kafka基本概念
介绍
Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计。
这个独特的设计是什么样的呢?
首先让我们看几个基本的消息系统术语:
Kafka将消息以topic为单位进行归纳。
将向Kafka topic发布消息的程序成为producers.
将预订topics并消费消息的程序成为consumer.
Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker.
producers通过网络将消息发送到Kafka集群,集群向消费者提供消息,如下图所示:
<ignore_js_op>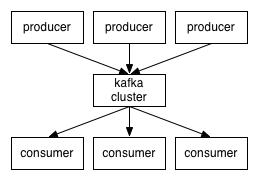
客户端和服务端通过TCP协议通信。Kafka提供了Java客户端,并且对多种语言都提供了支持。
Topics 和Logs
先来看一下Kafka提供的一个抽象概念:topic.
一个topic是对一组消息的归纳。对每个topic,Kafka 对它的日志进行了分区,如下图所示:
<ignore_js_op>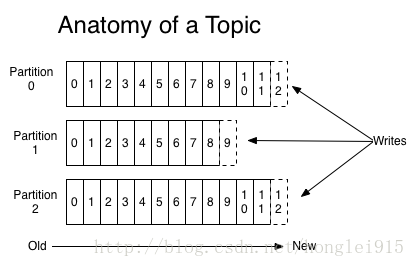
每个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一的标识这个消息。
在一个可配置的时间段内,Kafka集群保留所有发布的消息,不管这些消息有没有被消费。比如,如果消息的保存策略被设置为2天,那么在一个消息被发布的两天时间内,它都是可以被消费的。之后它将被丢弃以释放空间。Kafka的性能是和数据量无关的常量级的,所以保留太多的数据并不是问题。
实际上每个consumer唯一需要维护的数据是消息在日志中的位置,也就是offset.这个offset有consumer来维护:一般情况下随着consumer不断的读取消息,这offset的值不断增加,但其实consumer可以以任意的顺序读取消息,比如它可以将offset设置成为一个旧的值来重读之前的消息。
以上特点的结合,使Kafka consumers非常的轻量级:它们可以在不对集群和其他consumer造成影响的情况下读取消息。你可以使用命令行来"tail"消息而不会对其他正在消费消息的consumer造成影响。
将日志分区可以达到以下目的:首先这使得每个日志的数量不会太大,可以在单个服务上保存。另外每个分区可以单独发布和消费,为并发操作topic提供了一种可能。
分布式
每个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务可以共同处理数据和请求,副本数量是可以配置的。副本使Kafka具备了容错能力。
每个分区都由一个服务器作为“leader”,零或若干服务器作为“followers”,leader负责处理消息的读和写,followers则去复制leader.如果leader down了,followers中的一台则会自动成为leader。集群中的每个服务都会同时扮演两个角色:作为它所持有的一部分分区的leader,同时作为其他分区的followers,这样集群就会据有较好的负载均衡。
Producers
Producer将消息发布到它指定的topic中,并负责决定发布到哪个分区。通常简单的由负载均衡机制随机选择分区,但也可以通过特定的分区函数选择分区。使用的更多的是第二种。
Consumers
发布消息通常有两种模式:队列模式(queuing)和发布-订阅模式(publish-subscribe)。队列模式中,consumers可以同时从服务端读取消息,每个消息只被其中一个consumer读到;发布-订阅模式中消息被广播到所有的consumer中。Consumers可以加入一个consumer 组,共同竞争一个topic,topic中的消息将被分发到组中的一个成员中。同一组中的consumer可以在不同的程序中,也可以在不同的机器上。如果所有的consumer都在一个组中,这就成为了传统的队列模式,在各consumer中实现负载均衡。如果所有的consumer都不在不同的组中,这就成为了发布-订阅模式,所有的消息都被分发到所有的consumer中。更常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组由若干consumer组成。这其实就是一个发布-订阅模式,只不过订阅者是个组而不是单个consumer。
<ignore_js_op>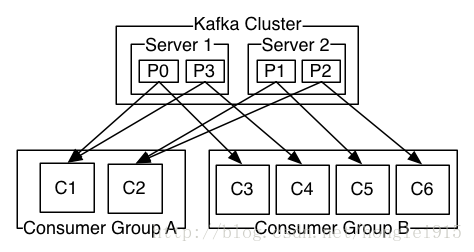
由两个机器组成的集群拥有4个分区 (P0-P3) 2个consumer组. A组有两个consumerB组有4个
相比传统的消息系统,Kafka可以很好的保证有序性。
传统的队列在服务器上保存有序的消息,如果多个consumers同时从这个服务器消费消息,服务器就会以消息存储的顺序向consumer分发消息。虽然服务器按顺序发布消息,但是消息是被异步的分发到各consumer上,所以当消息到达时可能已经失去了原来的顺序,这意味着并发消费将导致顺序错乱。为了避免故障,这样的消息系统通常使用“专用consumer”的概念,其实就是只允许一个消费者消费消息,当然这就意味着失去了并发性。
在这方面Kafka做的更好,通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。将每个分区分只分发给一个consumer组,这样一个分区就只被这个组的一个consumer消费,就可以顺序的消费这个分区的消息。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。注意consumer组的数量不能多于分区的数量,也就是有多少分区就允许多少并发消费。
Kafka只能保证一个分区之内消息的有序性,在不同的分区之间是不可以的,这已经可以满足大部分应用的需求。如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然也就只有一个consumer组消费它。
kafka基本概念的更多相关文章
- Zookeeper与Kafka基础概念和原理
1.zookeeper概念介绍 在介绍ZooKeeper之前,先来介绍一下分布式协调技术,所谓分布式协调技术主要是用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种共享资源,防止造成 ...
