node.js基本工作原理及流程
概述
Node.js是什么
Node 是一个服务器端 JavaScript 解释器,用于方便地搭建响应速度快、易于扩展的网络应用。Node.js 使用事件驱动, 非阻塞I/O 模型而得以轻量和高效,非常适合在分布式设备上运行数据密集型的实时应用。
Node.js 是一个可以让 JavaScript 运行在浏览器之外的平台。它实现了诸如文件系统、模块、包、操作系统 API、网络通信等 Core JavaScript 没有或者不完善的功能。历史上将 JavaScript移植到浏览器外的计划不止一个,但Node.js 是最出色的一个。
什么是v8引擎
V8 JavaScript 引擎是 Google 用于其 Chrome 浏览器的底层 JavaScript 引擎。很少有人考虑 JavaScript 在客户机上实际做了些什么?实际上,JavaScript 引擎负责解释并执行代码。Google 使用 V8 创建了一个用 C++ 编写的超快解释器,该解释器拥有另一个独特特征;您可以下载该引擎并将其嵌入任何 应用程序。V8 JavaScript 引擎并不仅限于在一个浏览器中运行。因此,Node 实际上会使用 Google 编写的 V8 JavaScript 引擎,并将其重建为可在服务器上使用。
Node.js的作用
Node 公开宣称的目标是 “旨在提供一种简单的构建可伸缩网络程序的方法”。我们来看一个简单的例子,在 Java™ 和 PHP 这类语言中,每个连接都会生成一个新线程,每个新线程可能需要 2 MB 的配套内存。在一个拥有 8 GB RAM 的系统上,理论上最大的并发连接数量是 4,000 个用户。随着您的客户群的增长,如果希望您的 Web 应用程序支持更多用户,那么,您必须添加更多服务器。所以在传统的后台开发中,整个 Web 应用程序架构(包括流量、处理器速度和内存速度)中的瓶颈是:服务器能够处理的并发连接的最大数量。这个不同的架构承载的并发数量是不一致的。
而Node的出现就是为了解决这个问题:更改连接到服务器的方式。在Node 声称它不允许使用锁,它不会直接阻塞 I/O 调用。Node在每个连接发射一个在 Node 引擎的进程中运行的事件,而不是为每个连接生成一个新的 OS 线程(并为其分配一些配套内存)。
Node.js能做什么
借用一句经典的描述Node.js的话:正如 JavaScript 为客户端而生,Node.js 为网络而生。
使用Node.js,你可以轻易的实现:
- 具有复杂逻辑的网站;
- 基于社交网络的大规模 Web 应用;
- Web Socket 服务器;
- TCP/UDP 套接字应用程序;
- 命令行工具;
- 交互式终端程序;
- 带有图形用户界面的本地应用程序;
- 单元测试工具;
- 客户端 JavaScript 编译器。
什么是事件驱动编程
在我们使用Java,PHP等语言实现编程的时候,我们面向对象编程是完美的编程设计,这使得他们对其他编程方法不屑一顾。却不知大名鼎鼎Node使用的却是事件驱动编程的思想。那什么是事件驱动编程。
事件驱动编程,为需要处理的事件编写相应的事件处理程序。代码在事件发生时执行。
为需要处理的事件编写相应的事件处理程序。要理解事件驱动和程序,就需要与非事件驱动的程序进行比较。实际上,现代的程序大多是事件驱动的,比如多线程的程序,肯定是事件驱动的。早期则存在许多非事件驱动的程序,这样的程序,在需要等待某个条件触发时,会不断地检查这个条件,直到条件满足,这是很浪费cpu时间的。而事件驱动的程序,则有机会释放cpu从而进入睡眠态(注意是有机会,当然程序也可自行决定不释放cpu),当事件触发时被操作系统唤醒,这样就能更加有效地使用cpu。
来看一张简单的事件驱动模型(uml):

事件驱动模型主要包含3个对象:事件源、事件和事件处理程序。
- 事件源:产生事件的地方(html元素)
- 事件:点击/鼠标操作/键盘操作等等
- 事件对象:当某个事件发生时,可能会产生一个事件对象,该时间对象会封装好该时间的信息,传递给事件处理程序
- 事件处理程序:响应用户事件的代码
其实我们使用的window系统也算得上是事件驱动了。我们来看一个简单的事例:监听鼠标点击事件,并能够显示鼠标点击的位置x,y。<html>
<head>
<script>
function test1(e){
window.alert("x="+e.clientX+"y="+e.clientY);
}
</script>
</head>
<body onmousedown="test1(event)">
</body>
</html>
Node.js运行原理分析
