HBase篇(3)-架构详解
【每日五分钟搞定大数据】系列,HBase第三篇

聊完场景和数据模型我们来说下HBase的架构,在网上找了张比较清晰的图,我觉得这张图能说明很多问题,那这一篇我们就重点来解析下这张图
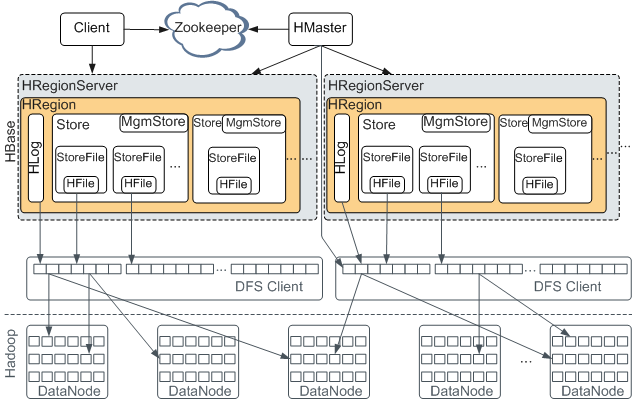
角色与职责
先介绍下上图中的几个角色和Ta们的职责:
1.HMaster
- 为Region server分配region;
- 负责Region server的负载均衡;
- 发现失效的Region server并重新分配其上的region;
- 处理schema更新请求
2.Client
Client包含访问HBase的接口,并维护cache(region的位置信息)来加快对HBase的访问
3.Zookeeper
在之前的Zookeeper篇讲过HBase和Zookeeper的联系,忘记地同学可以去翻一下。
- HMaster的HA
- regionserver状态信息
- 存root表(用于记录.META.表所在的regionServer,该表只会有一个regionServer)
- 存储HBase的schema和table元数据
- 发现失效的Region,借助HMaster分配region
4.HRegionSever
即一台服务器,拥有一个到多个HRegion
RegionServer
图里HRegionServer里面的内容很多,大家可能会看得有点懵,我们来详细说下这个HRegionServer里面的东西。
HRegionServer 包含 (1+)个 Region
一个 HRegionServer 包含一到多个Region,而Region就是一张HBase表按一定阈值横向切割的一部分。
Region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region;
Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上;
Region 包含 (1+)个 Store = columns family 列族个数
Region由一个或者多个Store组成,每个store保存一个columns family;
Store 是一个抽象的概念就是一个存储,它的个数和HDFS上的存储目录个数是一致的,而一个存储目录对应的就是一个columns family列族。
Store 包含(1)个 MemStore +(0+)个 StoreFile
Store 上面说了就是一个存储,他包含了一个内存的存储和0+个文件存储,一个Store的所有文件都存在一个目录下,这个目录下的所有文件对应的是一个列族。
注意:
- StoreFile是实际存储数据的。是HFile的轻量级包装。
- StoreFile达到阈值个数(4)会进行合并;
- 一个StoreFile达到阈值大小会进行分裂;
- 分裂后由hmaster分配到不同region起到负载均衡作用(若出现hot region可以手动拆分)
上面说得可能有点抽象,我们来看具体的数据:
我们来沿用下上一篇的那个表:
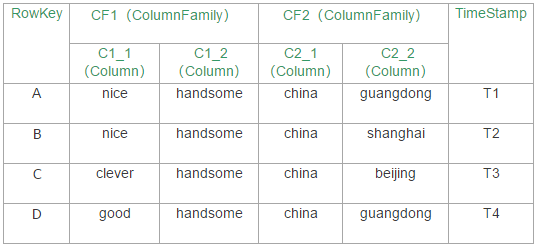
如表:
假设这张表有几万行,一行就代表一万行,那可能A和B可能是属于RegionA,C和D可能是属于RegionB,
RegionA和RegionB可能分布在不同的RegionServer上,
可见,RegionA有两个列族,CF1和CF2,
即它有两个Store,
即在HDFS上有两个目录分别用于存放CF1和CF2,
即CF1和CF2在内存里也分别各对应了一个MemStore
读写
这里先讲个大概,后面的文章我会每一步详细分析,比如region的分裂过程,StoreFile的合并过程,rowkey的定位详细流程等等,欢迎持续关注。
Region定位流程:
- Zookeeper:记录了-ROOT-表的位置。
- -ROOT-:记录.META.表所在的region列表,该表只会有一个Region;
.META.:根据给定的key找到RegionServer。.META.记录所有的用户空间region列表,以及RegionServer的服务器地址。
写流程
- 向zookeeper发起请求,从ROOT表中获得META所在的region,再根据table,namespace,rowkey,去meta表中找到目标数据对应的region信息以及regionserver
把数据分别写到HLog和MemStore上一份
MemStore达到一个阈值后则把数据刷成一个StoreFile文件。若MemStore中的数据有丢失,则可以总HLog上恢复
当多个StoreFile文件达到一定的大小后,会触发Compact合并操作,合并为一个StoreFile,这里同时进行版本的合并和数据删除。
当Compact后,逐步形成越来越大的StoreFIle后,会触发Split操作,把当前的StoreFile分成两个,这里相当于把一个大的region分割成两个region读流程
- 从zookeeper获得root表所在region位置
- 根据table,namespace,rowkey去root表中获得meta表所在region位置
- 根据table,namespace,rowkey去meta表中获得这条记录所在regionserver
- 首先检查请求的数据是否在Memstore,写缓存未命中的话再到读缓存(blockCache)中查找,读缓存还未命中才会到HFile文件中查找,最终返回merged的一个结果给用户
client端会对数据块缓存
数据flush过程
- 当memstore数据达到阈值(默认是64M),将数据刷到硬盘,将内存中的数据删除同时删除Hlog中的历史数据。
- 并将数据存储到hdfs中。
在hlog中做标记点。
数据合并过程
- 当数据块达到4块,hmaster将数据块加载到本地,进行合并
- 当合并的数据超过256M,进行拆分,将拆分后的region分配给不同的hregionserver管理
- 当hregionser宕机后,将hregionserver上的hlog拆分,然后分配给不同的hregionserver加载,修改.META.
