Flink的部署
Flink的部署
环境准备:windows7系统,本地连接。如果打开更改适配器设置后没有本地连接,可以通过驱动精灵等软件安装网卡驱动。为了使部署在虚拟机上的服务器可以与物理机进行连通,必须使物理机的网卡和虚拟机上服务器的网卡在同一个网段上,在此我们规定一个网段192.168.0.*为标准,我的物理机的IP地址是192.168.0.99。根据以下的附图对网络进行配置。
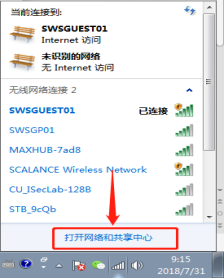
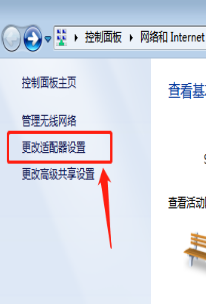

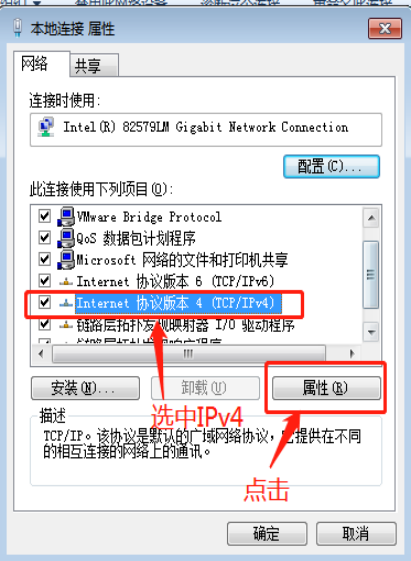
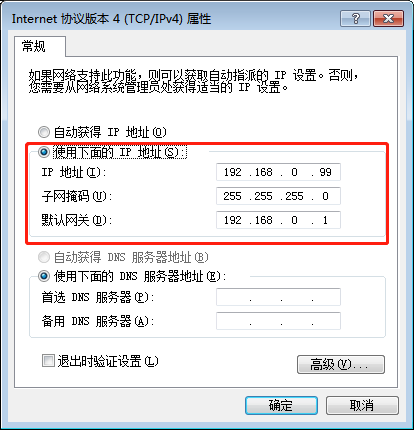
1.windows下安装VMware并且在VMware上新建三台虚拟机,分别在这三台虚拟机上安装Ubuntu16.04 Server版系统,虚拟机上的网络设置采用桥接模式。
2.使用命令vim /etc/network/interfaces对文件interfaces中的网卡信息进行修改。

如下附图为服务器上所要配置的网卡的信息,我的服务器的IP地址为192.168.0.103
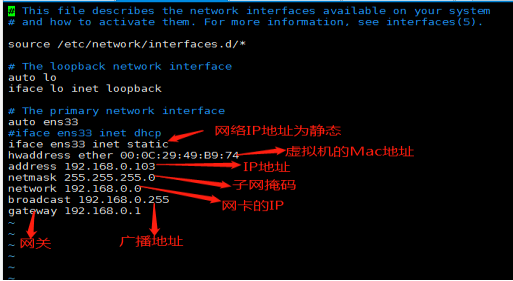
按照同样的方法配置另外两台服务器,它们的IP地址分别为192.168.0.104,192.168.0.105
测试连通性:在一台服务器上使用命令ping 192.168.0.104去ping另外一台服务器,产生如下附图的效果即为拼接成功。三台服务器相互ping都可以拼接成功。

服务器上的环境:为三台Ubuntu服务器配置Java环境,jdk的版本要求为1.8或者更高,本实例的flink集群有三个节点,一主两从。Flink 有三种部署模式,分别是 Local、Standalone Cluster 和 Yarn Cluster。对于 Local 模式来说,JobManager 和 TaskManager 共用一个 JVM,Local模式的部署请点击http://www.jianshu.com/p/26c9ef86fb19。如果要验证一个简单的应用,Local 模式是最方便的。实际应用中大多使用 Standalone 或者 Yarn Cluster。
模式一:单节点的Local模式
1.在http://flink.apache.org/downloads.html网站上下载需要的flink版本,我下载的如下附图所示。