当我们搜索Node.js时,夺眶而出的关键字就是 “单线程,异步I/O,事件驱动”,应用程序的请求过程可以分为俩个部分:CPU运算和I/O读写,CPU计算速度通常远高于磁盘读写速度,这就导致CPU运算已经完成,但是不得不等待磁盘I/O任务完成之后再继续接下来的业务。
所以I/O才是应用程序的瓶颈所在,在I/O密集型业务中,假设请求需要100ms来完成,其中99ms化在I/O上。如果需要优化应用程序,让他能同时处理更多的请求,我们会采用多线程,同时开启100个、1000个线程来提高我们请求处理,当然这也是一种可观的方案。
但是由于一个CPU核心在一个时刻只能做一件事情,操作系统只能通过将CPU切分为时间片的方法,让线程可以较为均匀的使用CPU资源。但操作系统在内核切换线程的同时也要切换线程的上线文,当线程数量过多时,时间将会被消耗在上下文切换中。所以在大并发时,多线程结构还是无法做到强大的伸缩性。
那么是否可以另辟蹊径呢?!我们先来看看单线程,《深入浅出Node》一书提到 “单线程的最大好处,是不用像多线程编程那样处处在意状态的同步问题,这里没有死锁的存在,也没有线程上下文切换所带来的性能上的开销”,那么一个线程一次只能处理一个请求岂不是无稽之谈,先让我们看张图: 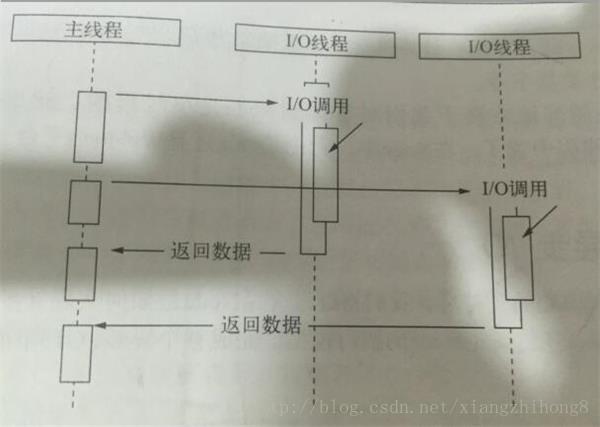
Node.js的单线程并不是真正的单线程,只是开启了单个线程进行业务处理(cpu的运算),同时开启了其他线程专门处理I/O。当一个指令到达主线程,主线程发现有I/O之后,直接把这个事件传给I/O线程,不会等待I/O结束后,再去处理下面的业务,而是拿到一个状态后立即往下走,这就是“单线程”、“异步I/O”。
I/O操作完之后呢?Node.js的I/O 处理完之后会有一个回调事件,这个事件会放在一个事件处理队列里头,在进程启动时node会创建一个类似于While(true)的循环,它的每一次轮询都会去查看是否有事件需要处理,是否有事件关联的回调函数需要处理,如果有就处理,然后加入下一个轮询,如果没有就退出进程,这就是所谓的“事件驱动”。这也从Node的角度解释了什么是”事件驱动”。
在node.js中,事件主要来源于网络请求,文件I/O等,根据事件的不同对观察者进行了分类,有文件I/O观察者,网络I/O观察者。事件驱动是一个典型的生产者/消费者模型,请求到达观察者那里,事件循环从观察者进行消费,主线程就可以马不停蹄的只关注业务不用再去进行I/O等待。
Node.js的简单实践
关于node的环境搭建这里就不说明了node入门。这里为了方便大家理解,我们写一个简单的登录实例。
这里为了方便前端小白的理解,新增一个小节,如何使用Node搭建一个新的项目。
## 使用Node创建项目
安装Express
npm install -g express
npm install -g express-generator
新建项目
express -t ejs newsproject
按照提示进入项目目录,运行npm安装
cd newsprojec
npm install
运行项目
node app.js
浏览器访问:http://127.0.0.1:3000/即可见nodejs站点页面即可。
接下来我们写一个简单的例子,来看一下效果图: 
整个目录如下:
根目录--------------
|-package.json
|-test.js
|-public
|-main.html
|-next.html
整个目录包含三个文件,test.js(作为控制文件)、main.html和next.html作为页面的显示文件。
来看一下代码:
test.js(作为控制文件)
// file name :test.js
var express = require('express');
var app = express();
var bodyParse = require('body-parser')
var cookieParser = require('cookie-parser') ;
app.use(cookieParser()) ;
app.use(bodyParse.urlencoded({extended:false})) ; // 处理根目录的get请求
app.get('/',function(req,res){
res.sendfile('public/main.html') ;
console.log('main page is required ');
}) ; // 处理/login的get请求
app.get('/add', function (req,res) {
res.sendfile('public/add.html') ;
