Spark学习笔记4:数据读取与保存
Spark对很多种文件格式的读取和保存方式都很简单。Spark会根据文件扩展名选择对应的处理方式。
Spark支持的一些常见文件格式如下:

- 文本文件
使用文件路径作为参数调用SparkContext中的textFile()函数,就可以读取一个文本文件。也可以指定minPartitions控制分区数。传递目录作为参数,会把目录中的各部分都读取到RDD中。例如:
val input = sc.textFile("E:\\share\\new\\chapter5")
input.foreach(println)
chapter目录有三个txt文件,内容如下:
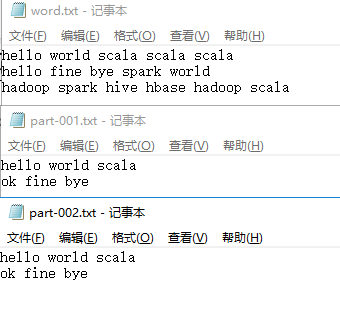
输出结果:

用SparkContext.wholeTextFiles()也可以处理多个文件,该方法返回一个pair RDD,其中键是输入文件的文件名。
例如:
val input = sc.wholeTextFiles("E:\\share\\new\\chapter5")
input.foreach(println)
输出结果:

保存文本文件用saveAsTextFile(outputFile)
- JSON
JSON是一种使用较广的半结构化数据格式,这里使用json4s来解析JSON文件。
如下:
import org.apache.spark.{SparkConf, SparkContext}
import org.json4s.ShortTypeHints
import org.json4s.jackson.JsonMethods._
import org.json4s.jackson.Serialization
object TestJson {
case class Person(name:String,age:Int)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("JSON")
val sc = new SparkContext(conf)
implicit val formats = Serialization.formats(ShortTypeHints(List()))
val input = sc.textFile("E:\\share\\new\\test.json")
input.collect().foreach(x => {var c = parse(x).extract[Person];println(c.name + "," + c.age)})
}
}
json文件内容:
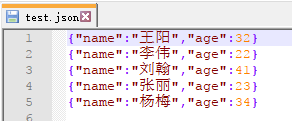
输出结果:

保存JSON文件用saveASTextFile(outputFile)即可
如下:
val datasave = input.map { myrecord =>
implicit val formats = DefaultFormats
val jsonObj = parse(myrecord)
jsonObj.extract[Person]
}
datasave.saveAsTextFile("E:\\share\\spark\\savejson")
输出结果:

- CSV文件
读取CSV文件和读取JSON数据相似,都需要先把文件当作普通文本文件来读取数据,再对数据进行处理。
如下:
import org.apache.spark.{SparkConf, SparkContext}
import java.io.StringReader
import au.com.bytecode.opencsv.CSVReader
object DataReadAndSave {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("CSV")
val sc = new SparkContext(conf)
val input = sc.textFile("E:\\share\\spark\\test.csv")
input.foreach(println)
val result = input.map{
line =>
val reader = new CSVReader(new StringReader(line))
reader.readNext()
}
for(res <- result){
for(r <- res){
println(r)
}
}
}
}
test.csv内容:

输出结果:

保存csv
如下:
val inputRDD = sc.parallelize(List(Person("Mike", "yes")))
inputRDD.map(person => List(person.name,person.favoriteAnimal).toArray)
.mapPartitions { people =>
val stringWriter = new StringWriter()
val csvWriter = new CSVWriter(stringWriter)
csvWriter.writeAll(people.toList)
Iterator(stringWriter.toString)
}.saveAsTextFile("E:\\share\\spark\\savecsv")
- SequenceFile
SequenceFile是由没有相对关系结构的键值对文件组成的常用Hadoop格式。是由实现Hadoop的Writable接口的元素组成,常见的数据类型以及它们对应的Writable类如下:

