mysql中index与Multiple-Column Indexes区别与联系
索引对提升SELECT/UPDATE语句查询速度有着立竿见影的效果,有索引和无索引,查询速度往往差几个数量级。
本次讨论一下index(每列作为一个索引,单列索引)和Multiple-Column Indexes(多列作为一个索引,最多16列,复合索引)使用场景。
常见新建或添加索引的方式:
方式一,建表时新建
CREATE TABLE test (
id INT NOT NULL,
last_name CHAR(30) NOT NULL,
first_name CHAR(30) NOT NULL,
PRIMARY KEY (id),
-- 单列索引
INDEX name (last_name)
-- 复合索引
-- INDEX name (last_name,first_name)
);
方式二,给即存表添加索引:
/*单列索引*/
ALTER TABLE test ADD INDEX name (last_name);
/*复合索引*/
ALTER TABLE test ADD INDEX name (last_name,first_name);
这里要注意索引的顺序很重要,关系到能否命中索引,后面详细讨论。
mysql官方文档是这么描述复合索引的:mysql能使用复合索引来查询索引中的所有列,或者查询复合索引中的第一列、前两列、前三列等等。
如果指定列顺序正确相对于索引中的定义顺序,那么一个简单的复合作引可以加快一个表中几种类型的查询。官网地址
以上这段话包可解读如下:
- 复合索引的优点:一个复合索引解决多种查询的效率问题
- 复合索引的命中规则:前半句话描述的是命中复合索引的最左前缀(leftmost prefix)规则,也就是上面提到的索引顺序问题。这个规则是对于WHERE语句中的索引列的顺的。
简单的说加入复合索引的顺序是(col1, col2, col3)那么WHERE语句中的(col1)、(ol1, col2)、(col1, col2, col3)都能命中索引,但是(col2)、(col3)、(ol2, col3)是不能命中索引规则的,因为不满足最左前缀规则。
举个栗子,假设新建复合索引如下:
CREATE TABLE test (
id INT NOT NULL,
last_name CHAR(30) NOT NULL,
first_name CHAR(30) NOT NULL,
PRIMARY KEY (id),
INDEX name (last_name,first_name)
);
根据最左前缀原则,以下查询语句能命中索引:
SELECT * FROM test WHERE last_name='Widenius'; SELECT * FROM test
WHERE last_name='Widenius' AND first_name='Michael'; SELECT * FROM test
WHERE last_name='Widenius'
AND (first_name='Michael' OR first_name='Monty'); SELECT * FROM test
WHERE last_name='Widenius'
AND first_name >='M' AND first_name < 'N';
以下查询语句不能命中复合索引:
SELECT * FROM test WHERE first_name='Michael'; SELECT * FROM test
WHERE last_name='Widenius' OR first_name='Michael';