console.log('add page is required ') ;
}) ; // 处理/login的post请求
app.post('/login',function(req,res){
name=req.body.name ;
pwd=req.body.pwd ;
console.log(name+'--'+pwd) ;
res.status(200).send(name+'--'+pwd) ;
}); // 监听3000端口
var server=app.listen(3000) ;
main.html的代码
<html>
<link rel="stylesheet" type="text/css" href="http://fonts.useso.com/css?family=Tangerine|Inconsolata|Droid+Sans">
<style>
div#test{
font-family: 'Tangerine',serif;
font-size: 48px;
}
p#link1{
font-family: 'Tangerine',serif;
}
</style>
<script src="//cdn.bootcss.com/jquery/2.2.1/jquery.min.js"></script>
</head>
<body>
<div id="test">
<h1>Main Page</h1>
</div>
<p>Register & Login</p>
<form action="test.jsp" method="post">
账号 :
<input type="text" id="name" />
<br/><br/>
密码 :
<input type="text" id="pwd" />
<br/><br/>
     
<div><a href="/add" id="add">EXTRA</a></div>
<input type="button" value="Submit" id="x">
</form>
</body>
<script type="text/javascript">
var after_login=function(data,status){
if (status=='success'){
alert(data+'--'+status) ;
}
else alert('login refused') ;
}
$(document).ready(function(){
$("#x").click(function(){
var name = $("#name").val() ;
var pwd = $("#pwd").val() ;
$.post('http://127.0.0.1:3000/login',
{
name : name ,
pwd : pwd
},
// function(data,status){
// alert(data+'--'+status) ;
// }
after_login
);
// $.get('add',function(data,status){
// document.write(data) ;
// }) ;
});
});
</script>
</html>
next.html的代码
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>第二页面</title>
</head>
<body>
<h1>This is an additional web page</h1>
<p>just for test</p>
</body>
</html>
本文摘自:https://blog.csdn.net/xiangzhihong8/article/details/53954600
原创作者:xiangzhihong8
node.js基本工作原理及流程的更多相关文章
- Linux可插拔认证模块(PAM)的配置文件、工作原理与流程
PAM的配置文件: 我们注意到,配置文件也放在了在应用接口层中,他与PAM API配合使用,从而达到了在应用中灵活插入所需鉴别模块的目的.他的作用主要是为应用选定具体的鉴别模块,模块间的组合以及规定模 ...
- 深入研究Node.js的底层原理和高级使用
深入研究Node.js的底层原理和高级使用
- Java 详解 JVM 工作原理和流程
Java 详解 JVM 工作原理和流程 作为一名Java使用者,掌握JVM的体系结构也是必须的.说起Java,人们首先想到的是Java编程语言,然而事实上,Java是一种技术,它由四方面组成:Java ...