读取SequenceFile
调用sequenceFile(path , keyClass , valueClass , minPartitions)
保存SequenceFile
调用saveAsSequenceFile(outputFile)
- 对象文件
对象文件使用Java序列化写出,允许存储只包含值的RDD。对象文件通常用于Spark作业间的通信。
保存对象文件调用 saveAsObjectFile 读取对象文件用SparkContext的objectFile()函数接受一个路径,返回对应的RDD
- Hadoop输入输出格式
Spark可以与任何Hadoop支持的格式交互。
读取其他Hadoop输入格式,使用newAPIHadoopFile接收一个路径以及三个类,第一个类是格式类,代表输入格式,第二个类是键的类,最后一个类是值的类。
hadoopFile()函数用于使用旧的API实现的Hadoop输入格式。
KeyValueTextInputFormat 是最简单的 Hadoop 输入格式之一,可以用于从文本文件中读取键值对数据。每一行都会被独立处理,键和值之间用制表符隔开。
例子:
import org.apache.hadoop.io.{IntWritable, LongWritable, MapWritable, Text}
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark._
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
object HadoopFile {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("hadoopfile").setMaster("local")
val sc = new SparkContext(conf)
val job = new Job()
val data = sc.newAPIHadoopFile("E:\\share\\spark\\test.json" ,
classOf[KeyValueTextInputFormat],
classOf[Text],
classOf[Text],
job.getConfiguration)
data.foreach(println)
data.saveAsNewAPIHadoopFile(
"E:\\share\\spark\\savehadoop",
classOf[Text],
classOf[Text],
classOf[TextOutputFormat[Text,Text]],
job.getConfiguration)
}
}
输出结果:
读取

保存

若使用旧API如下:
val input = sc.hadoopFile[Text, Text, KeyValueTextInputFormat]("E:\\share\\spark\\test.json
").map { case (x, y) => (x.toString, y.toString) } input.foreach(println)
- 文件压缩
对数据进行压缩可以节省存储空间和网络传输开销,Spark原生的输入方式(textFile和sequenFile)可以自动处理一些类型的压缩。在读取压缩后的数据时,一些压缩编解码器可以推测压缩类型。
- 文件系统
Spark支持读写很多种文件系统,可以使用任何我们想要的文件格式。包括:
1、本地文件系统
要求文件在集群中所有节点的相同路径下都可以找到。 本地文件系统路径使用 例如:val rdd = sc.textFile("file:///home/holden/happypandas.gz")。
2、Amazon S3
将一个以s3n://开头的路径以s3n://bucket/path-within-bucket的形式传给Spark的输入方法。
3、HDFS
在Spark中使用HDFS只需要将输入路径输出路径指定为hdfs://master:port/path就可以了
- Apache Hive
Apache Hive是Hadoop上一中常见的结构化数据源。Hive可以在HDFS内或者在其他存储系统上存储多种格式的表。SparkSQL可以读取Hive支持的任何表。
将Spark SQL连接到已有的Hive上,创建出HiveContext对象也就是Spark SQL入口,然后就可以使用Hive查询语言来对你的表进行查询,并以由行组成的RDD形式返回数据。
使用HiveContext.jsonFile方法可以从整个文件中获取Row对象组成的RDD。例子:
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} object Sparksql {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SparkSQL")
val sc = new SparkContext(conf)
val sql = new HiveContext(sc)
val input = sql.jsonFile("E:\\share\\spark\\tweets.json")
input.registerTempTable("tweets")
val topTweets = sql.sql("select user.name,text from tweets")
topTweets.foreach(println)
} }
使用数据:

输出结果:

- 数据库
Spark可以从任何支持Java数据库连接(JDBC)的关系型数据库中读取数据,包括MySQL,Postgre等系统。
Spark连接JDBC,通过创建SQLContext对象进行连接,设置连接参数,然后就可以使用sql语句进行查询,结果返回一个jdbcRDD。如下:
首先在MySQL里面建立名为info的数据库,建表及导入数据:
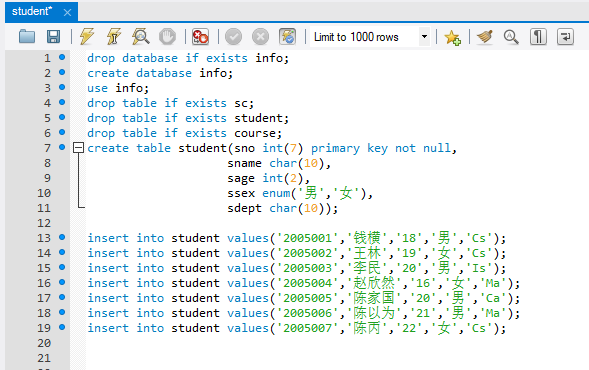
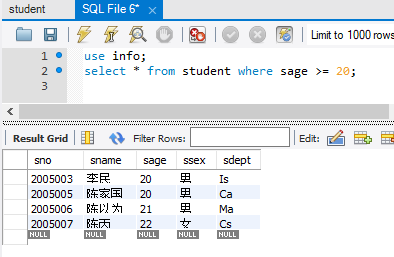
sql查询数据:
使用Spark连接JDBC查询,Scala代码如下:
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext} object JDBC {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("SparkSQL")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val mysql = sqlContext.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/info").
option("dbtable","student").option("driver","com.mysql.jdbc.Driver").
option("user","root").option("password","********").load()
mysql.registerTempTable("student")
mysql.sqlContext.sql("select * from student where sage >= 20").collect().foreach(println)
} }
输出结果:

Spark学习笔记4:数据读取与保存的更多相关文章
- TensorFlow基础笔记(1) 数据读取与保存
https://zhuanlan.zhihu.com/p/27238630 WholeFileReader # 我们用一个具体的例子感受tensorflow中的数据读取.如图, # 假设我们在当前文件 ...
- 【原】Learning Spark (Python版) 学习笔记(二)----键值对、数据读取与保存、共享特性
本来应该上周更新的,结果碰上五一,懒癌发作,就推迟了 = =.以后还是要按时完成任务.废话不多说,第四章-第六章主要讲了三个内容:键值对.数据读取与保存与Spark的两个共享特性(累加器和广播变量). ...
- Spark学习之数据读取与保存总结(一)
一.动机 我们已经学了很多在 Spark 中对已分发的数据执行的操作.到目前为止,所展示的示例都是从本地集合或者普通文件中进行数据读取和保存的.但有时候,数据量可能大到无法放在一台机器中,这时就需要探 ...
- Spark学习之数据读取与保存(4)
Spark学习之数据读取与保存(4) 1. 文件格式 Spark对很多种文件格式的读取和保存方式都很简单. 如文本文件的非结构化的文件,如JSON的半结构化文件,如SequenceFile结构化文件. ...
- matlab学习笔记4--多媒体文件的保存和读取
一起来学matlab-matlab学习笔记4 数据导入和导出_2 多媒体文件的保存和读取 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考书籍 <matlab 程序设计与综合应用&g ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Windows phone 8 学习笔记(2) 数据文件操作
原文:Windows phone 8 学习笔记(2) 数据文件操作 Windows phone 8 应用用于数据文件存储访问的位置仅仅限于安装文件夹.本地文件夹(独立存储空间).媒体库和SD卡四个地方 ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
随机推荐
- KBMMW 的日志管理器
kbmmw 4.82 最大的新特性就是增加了 日志管理器. 新的日志管理器实现了不同类型的日志.断言.异常处理.计时等功能. 首先.引用kbmMWLog.pas 单元后,系统就默认生成一个IkbmMW ...
- OSI七层网络模型与TCP/IP四层模型介绍
目录 OSI七层网络模型与TCP/IP四层模型介绍 1.OSI七层网络模型介绍 2.TCP/IP四层网络模型介绍 3.各层对应的协议 4.OSI七层和TCP/IP四层的区别 5.交换机工作在OSI的哪 ...
- ModuleNotFoundError: No module named '_tkinter'
https://blog.csdn.net/blueheart20/article/details/78763208 apt search python3-tk apt install python3 ...
- Guided Image Filtering
在图像滤波中,人们最希望的就是可以将图像中的噪声过滤掉的同时,能够让边缘尽可能的保持.噪声属于高频信号,而边缘其实也是一种高频信号,所以一般的滤波器,比如高斯模糊,均值模糊,都是一种低通滤波器,能够将 ...
- hdu-5810 Balls and Boxes(概率期望)
题目链接: Balls and Boxes Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/O ...
- php变量什么情况下加大括号{}
下面几个比较能说明原因的解释是: 表示{}里面的是一个变量 ,执行时按照变量来处理 在字符串中引用变量使用的特殊包括方式,这样就可以不使用.运算符,从而减少代码的输入量了. 其实输出那块是等同于pr ...
- 查看camera设备-linux
前言 本文介绍如何在linux平台查看是否有camera外设. 操作过程 1.打开shell,输入以下命令: ls /dev/video* 即可查看是否有camera外设: 2.如果确实连接了came ...
- BZOJ4710: [Jsoi2011]分特产【组合数学+容斥】
Description JYY 带队参加了若干场ACM/ICPC 比赛,带回了许多土特产,要分给实验室的同学们. JYY 想知道,把这些特产分给N 个同学,一共有多少种不同的分法?当然,JYY 不希望 ...
- ThinkPHP3.2.3整合smarty模板(三)
在smarty模板中使用thinkphp框架的U方法时要主要的问题: 1.不能直接使用{:U('Index/index')}: 2.正确的使用方法为:<!--{U("Login/log ...
- 第三周作业3——Bug Report
作业要求来自:https://edu.cnblogs.com/campus/nenu/SWE2017FALL/homework/957 要求1: 准备工作:利用老师提供的git 命令,批量pull所有 ...