注意:hlog会同步到hdfs

HBase篇(3)-架构详解的更多相关文章
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- WeChatAPI 开源系统架构详解
WeChatAPI 开源系统架构详解 如果使用WeChatAPI,它扮演着什么样的角色? 从图中我们可以看到主要分为3个部分: 1.业务系统 2.WeChatAPI: WeChatWebAPI,主要是 ...
- RESTful 架构详解
RESTful 架构详解 分类 编程技术 1. 什么是REST REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移. 它首次 ...
- 【菜鸟】RESTful 架构详解
RESTful 架构详解 分类 编程技术 1. 什么是REST REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移. 它首次 ...
- 入木三分学网络第一篇--VRRP协议详解第一篇(转)
因为keepalived使用了VRRP协议,所有有必要熟悉一下. 虚拟路由冗余协议(Virtual Router Redundancy Protocol,简称VRRP)是解决局域网中配置静态网关时,静 ...
- Hyperledger Fabric架构详解
区块链开源实现HYPERLEDGER FABRIC架构详解 区块链开源实现HYPERLEDGER FABRIC架构详解 2018年5月26日 陶辉 Comments 10 Comments hyper ...
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- NopCommerce源码架构详解--初识高性能的开源商城系统cms
很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从中学习很多企业系统.软件开发的规范和一些新的技术.技巧,可以快速地提高我们 ...
随机推荐
- 转载:如何在Ubuntu 18.04上使用UFW设置防火墙
https://blog.csdn.net/u013068789/article/details/82051943 介绍 UFW或Uncomplicated Firewall是iptables一个接口 ...
- Android getprop 读取的属性哪里来的?
Android getprop 和 setprop 可以对系统属性进行读取和设置. 通过串口执行以下 geyprop 打印出来的属性让你一目了然. 属性出来了,但是在哪里设置的呢,这里有两个 ...
- split 分割 字符串(分隔符如:* ^ : | , .)
[1]单个符号作为分隔符 String address="上海|上海市|闵行区|吴中路"; String[] splitAddress=address.split("\\ ...
- SQL 中事务的分类
先讲下事务执行流程: BEGIN和COMMIT PRINT @@TRANCOUNT --@@TRANCOUNT统计事务数量 BEGIN TRAN PRINT @@TRANCOUNT BEGIN TRA ...
- Exception in thread "main" java.lang.RuntimeException: Hive metastore database is not initialized. Please use schematool (e.g. ./schematool -initSchema -dbType ...) to create the schema. If needed, do
继上一篇Hive: Exception in thread "main" java.lang.RuntimeException: Hive metastore database i ...
- [20181007]12cR2 Using SQL Patch 2.txt
[20181007]12cR2 Using SQL Patch 2.txt --//12cR2 已经把sql打补丁集成进入dbms_sqldiag,不是11g的 DBMS_SQLDIAG_INTERN ...
- Linux CFS调度器之虚拟时钟vruntime与调度延迟--Linux进程的管理与调度(二十六)
1 虚拟运行时间(今日内容提醒) 1.1 虚拟运行时间的引入 CFS为了实现公平,必须惩罚当前正在运行的进程,以使那些正在等待的进程下次被调度. 具体实现时,CFS通过每个进程的虚拟运行时间(vrun ...
- 开发nginx启动脚本及开机自启管理(case)
往往我们在工作中需要自行写一些脚本来管理服务,一旦服务异常或宕机等问题,脚本无法自行管理,当然我们可以写定时任务或将需要管理的脚本加入自启等方法来避免这种尴尬的事情,case适用与写启动脚本,下面给大 ...
- DbContext 和 ObjectContext两者的区别
ObjectContext是一种模型优先的开发模式,DbContext是代码优先的开发模式.这是两者最根本的区别. 同时两者之间可以相互转换: 下面给出转换的例子 1.DbContext转为Objec ...
- MySQL 数据库初识
一.数据库概述 (详情参考:https://www.cnblogs.com/clschao/articles/9907529.html) 1.概念:存储数据,共享数据 数据库,简而言之可视为电子化的文 ...