- FastDFS tracker storage 的工作原理及流程
FastDFS tracker storage 的工作原理及流程 2013 年 3 月 11 日 – 09:22 | 1,409 views | 收藏 (No Ratings Yet) FastDF ...
- ARKit从入门到精通(2)-ARKit工作原理及流程介绍
转载:http://blog.csdn.net/u013263917/article/details/73038519 1.1-写在前面的话 1.2-ARKit与SceneKit的关系 1.3-ARK ...
- 第四次作业 描述HDFS体系结构、工作原理与流程
1.用自己的图,描述HDFS体系结构.工作原理与流程. 读数据的流程 2.伪分布式安装Hadoop.
- Node.js异步IO原理剖析
为什么要异步I/O? 从用户体验角度讲,异步IO可以消除UI阻塞,快速响应资源 JavaScript是单线程的,它与UI渲染共用一个线程.所以在JavaScript执行的时候,UI渲染将处于停顿的状态 ...
- “Ceph浅析”系列之五——Ceph的工作原理及流程
本文将对Ceph的工作原理和若干关键工作流程进行扼要介绍.如前所述,由于Ceph的功能实现本质上依托于RADOS,因而,此处的介绍事实上也是针对RADOS进行.对于上层的部分,特别是RADOS GW和 ...
- SSH三大框架的工作原理及流程
Hibernate工作原理及为什么要用? 原理:1.通过Configuration().configure();读取并解析hibernate.cfg.xml配置文件2.由hibernate.cfg.x ...
随机推荐
- TCP/IP详解读书笔记:概述
分层 分层是一种很通用的架构模式.通过分层,可以把一个系统分解成多个层,每个层专注于各自的功能,并提供接口给上面的层调用.上面的层不需要了解调用层的详细实现,只依赖于其接口,这就给维护带来了很大的好处 ...
- hdu4106 区间k覆盖问题(连续m个数,最多选k个数) 最小费用最大流 建图巧妙
/** 题目:hdu4106 区间k覆盖问题(连续m个数,最多选k个数) 最小费用最大流 建图巧妙 链接:http://acm.hdu.edu.cn/showproblem.php?pid=4106 ...
- 【黑马Android】(04)数据库的创建和sql语句增删改查/LinearLayout展示列表数据/ListView的使用和BaseAdater/内容提供者创建
数据库的创建和sql语句增删改查 1. 载入驱动. 2. 连接数据库. 3. 操作数据库. 创建表: create table person( _id integer primary key, nam ...
- impala+kudu
[impala建表]kudu的表必须有主键,作为分区的字段需排在其他字段前面. [range分区](不推荐)CREATE TABLE KUDU_WATER_HISTORY ( id STRING, y ...
- RTP时间戳
http://xingyunbaijunwei.blog.163.com/blog/static/7653806720126121014111/ ——————————————————————————— ...
- php 判断是否在微信浏览器中打开
<?php $a=false; $b=$_SERVER['HTTP_USER_AGENT']; if(strpos($b,"MicroMessenger")===false) ...
- .net 编译原理
这听起来像是个非常高大上的名字,上学的时候我们学过的编译原理或者编译技术实际上是在讲如何将高级程序语言如C++编译为计算机可以理解的汇编语言,这里说的编译原理只是想说明在.NET的世界里编译这件事儿和 ...
- struts2中,Action通过什么方式获得用户从页面输入的数据,又是通过什么方式把其自身的数据传给视图的?
struts2中,Action通过什么方式获得用户从页面输入的数据,又是通过什么方式把其自身的数据传给视图的? 解答: 1)可以直接通过与表单元素相同名称的数据成员(需要存在符合命名规范set和get ...
- Web监听器导图详解
监听器是JAVA Web开发中很重要的内容,其中涉及到的知识,可以参考下面导图: Web监听器 1 什么是web监听器? web监听器是一种Servlet中的特殊的类,它们能帮助开发者监听web中的特 ...
- android RadioGroup实现单选以及默认选中
代码下载链接:http://download.csdn.net/detail/a123demi/7511835 本文将通过radiogroup和radiobutton实现组内信息的单选, 当中radi ...