- Kafka核心概念(转)
转自:https://blog.csdn.net/liyiming2017/article/details/82805479 1.Kafka集群结构 实际上kafka的结构图是有些区别的,现在我们看下 ...
- Kafka 基础概念及架构
一.Kafka 介绍 Kafka是⼀个分布式.分区的.多副本的.多⽣产者.多订阅者,基于zookeeper协调的分布式⽇志系统(也可以当做MQ系统),常⻅可以⽤于web/nginx⽇志.访问⽇志,消息 ...
- [Kafka] - Kafka基本概念介绍
Kafka官方介绍:Kafka是一个分布式的流处理平台(0.10.x版本),在kafka0.8.x版本的时候,kafka主要是作为一个分布式的.可分区的.具有副本数的日志服务系统(Kafka™ is ...
- Kafka基本概念介绍
Kafka官方介绍:Kafka是一个分布式的流处理平台(0.10.x版本),在kafka0.8.x版本的时候,kafka主要是作为一个分布式的.可分区的.具有副本数的日志服务系统(Kafka™ is ...
- kafka 名词概念
ProducerConsumerBrokerTopicPartitionConsumer Group分布式 Broker Kafka集群包含一个或多个服务器,这种服务器被称为brokerTop ...
- kafka原理概念提炼
Kafka Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实 ...
- kafka基础概念
kafka介绍 kafka is a distributed, partitiononed,replicated commited logservice. kafka是一个分布式的.易扩展的.安全性高 ...
- kafka基本概念和hello world搭建
什么是kafka? Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据 ...
随机推荐
- Java运行时动态加载类之ClassLoader
https://blog.csdn.net/fjssharpsword/article/details/64922083 *************************************** ...
- uboot——之初体验
官方下载地址:ftp://ftp.denx.de/pub/u-boot/ uboot的终极奥义就是启动内核. 但是,现在,我们先做最基本的,去官网下载一个支持自己板子的uboot,然后解压缩,打补丁. ...
- jQuery之自定义datagrid控件
sldatagrid 效果: sldatagrid.js (function($) { function loadColumns(sldatagrid, columns) { $(sldatagrid ...
- 1. EM算法-数学基础
1. EM算法-数学基础 2. EM算法-原理详解 3. EM算法-高斯混合模型GMM 4. EM算法-高斯混合模型GMM详细代码实现 5. EM算法-高斯混合模型GMM+Lasso 1. 凸函数 通 ...
- C# ASP.NET B/S模式下,采用lock语法 实现多用户并发产生不重复递增单号的一种解决方法技术参考
有时候也好奇,若是老外发个技术文章,会不会到处是有人骂街的?进行人身攻击的?中国人喜欢打击别人,不知道老外是不是也是这个性格?好奇的问一下大家. 往往我们在开发程序.调试程序时,无法模拟多用户同时操作 ...
- JVM相关命题的博客整理及总结
JVM垃圾回收基础介绍 http://www.jianshu.com/p/57457a351b8a 减少JVM中逃逸对象的使用 http://www.importnew.com/23150.html ...
- DataTable 行删除
今天在阅读一个项目中的代码时,发现删除DataTable的数据时用的dataTable.Clear(); 由于以前自己习惯都是用dataTable.Rows.Clear();因此突然感觉到很茫然,难道 ...
- Hbase 学习(七) rowkey设计
一直以来对rowkey的设计都比较迷茫,<hbase权威指南>倒是给出了个还算靠谱的例子. 下面这个例子有点儿像帖子表结构,它的rowkey设计是这样的,可以简单的理解为,什么人在什么时间 ...
- Android指南 - 主题
译者注:theme(主题)和style(样式)是专用术语,下面对这两个词汇不在使用中文词汇. theme 是安卓的一种机制,用于为应用程序和activity提供一致的样式(style).样式s ...
- 【C】——如何用线程进行参数的传递
直接上代码: #include<pthread.h> #include<stdio.h> struct val{ int num1; int num2; }; //send a ...