CentOS7下 简单安装和配置Elasticsearch Kibana Filebeat 快速搭建集群日志收集平台
1.添加elasticsearch官网的yum源
cd /etc/yum.repos.d/
vi CentOS-Base.repo
在末尾添加内容如下:
[elastic-6.x]
name=Elastic repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
点击ESC 输入:wq [回车键],进行保存(基础操作,后边不再提示)
执行以下命令:
yum clean all
yum makecache
2.Elasticsearch
elasticsearch是个搜索引擎,可以存放数据,也可以为数据建立索引,这里我只是用他来存放和搜索日志信息,没有用的太深入。
安装elasticsearch
方式一(需要添加elasticsearch官网的yum源,方法见上文):
yum install -y elasticsearch
方式二:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.rpm
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.rpm.sha512
shasum -a 512 -c elasticsearch-6.3.2.rpm.sha512
sudo rpm --install elasticsearch-6.3.2.rpm
配置elasticsearch
vi /etc/elasitcsearch/elasticsearch.yml
添加内容(注意冒号后有空格,下文不再提示):
network.host: [ELASTICSEARCH服务器的IP]
http.port: 9200
保存,如果不配置成实际的IP地址,则只能在localhost中查看;9200是默认端口,第二行不配也是可以的。
如果开了防火墙,开放上文对应端口:
firewall-cmd --add-port=9200/tcp --permanent
firewall-cmd --reload
启动elasticsearch并设为开机启动
systemctl start elasticsearch
systemctl enable elasticsearch
启动后访问 [ELASTICSEARCH服务器的IP]:9200 端口,可以看到类似内容:
{
"name" : "Y247g1N",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "wfwynAOWR7SV9aEitx-sgw",
"version" : {
"number" : "6.3.2",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "053779d",
"build_date" : "2018-07-20T05:20:23.451332Z",
"build_snapshot" : false,
"lucene_version" : "7.3.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
3.Kibana
安装kibana
yum install -y kibana
配置kibana
vi /etc/kibana/kibana.yml
添加内容:
server.port: 5601
server.host: "[KIBANA的IP]"
elasticsearch.url: "http://[ELASTICSEARCH服务器的IP]:9200"
如果开了防火墙,开放上文对应端口:
firewall-cmd --add-port=5601/tcp --permanent
firewall-cmd --reload
启动kibana并设为开机启动
systemctl start kibana
systemctl enable kibana
访问[KIBANA的IP]:5601端口,可以打开kibana,此时kibana已经和elasticsearch建立联系,不过因为elasticsearch没有被导入任何数据,所以没有实际意义,下一步我们把日志通过filebeat收集到elasticsearch。
4.Filebeat
filebeat可以用来收集各种日志文件,并导入到elasticsearch中,需要在每台被收集日志的机器上安装
安装filebeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.3.2-x86_64.rpm
sudo rpm -vi filebeat-6.3.2-x86_64.rpm
配置filebeat
vi /etc/filebeat/filebeat.yml
在下文的paths: 下,增加你日志的路径信息,并把enabled设为true
filebeat.inputs:
- type: log
enabled: true
paths:
- /[你的日志路径,可以用一个*代表一层目录]/current.log
elasticsearch的地址改成你刚才设置的地址:
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["[ELASTICSEARCH的IP]:9200"]
启动filebeat并设为开机启动
systemctl start filebeat
systemctl enable filebeat
5.操作Kibana界面,显示收集的日志

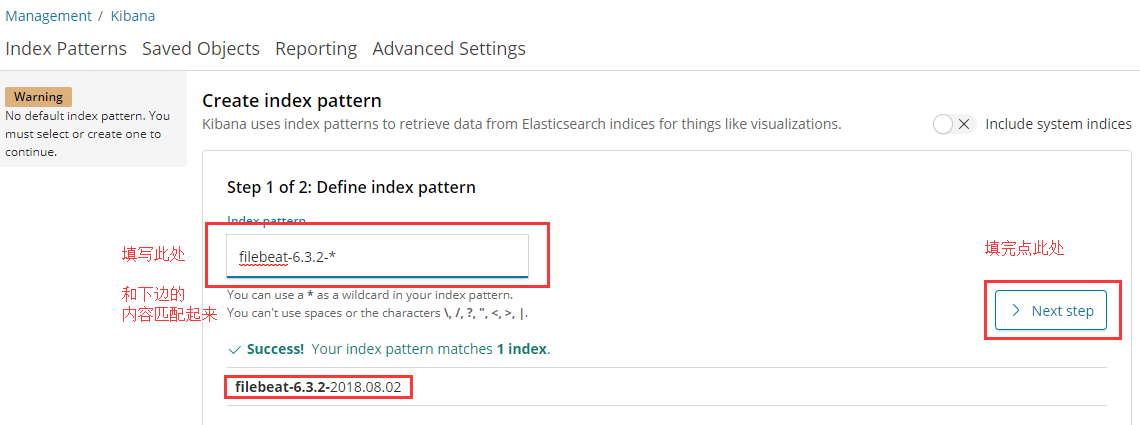
接下来在下拉框中选择 @timestamp ,并点击完成
最后进入
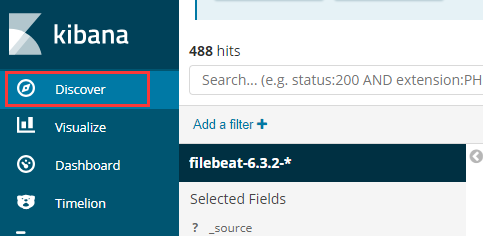
可以看到刚才配置的“Index Patterns”,以及其下的所有日志文件。在界面上可以搜索和过滤,快速找到想要的内容。
完毕
CentOS7下 简单安装和配置Elasticsearch Kibana Filebeat 快速搭建集群日志收集平台的更多相关文章
- 安装logstash+kibana+elasticsearch+redis搭建集中式日志分析平台
安装logstash+kibana+elasticsearch+redis搭建集中式日志分析平台 2014-01-16 19:40:57| 分类: logstash | 标签:logstash ...
