FP-growth算法发现频繁项集(二)——发现频繁项集
上篇介绍了如何构建FP树,FP树的每条路径都满足最小支持度,我们需要做的是在一条路径上寻找到更多的关联关系。
抽取条件模式基
首先从FP树头指针表中的单个频繁元素项开始。对于每一个元素项,获得其对应的条件模式基(conditional pattern base),单个元素项的条件模式基也就是元素项的关键字。条件模式基是以所查找元素项为结尾的路径集合。每一条路径其实都是一条前辍路径(perfix path)。简而言之,一条前缀路径是介于所査找元素项与树根节点之间的所有内容。
下图是以{s:2}或{r:1}为元素项的前缀路径:

{s}的条件模式基,即前缀路径集合共有两个:{{z,x,y,t}, {x}};{r}的条件模式基共三个:{{z}, {z,x,y,t}, {x,s}}。
寻找条件模式基的过程实际上是从FP树的每个叶子节点回溯到根节点的过程。我们可以通过头指针列表headTable开始,通过指针的连接快速访问到所有根节点。下表是上图FP树的所有条件模式基:

创建条件FP树
为了发现更多的频繁项集,对于每一个频繁项,都要创建一棵条件FP树。可以使用刚才发现的条件模式基作为输入数据,并通过相同的建树代码来构建这些树。然后,递归地发现频繁项、发现条件模式基,以及发现另外的条件树。
以频繁项r为例,构建关于r的条件FP树。r的三个前缀路径分别是{z},{z,x,y,t},{x,s},设最小支持度minSupport=2,则y,t,s被过滤掉,剩下{z},{z,x},{x}。y,s,t虽然是条件模式基的一部分,但是并不属于条件FP树,即对于r来说,它们不是频繁的。如下图所示,y→t→r和s→r的全局支持度都为1,所以y,t,s对于r的条件树来说是不频繁的。

过滤后的r条件树如下:
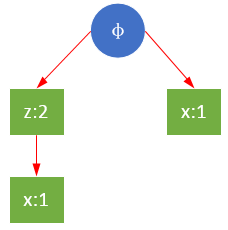
重复上面步骤,r的条件模式基是{z,x},{x},已经没有能够满足最小支持度的路径, 所以r的条件树仅有一个。需要注意的是,虽然{z,x},{x}中共存在两个x,但{z,x}中,z是x的父节点,在构造条件FP树时不能直接将父节点移除,仅能从子节点开始逐级移除。
代码如下:
def ascendTree(leafNode, prefixPath):
if leafNode.parent != None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath) def findPrefixPath(basePat, headTable):
condPats = {}
treeNode = headTable[basePat][1]
while treeNode != None:
prefixPath = []
ascendTree(treeNode, prefixPath)
if len(prefixPath) > 1:
condPats[frozenset(prefixPath[1:])] = treeNode.count
treeNode = treeNode.nodeLink
return condPats def mineTree(inTree, headerTable, minSup=1, preFix=set([]), freqItemList=[]):
# order by minSup asc, value asc
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: (p[1][0],p[0]))]
for basePat in bigL:
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
freqItemList.append(newFreqSet)
# 通过条件模式基找到的频繁项集
condPattBases = findPrefixPath(basePat, headerTable)
myCondTree, myHead = createTree(condPattBases, minSup)
if myHead != None:
print('condPattBases: ', basePat, condPattBases)
myCondTree.disp()
print('*' * 30) mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList) simpDat = loadSimpDat()
dictDat = createInitSet(simpDat)
myFPTree,myheader = createTree(dictDat, 3)
myFPTree.disp()
condPats = findPrefixPath('z', myheader)
print('z', condPats)
condPats = findPrefixPath('x', myheader)
print('x', condPats)
condPats = findPrefixPath('y', myheader)
print('y', condPats)
condPats = findPrefixPath('t', myheader)
print('t', condPats)
condPats = findPrefixPath('s', myheader)
print('s', condPats)
condPats = findPrefixPath('r', myheader)
print('r', condPats) mineTree(myFPTree, myheader, 2)
控制台信息:
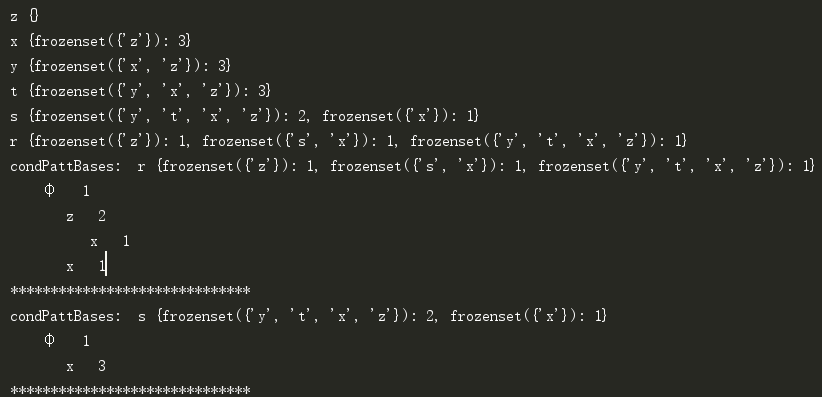
本例可以发现两个频繁项集{z,x}和{x}。
取得频繁项集后,可以根据置信度发现关联规则,这一步较为简单,可参考上篇的相关内容,不在赘述。
出处:微信公众号 "我是8位的"
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注作者公众号“我是8位的”

