FP-growth算法发现频繁项集(二)——发现频繁项集
上篇介绍了如何构建FP树,FP树的每条路径都满足最小支持度,我们需要做的是在一条路径上寻找到更多的关联关系。
抽取条件模式基
首先从FP树头指针表中的单个频繁元素项开始。对于每一个元素项,获得其对应的条件模式基(conditional pattern base),单个元素项的条件模式基也就是元素项的关键字。条件模式基是以所查找元素项为结尾的路径集合。每一条路径其实都是一条前辍路径(perfix path)。简而言之,一条前缀路径是介于所査找元素项与树根节点之间的所有内容。
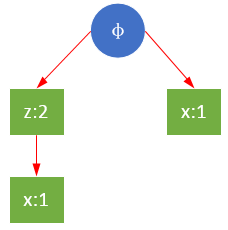
下图是以{s:2}或{r:1}为元素项的前缀路径:

{s}的条件模式基,即前缀路径集合共有两个:{{z,x,y,t}, {x}};{r}的条件模式基共三个:{{z}, {z,x,y,t}, {x,s}}。
寻找条件模式基的过程实际上是从FP树的每个叶子节点回溯到根节点的过程。我们可以通过头指针列表headTable开始,通过指针的连接快速访问到所有根节点。下表是上图FP树的所有条件模式基:

创建条件FP树
为了发现更多的频繁项集,对于每一个频繁项,都要创建一棵条件FP树。可以使用刚才发现的条件模式基作为输入数据,并通过相同的建树代码来构建这些树。然后,递归地发现频繁项、发现条件模式基,以及发现另外的条件树。
以频繁项r为例,构建关于r的条件FP树。r的三个前缀路径分别是{z},{z,x,y,t},{x,s},设最小支持度minSupport=2,则y,t,s被过滤掉,剩下{z},{z,x},{x}。y,s,t虽然是条件模式基的一部分,但是并不属于条件FP树,即对于r来说,它们不是频繁的。如下图所示,y→t→r和s→r的全局支持度都为1,所以y,t,s对于r的条件树来说是不频繁的。

过滤后的r条件树如下:
重复上面步骤,r的条件模式基是{z,x},{x},已经没有能够满足最小支持度的路径, 所以r的条件树仅有一个。需要注意的是,虽然{z,x},{x}中共存在两个x,但{z,x}中,z是x的父节点,在构造条件FP树时不能直接将父节点移除,仅能从子节点开始逐级移除。
代码如下:
def ascendTree(leafNode, prefixPath):
if leafNode.parent != None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath) def findPrefixPath(basePat, headTable):
condPats = {}
treeNode = headTable[basePat][1]
while treeNode != None:
prefixPath = []
ascendTree(treeNode, prefixPath)
if len(prefixPath) > 1:
condPats[frozenset(prefixPath[1:])] = treeNode.count
treeNode = treeNode.nodeLink
return condPats def mineTree(inTree, headerTable, minSup=1, preFix=set([]), freqItemList=[]):
# order by minSup asc, value asc
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: (p[1][0],p[0]))]
for basePat in bigL:
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
freqItemList.append(newFreqSet)
# 通过条件模式基找到的频繁项集
condPattBases = findPrefixPath(basePat, headerTable)
myCondTree, myHead = createTree(condPattBases, minSup)
if myHead != None:
print('condPattBases: ', basePat, condPattBases)
myCondTree.disp()
print('*' * 30) mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList) simpDat = loadSimpDat()
dictDat = createInitSet(simpDat)
myFPTree,myheader = createTree(dictDat, 3)
myFPTree.disp()
condPats = findPrefixPath('z', myheader)
print('z', condPats)
condPats = findPrefixPath('x', myheader)
print('x', condPats)
condPats = findPrefixPath('y', myheader)
print('y', condPats)
condPats = findPrefixPath('t', myheader)
print('t', condPats)
condPats = findPrefixPath('s', myheader)
print('s', condPats)
condPats = findPrefixPath('r', myheader)
print('r', condPats) mineTree(myFPTree, myheader, 2)
控制台信息:
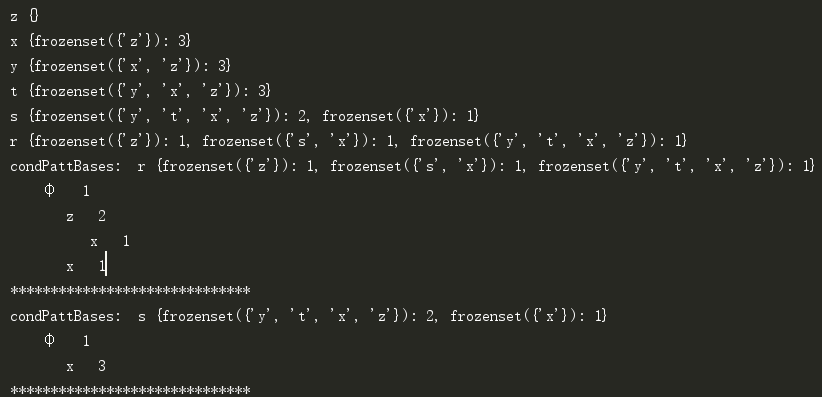
本例可以发现两个频繁项集{z,x}和{x}。
取得频繁项集后,可以根据置信度发现关联规则,这一步较为简单,可参考上篇的相关内容,不在赘述。
出处:微信公众号 "我是8位的"
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注作者公众号“我是8位的”