- centos7搭建ELK Cluster集群日志分析平台(三):Kibana
续 centos7搭建ELK Cluster集群日志分析平台(一) 续 centos7搭建ELK Cluster集群日志分析平台(二) 已经安装好elasticsearch 5.4集群和logst ...
- centos7搭建ELK Cluster集群日志分析平台(一):Elasticsearch
应用场景: ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平 ...
- centos7搭建ELK Cluster集群日志分析平台
应用场景:ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平台 ...
- centos7搭建ELK Cluster集群日志分析平台(二):Logstash
续 centos7搭建ELK Cluster集群日志分析平台(一) 已经安装完Elasticsearch 5.4 集群. 安装Logstash步骤 . 安装Java 8 官方说明:需要安装Java ...
- centos7搭建ELK Cluster集群日志分析平台(四):Fliebeat-简单测试
续之前安装好的ELK集群 各主机:es-1 ~ es-3 :192.168.1.21/22/23 logstash: 192.168.1.24 kibana: 192.168.1.25 测试机:cli ...
- CentOS7下Supervisor安装与配置
Supervisor(http://supervisord.org/)是用Python开发的一个client/server服务,是Linux/Unix系统下的一个进程管理工具,不支持Windows系统 ...
- fluentd结合kibana、elasticsearch实时搜索分析hadoop集群日志<转>
转自 http://blog.csdn.net/jiedushi/article/details/12003171 Fluentd是一个开源收集事件和日志系统,它目前提供150+扩展插件让你存储大数据 ...
- Centos7 下cobbler安装及配置
1.背景介绍 作为运维,在公司经常遇到一些机械性重复工作要做,例如:为新机器装系统,一台两台机器装系统,可以用光盘.U盘等介质安装,1小时也完成了,但是如果有成百台的服务器还要用光盘.U盘去安装,就显 ...
随机推荐
- Git项目的初始化
快速设置— 如果你知道该怎么操作,直接使用下面的地址 git@github.com:username/myproject.git 我们强烈建议所有的git仓库都有一个README, LICENSE, ...
- 如何设置浏览器禁止使用UC浏览器
通过UA可以判断浏览器是否是UC浏览器 if(navigator.userAgent.indexOf('UCBrowser')>-1) { alert("当前浏览器不支持本站,建议更 ...
- C#自带类库实现邮件发送
1.首先引入命名空间using System.Net.Mail; 2.将发送的邮件的功能封装成一个类,该类中包含了发送邮件的基本功能:收件人(多人),抄送(多人),发送人,主题,邮件正文,附件等,封装 ...
- Service 简介 启动方式 生命周期 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- SQLSERVER 免费对比数据库结构和数据的工具支持:SQL Server 2012, SQL Server 2008 and SQL Server 2005
New xSQL Schema Compare - version 5 Compare the schemas of two SQL Server databases, review differen ...
- 逻辑回归应用之Kaggle泰坦尼克之灾
机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾 标签: 机器学习应用 2015-11-12 13:52 3688人阅读 评论(15) 收藏 举报 本文章已收录于: 机器学习知识库 分类 ...
- Jquery中的高度
$('.someElement').height(); // returns the calculated pixel height of the element(s) $(window).heigh ...
- CAD2006您没有足够的权限来安装本产品
在Win10的环境下安装CAD2006,可能会报错"您没有足够的权限来安装本产品". 解决方法是,右键以"兼容性疑难解答"运行 在弹出的对话框中,点击 &quo ...
- 微信小程序 - 下拉菜单组件
使用: 1.导入组件 2.使用组件 3.数据传入 4. 获取数据(通过同步缓存,获取“choose”)- 发送到后端 点击下载:小程序-下拉组件.
- excel自定义数据验证
1. 判断必须为5位或者9位的数字 2. 自定义限制级别和提示消息