使用Talend Open Studio将数据分步从oracle导入到hive中
先使用Tos建立模型,将Oracle中的数据导入到本地:
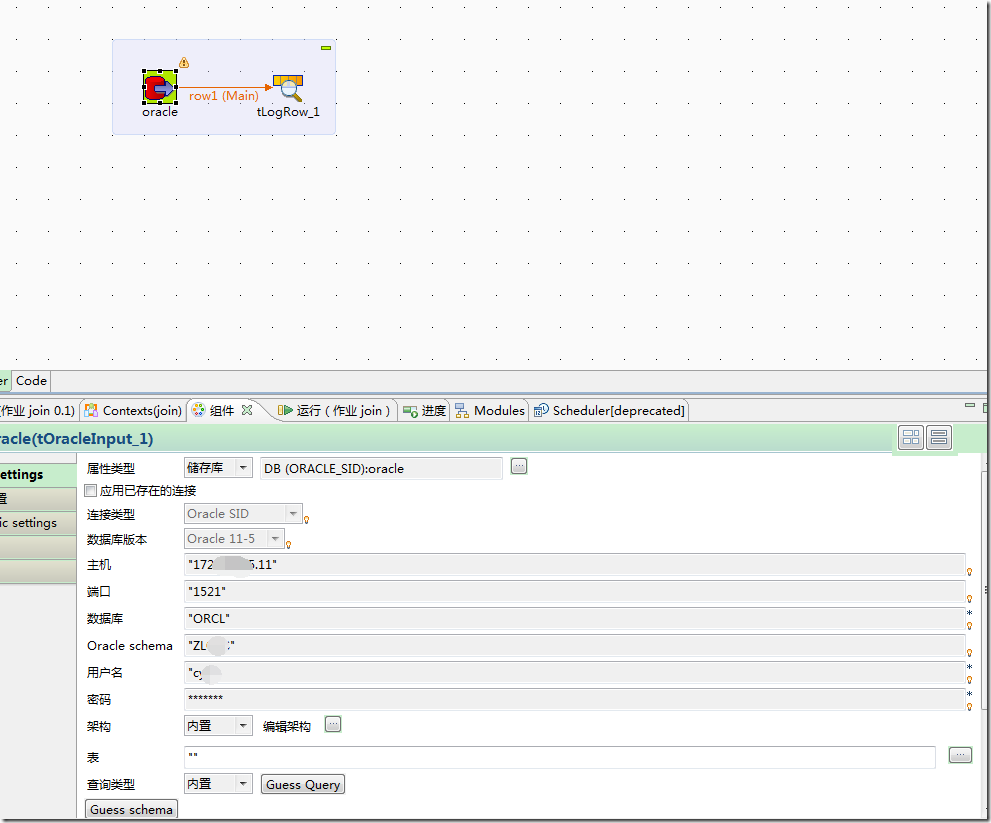
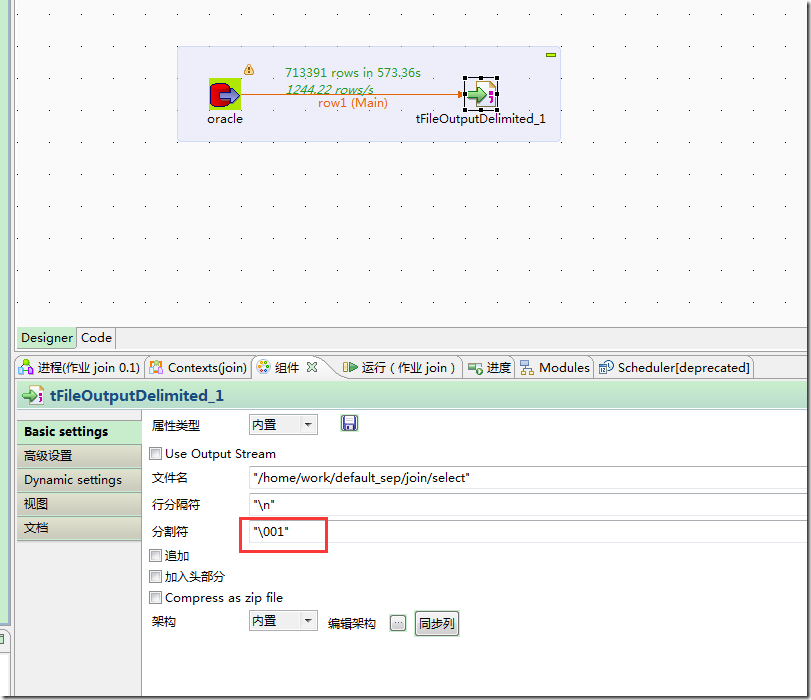
build job后,形成独立可以运行的程序:
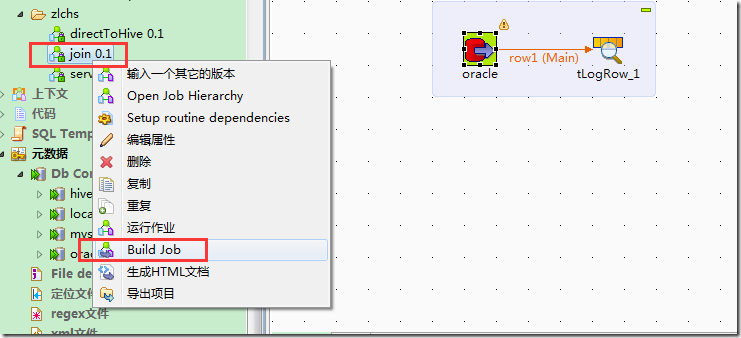
将生成的zip文件,上传到hadoop集群上,有hive环境的机器上:
[hive@h1 work]$ ls
file.zip jobInfo.properties join lib
[hive@h1 work]$ cd join/
[hive@h1 join]$ ls
bigdatademo items join_0_1.jar join_run.bat join_run.sh src user_activity2
[hive@h1 join]$ pwd
/home/work/join
[hive@h1 join]$ ls
bigdatademo items join_0_1.jar join_run.bat join_run.sh src user_activity2
[hive@h1 join]$ pwd
/home/work/join
[hive@h1 join]$ ./join_run.sh > user_activity2 2>&1 &
这样就得到了SQL语句执行的结果,存放在user_activity2中。
hive建表语句:
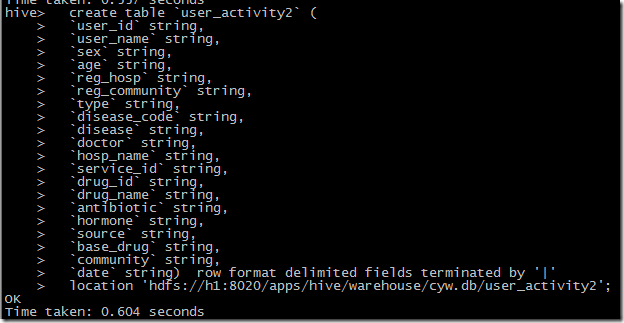
hive> show create table user_activity2;
OK
CREATE TABLE `user_activity2`(
`user_id` string,
`user_name` string,
`sex` string,
`age` string,
`reg_hosp` string,
`reg_community` string,
`type` string,
`disease_code` string,
`disease` string,
`doctor` string,
`hosp_name` string,
`service_id` string,
`drug_id` string,
`drug_name` string,
`antibiotic` string,
`hormone` string,
`source` string,
`base_drug` string,
`community` string,
`date` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://h1:8020/apps/hive/warehouse/cyw.db/user_activity2'
TBLPROPERTIES (
'transient_lastDdlTime'='1435547544')
