Elasticsearch —— bulk批量导入数据
在使用Elasticsearch的时候,一定会遇到这种场景——希望批量的导入数据,而不是一条一条的手动导入。那么此时,就一定会需要bulk命令!
更多内容参考我整理的Elk教程
bulk批量导入
批量导入可以合并多个操作,比如index,delete,update,create等等。也可以帮助从一个索引导入到另一个索引。
语法大致如下;
action_and_meta_data\n
optional_source\n
action_and_meta_data\n
optional_source\n
....
action_and_meta_data\n
optional_source\n
需要注意的是,每一条数据都由两行构成(delete除外),其他的命令比如index和create都是由元信息行和数据行组成,update比较特殊它的数据行可能是doc也可能是upsert或者script,如果不了解的朋友可以参考前面的update的翻译。
注意,每一行都是通过\n回车符来判断结束,因此如果你自己定义了json,千万不要使用回车符。不然_bulk命令会报错的!
一个小例子
比如我们现在有这样一个文件,data.json:
{ "index" : { "_index" : "test", "_type" : "type1", "_id" : "1" } }
{ "field1" : "value1" }
它的第一行定义了_index,_type,_id等信息;第二行定义了字段的信息。
然后执行命令:
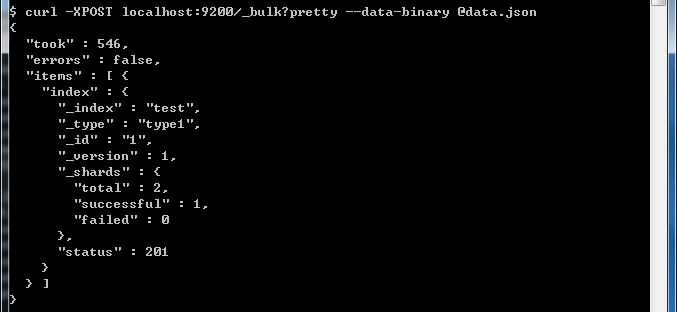
curl -XPOST localhost:9200/_bulk --data-binary @data.json
就可以看到已经导入进去数据了。
对于其他的index,delete,create,update等操作也可以参考下面的格式:
{ "index" : { "_index" : "test", "_type" : "type1", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_type" : "type1", "_id" : "2" } }
{ "create" : { "_index" : "test", "_type" : "type1", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_type" : "type1", "_index" : "index1"} }
{ "doc" : {"field2" : "value2"} }
在Url中设置默认的index和type
如果在路径中设置了index或者type,那么在JSON中就不需要设置了。如果在JSON中设置,会覆盖掉路径中的配置。
比如上面的例子中,文件中定义了索引为test,类型为type1;而我们在路径中定义了默认的选项,索引为test333,类型为type333。执行命令后,发现文件中的配置会覆盖掉路径中的配置。这样也提供了统一的默认配置以及个性化的特殊配置的需求。

其他
由于bulk是一次性提交很多的命令,它会把这些数据都发送到一个节点,然后这个节点解析元数据(index或者type或者id之类的),然后分发给其他的节点的分片,进行操作。
由于很多命令执行后,统一的返回结果,因此数据量可能会比较大。这个时候如果使用的是chunk编码的方式,分段进行传输,可能会造成一定的延迟。因此还是对条件在客户端进行一定的缓冲,虽然bulk提供了批处理的方法,但是也不能给太大的压力!
最后要说一点的是,Bulk中的操作执行成功与否是不影响其他的操作的。而且也没有具体的参数统计,一次bulk操作,有多少成功多少失败。
扩展:在Logstash中,传输的机制其实就是bulk,只是他使用了Buffer,如果是服务器造成的访问延迟可能会采取重传,其他的失败就只丢弃了....
Elasticsearch —— bulk批量导入数据的更多相关文章
- elasticsearch bulk批量导入 大文件拆分
命令如下: curl -s -XPOST http://localhost:9200/_bulk --data-binary @data.json 如果上传的data.json文件较大,可以将其切分为 ...
- csv文件批量导入数据到sqlite。
csv文件批量导入数据到sqlite. 代码: f = web.input(bs_switch = {}) # bs_switch 为from表单file字段的namedata =[i.split( ...
- 使用python向Redis批量导入数据
1.使用pipeline进行批量导入数据.包含先使用rpush插入数据,然后使用expire改动过期时间 class Redis_Handler(Handler): def connect(self) ...
- Cassandra使用pycassa批量导入数据
本周接手了一个Cassandra系统的维护工作,有一项是需要将应用方的数据导入我们维护的Cassandra集群,并且为应用方提供HTTP的方式访问服务.这是我第一次接触KV系统,原来只是走马观花似的看 ...
