大数据框架-spark
相关详细说明:https://www.csdn.net/article/2015-07-10/2825184
RDD:弹性分布式数据集。
Operation:Transformation 和Action,一个返回RDD,一个返回值。
Lineage:RDD之间的依赖关系,如何演变过来。
Partition:RDD分区,按block切分
narrow dependency(窄依赖) :父RDD全进入子RDD
wide dependency(宽依赖)
Application[一个spark-submit提交的程序]
Job[一个计算序列的最终结果Action操作,多个RDD以及作用于RDD之上的Operation]
stage[计算序列的中间结果]
[划分stage 的重要依据是有无shuflle (数据重组)发生,由DAGSchedule进行划分,Shuffle在Spark中是把父RDD中KV对按照Key重新分区,得到一个新的子RDD,包括这几个操作reduceByKey、groupByKey、sortByKey、countByKey、join、cogroup]
Task[每个partition在一个executor上的Operation是一个Task,即一个thread]
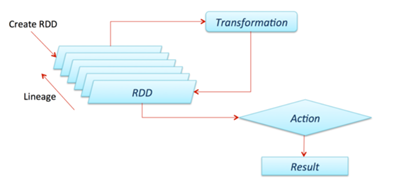
Spark(standalone模式)基本组件;
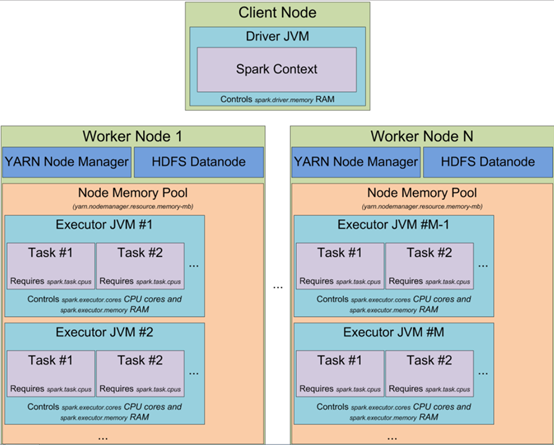
master(RM):负责资源管理,sparkonYarn模式下就是RM
worker(NM):一个worker可以有多个executor
executor(Container,可以看作资源集合、也可看作task的执行池,一个JVM进程):
当以YARN模式启动spark集群时,可以指定
executors的数量(-num-executors 或者 spark.executor.instances 参数)
executor 固有的内存大小(-executor-memory 或者 spark.executor.memory),executor使用的cpu核数(-executor-cores 或者 spark.executor.cores)
executor分配给每个task的core的数量(spark.task.cpus)
driver 上使用的内存(-driver-memory 或者 spark.driver.memory)。
driver(AppMaster):申请资源并监控任务执行状态。通过DAGScheduler划分形成TaskSet,将具体Task交给对应worker中的executor线程池执行。
大数据框架-spark的更多相关文章
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
- 老李分享:大数据框架Hadoop和Spark的异同
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨询qq:908821478,咨询电话010-845052 ...
- [转载] 2 分钟读懂大数据框架 Hadoop 和 Spark 的异同
转载自https://www.oschina.net/news/73939/hadoop-spark-%20difference 谈到大数据,相信大家对Hadoop和Apache Spark这两个名字 ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink
转自:https://www.cnblogs.com/reed/p/7730329.html 今天看到一篇讲得比较清晰的框架对比,这几个框架的选择对于初学分布式运算的人来说确实有点迷茫,相信看完这篇文 ...
- 2分钟读懂大数据框架Hadoop和Spark的异同
转自:https://www.cnblogs.com/reed/p/7730313.html 谈到大数据,相信大家对Hadoop和Apache Spark这两个名字并不陌生.但我们往往对它们的理解只是 ...
- 大数据框架:Spark vs Hadoop vs Storm
大数据时代,TB级甚至PB级数据已经超过单机尺度的数据处理,分布式处理系统应运而生. 知识预热 「专治不明觉厉」之“大数据”: 大数据生态圈及其技术栈: 关于大数据的四大特征(4V) 海量的数据规模( ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink——flink支持SQL,待看
简介 大数据是收集.整理.处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称.虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性.规模,以及价值在最近几年才 ...
- 【互动问答分享】第13期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第13期互动问答分享] Q1:tachyon+spark框架现在有很多大公司在使用吧? Yahoo!已经在长期大规模使用: 国内也有 ...
- 【互动问答分享】第10期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第10期互动问答分享] Q1:Spark on Yarn的运行方式是什么? Spark on Yarn的运行方式有两种:Client ...
随机推荐
- Java测试工具使用(1)--Junit
在进行测试之前需要导入junit的两个包,分别是 junit:4.12;hamcrest-core:1.1 1.基本测试标签 @Test.@Before.@After 2.组测试 有时候多个测试文件, ...
- Effective C++ .07 virtual析构函数的提供
主要讲了, 1. virtual析构函数的作用与调用顺序 2. 使用时机,并不是使用了继承就要把基类的析构函数变为虚函数(virtual),只有当用于多态目的时才进行一个virtual析构函数的定义. ...
- div居中方式
1. position: absolute; top:50%:left: 50%; margin-top: -高度的一半; margin-left: -宽度的一半(此方法适用于固定宽高的元素) 注: ...
- as3.2版本中中jar生成方法
lintOptions { abortOnError false } task makeJar(type: Copy) { //删除存在的 delete 'build/libs/myjar.jar' ...
- python 小词云
# Author:Alex.wang# Date:2017.06.02# Version:3.6.0 import matplotlib.pyplot as pltfrom wordcloud imp ...
- Java程序中解决数据库超时与死锁
Java程序中解决数据库超时与死锁 2011-06-07 11:09 佚名 帮考网 字号:T | T Java程序中解决数据库超时与死锁,每个使用关系型数据库的程序都可能遇到数据死锁或不可用的情况 ...
- ubuntu 安装nodejs和git
1.安装curl sudo apt-get install curl 2.安装nodejs 和 npm curl -sL https://deb.nodesource.com/setup_8.x | ...
- C/C++内存泄露检测
以下测试基于的gcc版本: gcc (Ubuntu 4.8.4-2ubuntu1~14.04) 4.8.4Copyright (C) 2013 Free Software Foundation, In ...
- spring core
https://docs.spring.io/spring/docs/5.1.3.RELEASE/spring-framework-reference/core.html#beans
- ZT 段祺瑞终生忏悔枪杀学生?
段祺瑞终生忏悔枪杀学生?http://cache.baiducontent.com/c?m=9f65cb4a8c8507ed4fece76310528c315c4380146080955468d4e4 ...