如果不清楚是否命中索引,EXPLAIN是个好工具,要充分利用起来。比如下语句,查看结果中的key就能知道是否命中,为空就是木有命中:
EXPLAIN SELECT * FROM test WHERE first_name='Michael';
使用场景:
在做报表集计一般会使用ETL工具抽取业务数据插入到事实表中,就比如使用kettle update/insert,其内部原理都是先查询不存在就如插入数据,存在数据就更新。
因此如果数据很多的话就会有很多的查询动作,并且是多条件查询。这种情况复合索引效率是最高的,但是往往实际的业务中还会以单列作为查询的场合这是就需要普通索引来满足这个需求。
这种场合就会出现同一列同时出现在了复合索引和单列索引中,这也是很正常的。给一个实际的例子如下:
CREATE TABLE `st_stock` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`id_company` int(11) NOT NULL COMMENT '组织维度',
`id_date` int(11) NOT NULL COMMENT '日期维度',
`id_part` int(11) NOT NULL COMMENT '材料维度',
`number` decimal(18,2) DEFAULT NULL COMMENT '出库数量',
`subtotal` decimal(21,6) DEFAULT NULL COMMENT '出库金额',
PRIMARY KEY (`id`),
KEY `IDX_ORG` (`id_company`),
KEY `IDX_PART` (`id_part`),
KEY `IDX_DATE_ORG_PART` (`id_date`,`id_company`,`id_part`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='xxxxxx';
实际疗效:
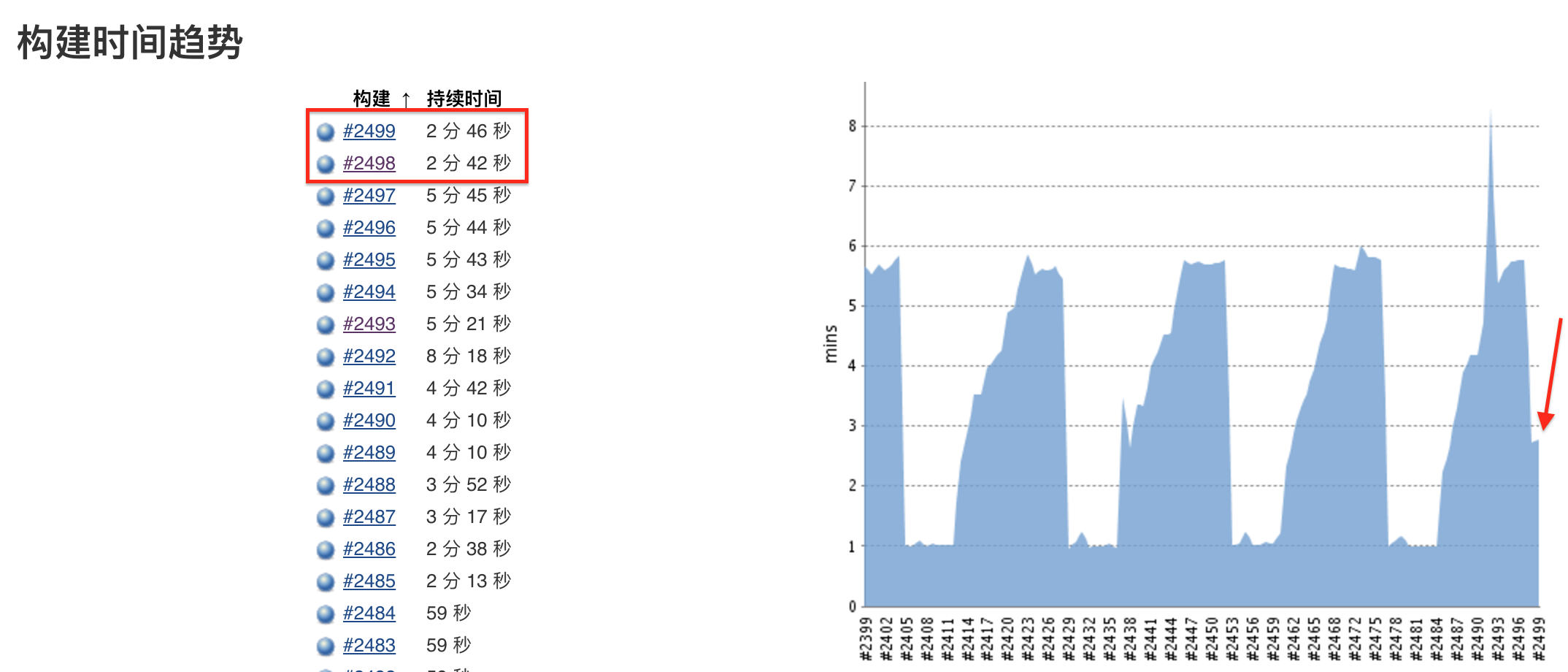
#2498和#2499数据量大于等于#2496、#2497,但集计时间将近缩短了一半,效果还是很明显。
优化效果没有达到一个数量或更高级是因为优化的只是JOB中一个转换,只是优化的众多因素之一。
即便如此也达到了预期的效果。
最后还要注意一点,索引的维护是有代价的,并不是越多越好。其他参考资料如下:
https://www.percona.com/blog/2009/09/19/multi-column-indexes-vs-index-merge/
https://www.percona.com/blog/2014/01/03/multiple-column-index-vs-multiple-indexes-with-mysql-56/
https://dev.mysql.com/doc/refman/5.7/en/drop-index.html
https://dev.mysql.com/doc/refman/5.6/en/multiple-column-indexes.html
https://dev.mysql.com/doc/refman/5.7/en/create-index.html
mysql中index与Multiple-Column Indexes区别与联系的更多相关文章
- Mysql中unique与primary约束的区别分析(转)
本文章来给大家介绍在mysql中unique与primary约束的区别分析,unique与primary是我们在创建mysql时常用的类型了,下面我来给大家介绍介绍. 定义了UNIQUE约束的字段 ...