- Redis批量导入数据的方法
有时候,我们需要给redis库中插入大量的数据,如做性能测试前的准备数据.遇到这种情况时,偶尔可能也会懵逼一下,这里就给大家介绍一个批量导入数据的方法. 先准备一个redis protocol的文件( ...
- 项目总结04:SQL批量导入数据:将具有多表关联的Excel数据,通过sql语句脚本的形式,导入到数据库
将具有多表关联的Excel数据,通过sql语句脚本的形式,导入到数据库 写在前面:本文用的语言是java:数据库是MySql: 需求:在实际项目中,经常会被客户要求,做批量导入数据:一般的简单的单表数 ...
- 批量导入数据到mssql数据库的
概述 批量导入数据到数据库中,我们有好几种方式. 从一个数据表里生成数据脚本,到另一个数据库里执行脚本 从EXCEL里导入数据 上面两种方式,导入的数据都会生成大量的日志.如果批量导入5W条数据到数据 ...
- asp.net线程批量导入数据时通过ajax获取执行状态
最近因为工作中遇到一个需求,需要做了一个批量导入功能,但长时间运行没个反馈状态,很容易让人看了心急,产生各种臆想!为了解决心里障碍,写了这么个功能. 通过线程执行导入,并把正在执行的状态存入sessi ...
- ADO.NET 对数据操作 以及如何通过C# 事务批量导入数据
ADO.NET 对数据操作 以及如何通过C# 事务批量导入数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ...
随机推荐
- ABP文档 - Javascript Api - AJAX
本节内容: AJAX操作相关问题 ABP的方式 AJAX 返回信息 处理错误 HTTP 状态码 WrapResult和DontWrapResult特性 Asp.net Mvc 控制器 Asp.net ...
- ASP.NET Core框架揭秘(持续更新中…)
之前写了一系列关于.NET Core/ASP.NET Core的文章,但是大都是针对RC版本.到了正式的RTM,很多地方都发生了改变,所以我会将之前发布的文章针对正式版本的.NET Core 1.0进 ...
- 使用SecureCRT连接虚拟机(ubuntu)配置记录
这种配置方法,可以非常方便的操作虚拟机里的Linux系统,且让VMware在后台运行,因为有时候我直接在虚拟机里操作会稍微卡顿,或者切换速度不理想,使用该方法亲测本机效果确实ok,特此记录. Secu ...
- JavaScript事件代理和委托(Delegation)
JavaScript事件代理 首先介绍一下JavaScript的事件代理.事件代理在JS世界中一个非常有用也很有趣的功能.当我们需要对很多元素添加事件的时候,可以通过将事件添加到它们的父节点而将事件委 ...
- jetBrain系列软件
请尽量支持正版软件!https://www.jetbrains.com/ 本文仅供参考 以下提供一种方法可以无限期体验JetBrain2016系列软件. 1.下载JetbrainsCrack-2.5. ...
- mono for android 用ISharedPreferences 进行状态保持 会话保持 应用程序首选项保存
由于项目需要 要保持用户登录状态 要进行状态保持 用途就好像asp.net的session一样 登录的时候进行保存 ISharedPreferences shared = GetSharedPrefe ...
- C#执行异步操作的几种方式比较和总结
C#执行异步操作的几种方式比较和总结 0x00 引言 之前写程序的时候在遇到一些比较花时间的操作例如HTTP请求时,总是会new一个Thread处理.对XxxxxAsync()之类的方法也没去了解过, ...
- 【初码干货】在Window Server 2016中使用Web Deploy方式发布.NET Web应用的重新梳理
在学习和工作的过程中,发现很多同事.朋友,在做.NET Web应用发布的时候,依然在走 生成-复制到服务器 这样的方式,稍微高级一点的,就是先发布到本地,再上传到服务器 这种方式不仅效率低下,而且不易 ...
- Angular2学习笔记——Observable
Reactive Extensions for Javascript 诞生于几年前,随着angular2正式版的发布,它将会被更多开发者所认知.RxJs提供的核心是Observable对象,它是一个使 ...
- Mac 词典工具推荐:Youdao Alfred Workflow(可同步单词本)
想必大家都有用过 Mac 下常见的几款词典工具: 特性 系统 Dictionary 欧路词典 Mac 版 有道词典 Mac 版 在线搜索 ✗ ✔ ✔ 屏幕取词 ☆☆☆ ★★☆ ★☆☆ 划词搜索 ★★★ ...