Time taken: 0.288 seconds, Fetched: 31 row(s)
将数据导入到hive表中:load data local inpath './user_activity2' into table user_activity2;
hive> show tables;
OK
Time taken: 0.794 seconds
hive> use cyw;
OK
Time taken: 0.256 seconds
hive> show tables;
OK
user_activity
user_activity2
Time taken: 0.136 seconds, Fetched: 2 row(s)
hive> load data local inpath './user_activity2' into table user_activity2;
Loading data to table cyw.user_activity2
Table cyw.user_activity2 stats: [numFiles=1, totalSize=216927483]
OK
Time taken: 10.898 seconds
hive> select * from user_activity2;
OK
F805418B-335F-4CA3-A209-7C9655148146 余泽英 2 47 成都高新区合作社区卫生服务中心 合作 1 急性支气管炎 谭万龙 成都高新区合作社区卫生服务中心 1E972231-C65A-4CE3-9233-8EA1B18058DE 灭菌注射用水 d875aacf-4723-4777-91ec-12d63732b58f 0 0 其他 合作 2014-02-27
F805418B-335F-4CA3-A209-7C9655148146 余泽英 2 47 成都高新区合作社区卫生服务中心 合作
查询语句:
select a.个人id,
b.姓名,
b.性别,
round((sysdate - b.出生日期) / 365) as fage,
b.建档单位,
replace(replace(replace(b.建档单位, '高新区'), '社区卫生服务中心'),
'成都') 建档社区,
1 as ftype,
a.问题编码,
a.问题名称,
a.处理医生,
c.机构名,
a.服务记录id,
f.名称,
f.id 药品ID ,
f.抗生素,
f.激素类药,
case when f.药品来源 is null then '其他' else f.药品来源 end 药品来源,
f.基药分类,
replace(replace(replace(c.机构名, '高新区'), '社区卫生服务中心'),'成都') 诊疗社区,
to_char(a.发现日期,
'yyyy-mm-dd') 诊疗日期
from ZLCHS.个人问题列表 a,
ZLCHS.个人信息 b,
ZLCHS.服务活动记录 c,
(select d.事件id, e.名称, e.id, h.药品来源, h.基药分类, g.抗生素, g.激素类药