- 万答#11,MySQL中char与varchar有什么区别
万答#11,MySQL中char与varchar有什么区别 1.实验场景 GreatSQL 8.0.25 InnoDB 2.实验测试 2.1 区别 参数 char varchar 长度是否可变 定长 ...
- mysql函数count(*)和count(column)的区别(转)
mysql中count(*)和count(column)使用是有区别的: count(*)对行的数目进行计算,包含NULL count(column)对特定的列的值具有的行数进行计算,不包含NULL值 ...
- MySQL中index和key的关系
KEY is normally a synonym for INDEX. The key attribute PRIMARY KEY can also be specified as just KEY ...
- mysql中in和exists二者的区别和性能影响
mysql查询语句in和exists二者的区别和性能影响 还记得一次面试中被人问到in 和 exists的区别,当然只是草草做答,现在来做下分析. mysql中的in语句是把外表和内表作hash 连接 ...
- mysql中where和having子句的区别和具体用法
1.mysql中的where和having子句的区别 having的用法 having字句可以让我们筛选成组后的各种数据,where字句在聚合前先筛选记录,也就是说作用在group by和having ...
- 正确理解MySQL中的where和having的区别
原文:https://blog.csdn.net/yexudengzhidao/article/details/54924471 以前在学校里学习过SQLserver数据库,发现学习的都是皮毛,今天以 ...
- Mysql 中is null 和 =null 的区别
在mysql中,筛选非空的时候经常会用到is not null和!=null,这两种方法单从字面上来看感觉是差不多的,其实如 果去运行一下试试的话差别会很大! 为什么会出现这种情况呢? null 表示 ...
- mysql中 date datetime time timestamp 的区别
MySQL中关于时间的数据类型:它们分别是 date.datetime.time.timestamp.year date :"yyyy-mm-dd" 日期 1000-01 ...
- Mysql中的in和find_in_set的区别?
在mysql中in的使用情况如下: select * from article where 列名 in(值1,值2,值3.....): select * from article where 值1 i ...
随机推荐
- Thread类的常见问题
void waitForSignal() { Object obj = new Object(); synchronized(Thread.currentThread()) { obj.wait(); ...
- 容器集成平台 rancher部署
下载rancher镜像 docker pull rancher/server:stable rancher/server:latest #开发版 rancher/server:stable #稳定版 ...
- mysql 开启慢查询
linux启用MySQL慢查询 vim /etc/my.cnf [mysqld] slow-query-log = on slow_query_log_file = /var/log/slow_que ...
- Jmeter接口测试自动化 (三)(数据驱动测试)
本文转载至http://www.cnblogs.com/chengtch/p/6105532.html 当我研究要通过用例优先级控制用例是否执行时,我发现了用"如果(if)控制器" ...
- os模块的使用
python编程时,经常和文件.目录打交道,这是就离不了os模块.os模块包含普遍的操作系统功能,与具体的平台无关.以下列举常用的命令 1. os.name()——判断现在正在实用的平台,Window ...
- unity3d-Visual Studio Tools for Unity快捷键
1.首先 当安装for unity 后,打开vs2013(我使用的是vs2013),右键可以看到for unity 提供了两个快捷键 2.其次 (Ctrl+Shift+M) 3.最后(Ctrl+Shi ...
- http协议基础(十)实体首部字段
1.定义 包含在请求和响应中的实体部分所使用的首部,用于补充内容的更新时间等与实体相关的信息 2.Allow 通知客户端能够支持的Request-URI指定资源的所有http方法:如果服务器接收到不支 ...
- ATG精准科技-前端面试题
1.请写出以下结果 for(var i=0; i<10; i++){ setTimeout(function () { console.log(i) },10) } 结果:打印10次190解析: ...
- hdu5195 二分+线段树+拓扑序
这题说的给了n个点m条边要求保证是一个有向无环图,可以删除至多k条边使得这个图的拓扑序的字典序最大,我们知道如果我们要排一个点的时候一定要考虑比他大的点是否可以.通过拆边马上拆出来,如果可以拆当然是拆 ...
- Root :: AOAPC I: Beginning Algorithm Contests (Rujia Liu) Volume 7. Graph Algorithms and Implementation Techniques
uva 10803 计算从任何一个点到图中的另一个点经历的途中必须每隔10千米 都必须有一个点然后就这样 floy 及解决了 ************************************* ...