使用python进行新浪微博粉丝爬虫
由于最近没事在学python,正好最近也想趴下新浪微博上边的一些数据,在这里主要爬去的是一个人的粉丝具体信息(微博昵称,个人介绍,地址,通过什么方式进行关注),所以就学以致用,通过python来爬去微博上边的数据。
首先先说下环境啊,使用的是python3.5,然后使用的框架有:
requests:用来获取html页面。
BeautifulSoup:用来进行html的解析,是一个在python爬虫中非常好用的一个工具,并且有中文的说明文档,链接是:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html。可以看其中具体的一些函数的使用的方法。
通过这两个,则就可以实现我们想要实现的功能了。
然后第二步,则是我们需要模拟微博进行登录,因为你会发现,如果你不登录,是无法看一个人的具体的粉丝信息的,因此我们需要自己登录下新浪微博,然后通过调试工具,把cookie复制出来,这样才能够进行爬虫。,怎么获取cookie,在这进行一个简单的介绍,登陆后看到个人主页后,打开开发者工具,然后选择network:
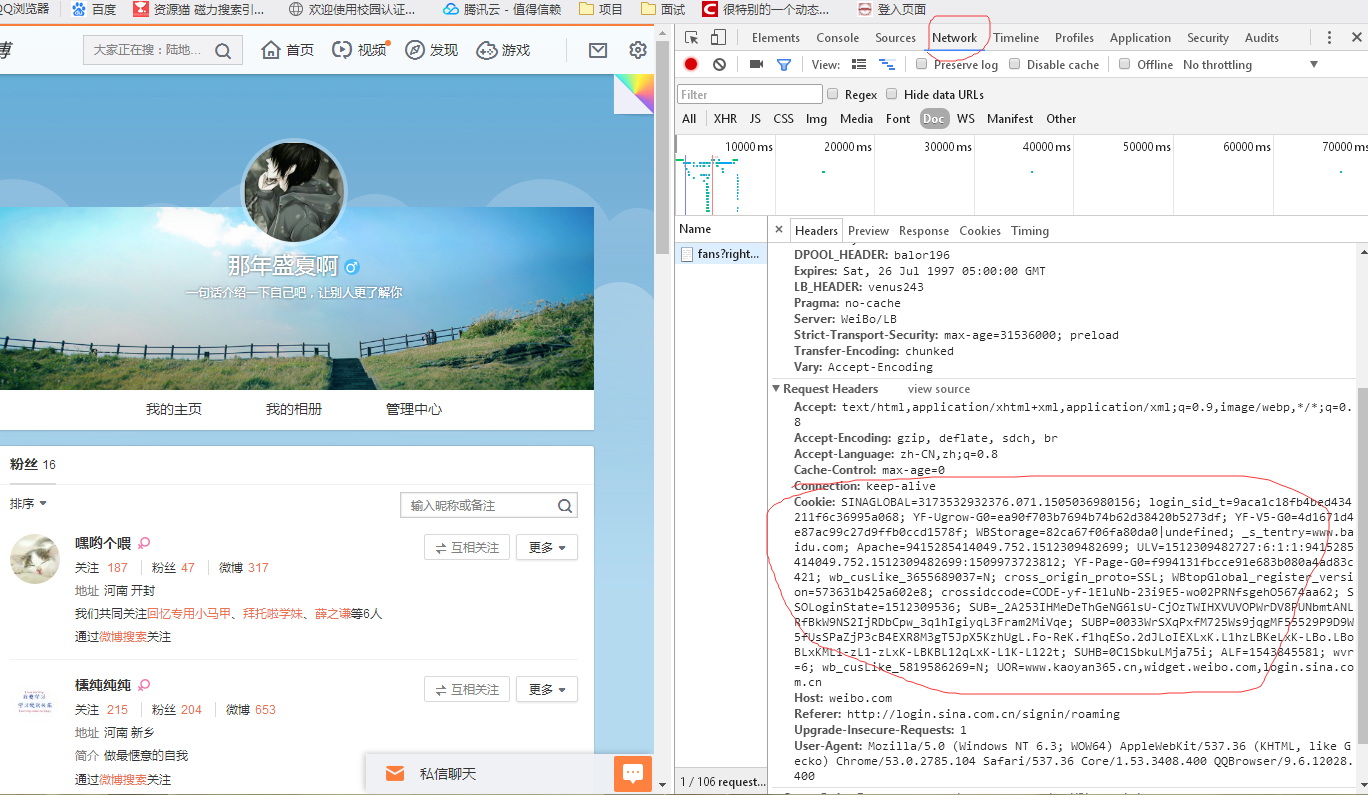
然后复制下这个cookie,在爬虫中需要用到,接下来就上代码了:
主程序类代码:
import requests
from html.parser import HTMLParser
import person
from bs4 import BeautifulSoup
import json
#获取的cookie值存放在这
myHeader = {"Cookie":"SINAGLOBAL=1151648924265.729.1510207774298; YF-V5-G0=a9b587b1791ab233f24db4e09dad383c; login_sid_t=663888f6033b6f4a8f5fa48b26d9eb17; YF-Ugrow-G0=ea90f703b7694b74b62d38420b5273df; _s_tentry=passport.weibo.com; Apache=9283625770163.1.1512087277478; ULV=1512087277483:2:1:1:9283625770163.1.1512087277478:1510207774304; SSOLoginState=1512087292; wvr=6; YF-Page-G0=451b3eb7a5a4008f8b81de1fcc8cf90e; cross_origin_proto=SSL; WBStorage=82ca67f06fa80da0|undefined; crossidccode=CODE-gz-1ElEPq-16RrfZ-qpysbLqGTWJetzH095150; SCF=AnQFFpBKBne2YCQtu52G1zEuEpkY1WI_QdgCdIs-ANt1_wzGQ0_VgvzYW7PLnswMwwJgI9T3YeRDGsWhfOwoLBs.; SUB=_2A253IOm1DeThGeNG6lsU-CjOzTWIHXVUVFx9rDV8PUNbmtBeLWTSkW9NS2IjRFgpnHs1R3f_H3nB67BbC--9b_Hb; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5fUsSPaZjP3cB4EXR8M3gT5JpX5KzhUgL.Fo-ReK.f1hqESo.2dJLoIEXLxK.L1hzLBKeLxK-LBo.LBoBLxKML1-zL1-zLxK-LBKBL12qLxK-L1K-L122t; SUHB=0wnlry4ys0tunb; ALF=1543884132; wb_cusLike_5819586269=N; UOR=,,login.sina.com.cn"}
#要爬去的账号的粉丝列表页面的地址
r = requests.get('https://weibo.com/p/1005051678105910/follow?relate=fans&from=100505&wvr=6&mod=headfans¤t=fans#place',headers=myHeader)
f = open("test.html", "w", encoding="UTF-8")
parser = HTMLParser()
parser.feed(r.text)
htmlStr = r.text # 通过script来切割后边的几个通过js来显示的json数组,通过观看源代码
fansStr = htmlStr.split("</script>")