FP-growth算法发现频繁项集(二)——发现频繁项集的更多相关文章
- Frequent Pattern 挖掘之二(FP Growth算法)
Frequent Pattern 挖掘之二(FP Growth算法) FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断 ...
- Frequent Pattern 挖掘之二(FP Growth算法)(转)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- FP—Growth算法
FP_growth算法是韩家炜老师在2000年提出的关联分析算法,该算法和Apriori算法最大的不同有两点: 第一,不产生候选集,第二,只需要两次遍历数据库,大大提高了效率,用31646条测试记录, ...
- Frequent Pattern (FP Growth算法)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达 到这样的效果,它采用了一种简洁的数据 ...
- 关联规则算法之FP growth算法
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- 机器学习(十五)— Apriori算法、FP Growth算法
1.Apriori算法 Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策. Apriori算法采用了迭代的方法,先搜 ...
- FP Tree算法原理总结
在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题,FP Tree算法(也称F ...
- FP Tree算法原理总结(转载)
FP Tree算法原理总结 在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题 ...
- FP - growth 发现频繁项集
FP - growth是一种比Apriori更高效的发现频繁项集的方法.FP是frequent pattern的简称,即常在一块儿出现的元素项的集合的模型.通过将数据集存储在一个特定的FP树上,然后发 ...
- 算法笔记_118:算法集训之结果填空题集二(Java)
目录 1 欧拉与鸡蛋 2 巧排扑克牌 3 排座位 4 黄金队列 5 汉诺塔计数 6 猜生日 7 棋盘上的麦子 8 国庆星期日 9 找素数 10 填写算式 11 取字母组成串 1 欧拉与鸡蛋 大数 ...
随机推荐
- UVA-10020 Minimal coverage(贪心)
题目大意:在x轴上,给一些区间,求出能把[0,m]完全覆盖的最少区间个数及该情形下的各个区间. 题目分析:简单的区间覆盖问题.可以按这样一种策略进行下去:在所有区间起点.长度有序的前提下,对于当前起点 ...
- 正向代理到指定泛域名的nginx配置
resolver 8.8.8.8; #必须配置!!!不然无法代理 server { listen default_server; listen [::]: default_server; server ...
- arc路径例子-磊哥
<!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml"><head> & ...
- gvim配置文件
vimrc配置 source $VIMRUNTIME/vimrc_example.vim source $VIMRUNTIME/mswin.vim behave mswin "设置文件的 ...
- ioS UI-导航控制器(NavigationController)
#import "AppDelegate.h" #import "ViewController.h" @interface AppDelegate () @en ...
- redis中的"HashMap"
redis是一个存储键值对的内存数据库,其存储键值的方式和java中的HashMap相似. 表征redis数据库的结构体是redisDb (在server.h文件中),redis服务器默认有16个数据 ...
- logistic 回归与线性回归的比较
可以参考如下文章 https://blog.csdn.net/sinat_37965706/article/details/69204397 第一节中说了,logistic 回归和线性回归的区别是:线 ...
- learning uboot how to enable watchdog in qca4531 cpu
find cpu datasheet , watchdog relate registers: 0x18060008 watchdong timer control 0x1806000c watchd ...
- SQL Server 调优系列进阶篇 - 如何重建数据库索引
随着数据的数据量的急剧增加,数据库的性能也会明显的有些缓慢这个时候你可以考虑下重建索引或是重新组织索引了. DBCC SHOWCONTIG('表名') 可以查看当前表的索引碎情况. 重建索引 方法一: ...
- Vue 就地复用策略注意事项
---template部分 div el-popover(ref="message", placement="top-start", title="标 ...