FP-growth算法发现频繁项集(二)——发现频繁项集的更多相关文章
- Frequent Pattern 挖掘之二(FP Growth算法)
Frequent Pattern 挖掘之二(FP Growth算法) FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断 ...
- Frequent Pattern 挖掘之二(FP Growth算法)(转)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- FP—Growth算法
FP_growth算法是韩家炜老师在2000年提出的关联分析算法,该算法和Apriori算法最大的不同有两点: 第一,不产生候选集,第二,只需要两次遍历数据库,大大提高了效率,用31646条测试记录, ...
- Frequent Pattern (FP Growth算法)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达 到这样的效果,它采用了一种简洁的数据 ...
- 关联规则算法之FP growth算法
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- 机器学习(十五)— Apriori算法、FP Growth算法
1.Apriori算法 Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策. Apriori算法采用了迭代的方法,先搜 ...
- FP Tree算法原理总结
在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题,FP Tree算法(也称F ...
- FP Tree算法原理总结(转载)
FP Tree算法原理总结 在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题 ...
- FP - growth 发现频繁项集
FP - growth是一种比Apriori更高效的发现频繁项集的方法.FP是frequent pattern的简称,即常在一块儿出现的元素项的集合的模型.通过将数据集存储在一个特定的FP树上,然后发 ...
- 算法笔记_118:算法集训之结果填空题集二(Java)
目录 1 欧拉与鸡蛋 2 巧排扑克牌 3 排座位 4 黄金队列 5 汉诺塔计数 6 猜生日 7 棋盘上的麦子 8 国庆星期日 9 找素数 10 填写算式 11 取字母组成串 1 欧拉与鸡蛋 大数 ...
随机推荐
- python-day13--装饰器
1.开放封闭的原则: 1.对扩展是开放的 为什么要对扩展开放呢? 我们说,任何一个程序,不可能在设计之初就已经想好了所有的功能并且未来不做任何更新和修改.所以我们必须允许代码扩展.添加新功能. 2.对 ...
- UVA-11584 Partitioning by Palindromes (简单线性DP)
题目大意:给一个全是小写字母的字符串,判断最少可分为几个回文子序列.如:“aaadbccb” 最少能分为 “aaa” “d” “bccb” 共三个回文子序列,又如 “aaa” 最少能分为 1 个回文子 ...
- [Leetcode] Unique binary search trees 唯一二叉搜索树
Given n, how many structurally unique BST's (binary search trees) that store values 1...n? For examp ...
- js在类似数组的对象中使用push
let obj = { "2": "a", "3": "b", length: 3, push: Array.proto ...
- 返回书签 GotoBookmark
property Bookmark: TBookmark read GetBookmark write GotoBookmark; 直接给Bookmark属性赋值,还是 调用数据集GotoBookma ...
- 在 windows 开发 reactNative 的环境 搭建过程 react-native-android
安装的东西挺多的, 从 jdk 到c++环境 到node , python, 各种模拟器 http://bbs.reactnative.cn/topic/10/%E5%9C%A8windows%E4% ...
- 解决Android4.3版本下,手机短彩接收中文文件名附件,中文名字的附件无法保存(第二步:解决从从数据库中读取附件文件名,并在长按后保存附件时,中文乱码导致的无法保存附件)
从第一步我们发现,在第一步修改之后,在短彩绘画界面中中文附件名的附件已无法显示,经过打印堆栈我们发现还是中文乱码在作祟.下面我们接着进行分析,这次我们从UI层往逻辑处理层进行分析.首先我们找到保存附件 ...
- CSS 网格布局学习
转自:https://blog.jirengu.com/?p=990 CSS网格布局(又名“网格”)是一个二维的基于网格的布局系统,其目的只在于完全改变我们设计基于网格的用户界面的方式. CSS一直用 ...
- UI基础:UIControl及其子类
UISegmentedControl UISegmentedControl 是iOS中的分段控件 每个segment 都能被点击,相当于集成了若干个button. 通常我们会点击不同的segment ...
- C程序第四次作业
作业要求一 实践最简答的项目wordcount,必须完成其中的基本功能,若可以完成其他功能给予加分.完成后请将你的设计思路.主要代码写在本次作业博客里. 设计思路: 第一步:定义文件型指针变量fp,整 ...