么是JavaBean ...
- html-edm(邮件营销)编写规则
最近写了一个edm邮件 以前没有接触过 使用的是很老的html页面编写规则 只能用table标签 在此记录一下edm编写的一些规则 个人参考的是这两个网址,转载一下 http://www.zco ...
- C# 如何使用 Elasticsearch (ES)
Elasticsearch简介 Elasticsearch (ES)是一个基于Apache Lucene(TM)的开源搜索引擎,无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进.性能最好 ...