#因为在测试的时候,发现微博每一次返回的dom的顺序不一样,粉丝列表的dom和一个其他内容的dom的位置一直交替,所以在这加了一个判断
tmpJson = fansStr[-2][17:-1] if fansStr[-2][17:-1].__len__()>fansStr[-3][17:-1].__len__() else fansStr[-3][17:-1]
dict = json.loads(tmpJson) soup = BeautifulSoup(dict['html'], 'html') soup.prettify()
f.write(soup.prettify()) for divTag in soup.find_all('div'):
if divTag['class'] == ["follow_inner"]:
followTag = divTag if locals().get("followTag"):
for personTag in followTag.find_all('dl'):
p = person.person(personTag)
print(p.__dict__)
person类代码:
在这中间进行主要的解析
from bs4 import BeautifulSoup #具体解析在这
class person(object):
def __init__(self, personTag = None):
self.analysis(personTag)
def analysis(self,personTag):
self.analysisName(personTag)
self.analysisFollowAndFansNumber(personTag)
self.analysisCity(personTag)
self.analysisIntroduce(personTag)
self.analysisFollowWay(personTag)
self.analysisID(personTag) def analysisName(self,personTag):
self.name = personTag.div.a.string
def analysisFollowAndFansNumber(self,personTag):
for divTag in personTag.find_all('div'):
if divTag['class'] == ["info_connect"]:
infoTag = divTag
if locals().get("infoTag"):
self.followNumber = infoTag.find_all('span')[0].em.string
self.fansNumber = infoTag.find_all('span')[1].em.a.string
self.assay = infoTag.find_all('span')[2].em.a.string def analysisCity(self,personTag):
for divTag in personTag.find_all('div'):
if divTag['class'] == ['info_add']:
addressTag = divTag
if locals().get('addressTag'):
self.address = addressTag.span.string def analysisIntroduce(self,personTag):
for divTag in personTag.find_all('div'):
if divTag['class'] == ['info_intro']:
introduceTag = divTag
if locals().get('introduceTag'):
self.introduce = introduceTag.span.string def analysisFollowWay(self,personTag):
for divTag in personTag.find_all('div'):
if divTag['class'] == ['info_from']:
fromTag = divTag
if locals().get('fromTag'):
self.fromInfo = fromTag.a.string def analysisID(self,personTag):
personRel = personTag.dt.a['href']
self.id = personRel[personRel.find('=')+1:-5]+personRel[3:personRel.find('?')]