from ZLCHS.个人费用记录 d, ZLCHS.收费项目目录 e, ZLCHS.药品规格 h, ZLCHS.药品特性 g
where d.收费项目id = e.id
and d.收据费目 in ('西药费', '中草药费', '中成药费')
and h.药品id(+) = e.id
and h.药名id = g.药名id) f
where a.个人id = b.id(+)
and a.服务记录id = c.id(+)
and a.服务记录id = f.事件id(+)
加入分区字段:
CREATE TABLE `user_activity`(
`user_id` string,
`user_name` string,
`sex` string,
`age` string,
`reg_hosp` string,
`reg_community` string,
`type` string,
`disease_code` string,
`disease` string,
`doctor` string,
`hosp_name` string,
`service_id` string,
`drug_id` string,
`drug_name` string,
`antibiotic` string,
`hormone` string,
`source` string,
`base_drug` string,
`community` string,
`date` string)
PARTITIONED BY (
`dt` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://h1:8020/apps/hive/warehouse/cyw.db/user_activity'
TBLPROPERTIES (
'transient_lastDdlTime'='1435559269')
Time taken: 0.252 seconds, Fetched: 33 row(s)
默认的字段分隔符为ascii码的控制符\001,建表的时候用fields terminated by '\001',如果要测试的话,造数据在vi 打开文件里面,用ctrl+v然后再ctrl+a可以输入这个控制符\001。按顺序,\002的输入方式为ctrl+v,ctrl+b。以此类推。
使用Talend Open Studio将数据分步从oracle导入到hive中的更多相关文章
- Talend 将Oracle中数据导入到hive中,根据系统时间设置hive分区字段
首先,概览下任务图: 流程是,先用tHDFSDelete将hdfs上的文件删除掉,然后将oracle中的机构表中的数据导入到HDFS中:建立hive连接->hive建表->tJava获取系 ...
- 使用Sqoop,最终导入到hive中的数据和原数据库中数据不一致解决办法
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL , ...
- 把HDFS上的数据导入到Hive中
1. 首先下载测试数据,数据也可以创建 http://files.grouplens.org/datasets/movielens/ml-latest-small.zip 2. 数据类型与字段名称 m ...
- 使用sqoop将mysql数据导入到hive中
首先准备工具环境:hadoop2.7+mysql5.7+sqoop1.4+hive3.1 准备一张数据库表: 接下来就可以操作了... 一.将MySQL数据导入到hdfs 首先我测试将zhaopin表 ...
- 基于ASP.NET几十万数据几秒钟就可以导入到数据库中
/// <summary> /// 一.构建模拟数据存放于DataTable /// </summary> /// <returns>DataTable</r ...
- 如何将数据导入到hive中
可以通过多种方式将数据导入hive表 1.通过外部表导入 用户在hive上建external表,建表的同时指定hdfs路径,在数据拷贝到指定hdfs路径的同时,也同时完成数据插入external表. ...
- sqlserver 中数据导入到mysql中的方法以及注意事项
数据导入从sql server 到mysql (将数据以文本格式从sqlserver中导出,注意编码格式,再将文本文件导入mysql中): 1.若从slqserver中导出的表中不包含中文采用: bc ...
- hdfs数据到hive中,以及hdfs数据隐身理解
hdfs数据到hive中: 假设hdfs中已存在好了数据,路径是hdfs:/localhost:9000/user/user_w/hive_g2park/user_center_enterprise_ ...
- oracle数据库中导入Excel表格中的数据
1.点击[工具]-->[ODBC 导入器],如图: 2.在导入器里选择第一个[来自ODBC的数据],用户名/系统DSN-->填写[Excel Files],输入用户名和密码,点击 [连接] ...
随机推荐
- infobright系列二:数据迁移
安装之后把之前infobright的数据迁移到新安装的infobright上. 1:挺掉相关的服务 2:scp 把旧数据拷到新安装的infobright上 3:修改/etc/my-ib.cnf的数据目 ...
- 数组的翻转(非reverse())
方法一: var arr = [1,2,3,4]; var arr2 = []; while(arr.length) { var num = arr.pop(); //删除数组最后一个元素并返回被删除 ...
- Jenkins 关闭和重启
关闭jenkins服务:http://localhost:8080/exit 将上面的exit改为restart后就可以重新启动jenkins服务器.http://localhost:8080/res ...
- CSDN开源夏令营 基于Compiz的switcher插件设计与实现之编译compiz源代码
在開始介绍之前先吐个嘈:上周我们暑期ACM集训開始了.平均下来基本上是一天一赛.有时还不止.又是多校联赛,又是CodeForces,又是TopCoder.又是BestCoder,又是AcDream.还 ...
- Java千百问_05面向对象(005)_接口和抽象类有什么差别
点击进入_很多其它_Java千百问 1.接口和抽象类有什么差别 在Java语言中.抽象类abstract class和接口interface是抽象定义的两种机制. 正是因为这两种机制的存在,才赋予了J ...
- 【Linux】shell数组
一.概念 shell数组就是一个元素集合,它把有限个元素用一个名字来命名,然后用编号对他们分区.这个名字称为数组名,用于区分不同内容的编号称为数组的下标. 二.shell数组的定义与增删改查 1.sh ...
- 【Java】监控远程服务器JVM
今天在用JMeter进行测试的时候,发现线程并发量到50的时候会导致阻塞情况,于是需要监控远程JVM,那么如何监控远程JVM呢? 首先,找到启动计量引擎的sh文件,例如我目前的计量引擎启停文件为str ...
- mysql可视化工具
比较mysql manager lite 和phpmyadmin: 1.phpmyadmin有中文界面, 可以快速入门,但友好性远没有SQL Manager Lite强大 2.SQL Manager ...
- 完完全全彻底删除VMware_Workstation
vmware-workstation,卸载不干净.bat脚本自动处理dll.注册的表垃圾 Download https://pan.baidu.com/s/1dmrOs3rkR8cX5b0vTUOxH ...
- jeecg平台testDatagrid
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...