在这里爬去的是孙俪下边的第一页列表的微博的粉丝,结果如下截图:

其实这个相对还是比较简单的,主要比较麻烦的是需要看新浪的html的源代码,需要了解其显示的规律,然后使用beautiful soup进行解析节点,获取数据。
使用python进行新浪微博粉丝爬虫的更多相关文章
- Python初学者之网络爬虫(二)
声明:本文内容和涉及到的代码仅限于个人学习,任何人不得作为商业用途.转载请附上此文章地址 本篇文章Python初学者之网络爬虫的继续,最新代码已提交到https://github.com/octans ...
- 【Python】:简单爬虫作业
使用Python编写的图片爬虫作业: #coding=utf-8 import urllib import re def getPage(url): #urllib.urlopen(url[, dat ...
- 使用python/casperjs编写终极爬虫-客户端App的抓取-ZOL技术频道
使用python/casperjs编写终极爬虫-客户端App的抓取-ZOL技术频道 使用python/casperjs编写终极爬虫-客户端App的抓取
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
前面一直强调Python运用到网络爬虫方面很有效,这篇文章也是结合学习的Python视频知识及我研究生数据挖掘方向的知识.从而简介下Python是怎样爬去网络数据的,文章知识很easy ...
- 洗礼灵魂,修炼python(69)--爬虫篇—番外篇之feedparser模块
feedparser模块 1.简介 feedparser是一个Python的Feed解析库,可以处理RSS ,CDF,Atom .使用它我们可从任何 RSS 或 Atom 订阅源得到标题.链接和文章的 ...
- 洗礼灵魂,修炼python(50)--爬虫篇—基础认识
爬虫 1.什么是爬虫 爬虫就是昆虫一类的其中一个爬行物种,擅长爬行. 哈哈,开玩笑,在编程里,爬虫其实全名叫网络爬虫,网络爬虫,又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者 ...
- 使用Python + Selenium打造浏览器爬虫
Selenium 是一款强大的基于浏览器的开源自动化测试工具,最初由 Jason Huggins 于 2004 年在 ThoughtWorks 发起,它提供了一套简单易用的 API,模拟浏览器的各种操 ...
- Python 利用Python编写简单网络爬虫实例3
利用Python编写简单网络爬虫实例3 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://bbs.51testing. ...
- Python 利用Python编写简单网络爬虫实例2
利用Python编写简单网络爬虫实例2 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://www.51testing. ...
随机推荐
- 2017.12.12 架构探险-第一章-从一个简单的web应用开始
参考来自:<架构探险>黄勇 著 1 使用IDEA搭建MAVEN项目 1.1 搭建java项目 (1)创建java项目 为了整个书籍的项目,我创建了一个工程,在这个工程里创建了每个章节的mo ...
- DirectX游戏开发——从一个小游戏開始
本系列文章由birdlove1987编写,转载请注明出处. 文章链接: http://blog.csdn.net/zhurui_idea/article/details/26364129 写在前面:自 ...
- SSMybatis整合(二) -- 加入SpringMVC进行多表级联操作
---上节课我们讲了Mybatis的单表增删改查,关于代码我注释的比较详细,我相信初学的小伙伴还是多少能有一些收获的. - 第一集传送门:http://blog.csdn.net/jacxuan/ar ...
- 【ACM】How many prime numbers
http://acm.hdu.edu.cn/game/entry/problem/show.php?chapterid=2§ionid=1&problemid=2 #inclu ...
- iOS 使用 AVCaptureVideoDataOutputSampleBufferDelegate获取实时拍照的视频流
iOS 使用 AVCaptureVideoDataOutputSampleBufferDelegate获取实时拍照的视频流 可用于实时视频聊天 实时视频远程监控 #import <AVFound ...
- 算法笔记_065:分治法求逆序对(Java)
目录 1 问题描述 2 解决方案 2.1 蛮力法 2.2 分治法(归并排序) 1 问题描述 给定一个随机数数组,求取这个数组中的逆序对总个数.要求时间效率尽可能高. 那么,何为逆序对? 引用自百度 ...
- 算法笔记_060:蓝桥杯练习 出现次数最多的整数(Java)
目录 1 问题描述 2 解决方案 1 问题描述 问题描述 编写一个程序,读入一组整数,这组整数是按照从小到大的顺序排列的,它们的个数N也是由用户输入的,最多不会超过20.然后程序将对这个数组进行统 ...
- JavaScript | 数据属性与访问器属性
属性类型 数据属性 - 包含一个数据值的位置,可以读取和写入值 [writable] 是否能修改属性的值 true [enumerable] 是否通过for in 循环返回属性(是否可以被枚举) tr ...
- (转)职责链设计模式(Chain of Responsibility)
Chain of Responsibility定义Chain of Responsibility(CoR) 是用一系列类(classes)试图处理一个请求request,这些类之间是一个松散的耦合,唯 ...
- Linux下如何修改root密码以及找回root密码
Linux下修改root密码方法 以root身份登陆,执行: passwd 用户名 然后根据提示,输入新密码,再次输入新密码,系统会提示成功修改密码. 具体示例如下: [root@www ~]# pa ...