2.将tar包解压后放置到/opt/data下,进入flink目录,使用命令bin/start-local.sh运行flink,根据你的IP地址localhost:8081,进入flink的前端界面如下附图所示即为启动flink成功。

模式二:多节点的Standalone模式
1.在http://archive.apache.org/dist/flink/flink-1.3.2/上下载flink的版本,我下载的如下图附图所示的版本的tar包。

2.使用命令tar -zxvf flink-1.3.2-bin-hadoop26-scala_2.11.tgz对flink的tar包进行解压,并将解压后的文件改名为flink且将其安放到/usr/local/java/目录下。(flink的安放目录根据每个人的不同情况可进行自定义)
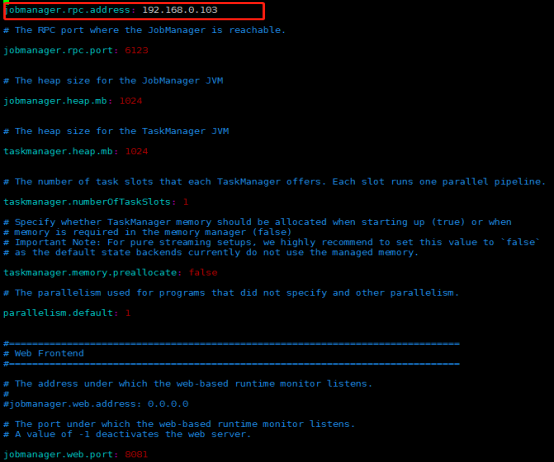
在flink目录下,使用命令vim conf/flink-conf.yaml,增加master节点的IP地址,修改jobmanager.rpc.address:,其IP为master的IP地址。在fink目录下使用命令vim conf/slaves,增加worker节点的IP地址。
(根据如下附图所示进行修改,其他的两台服务器使用相同的方法进行配置,具体配置可在Apache的官网上进行查看,官网的网址如下所示https://ci.apache.org/projects/flink/flink-docs-release-1.0/setup/config.html#full-reference)
注释:
Jobmanager可用内存(jobmanager.heap.mb)
taskmanager可用内存(taskmanager.heap.mb)
每个机器可用cpu数量(taskmanager.numberOfTaskSlots)
集群中的总cpu数量(parallelism.default)
节点临时目录(taskmanager.tmp.dirs)
3.启动flink集群。
下面的脚本将会在本机启动一个jobmanager节点,然后通过SSH连接到slaves文件中的所有worker节点,在worker节点上面启动taskmanager。现在flink启动并且运行。在本地运行的jobmanager现在将会通过配置的RPC端口接收任务。
确保在master节点的终端下同时进入flink目录:使用命令bin/start-cluster.sh启动flink集群,使用命令bin/stop-cluster.sh停止flink集群。
Flink的部署的更多相关文章
- Flink安装部署
官网:https://ci.apache.org/projects/flink/flink-docs-release-1.7/ops/deployment/cluster_setup.html cd ...
- Apache Flink 开发环境搭建和应用的配置、部署及运行
https://mp.weixin.qq.com/s/noD2Jv6m-somEMtjWTJh3w 本文是根据 Apache Flink 系列直播课程整理而成,由阿里巴巴高级开发工程师沙晟阳分享,主要 ...
- 新一代大数据处理引擎 Apache Flink
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/index.html 大数据计算引擎的发展 这几年大数据的飞速发 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)
本文由 网易云发布. 1.Flink架构及特性分析 Flink是个相当早的项目,开始于2008年,但只在最近才得到注意.Flink是原生的流处理系统,提供high level的API.Flink也提 ...
- Flink从入门到放弃(入门篇1)-Flink是什么
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Apache Flink:特性、概念、组件栈、架构及原理分析
2016-04-30 22:24:39 Yanjun Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink Runtim ...
- Apache Flink系列(1)-概述
一.设计思想及介绍 基本思想:“一切数据都是流,批是流的特例” 1.Micro Batching 模式 在Micro-Batching模式的架构实现上就有一个自然流数据流入系统进行攒批的过程,这在一定 ...
- Flink(二)CentOS7.5搭建Flink1.6.1分布式集群
一. Flink的下载 安装包下载地址:http://flink.apache.org/downloads.html ,选择对应Hadoop的Flink版本下载 [admin@node21 soft ...
- 什么是Apache Flink
大数据计算引擎的发展 这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop.Storm,以及后来的 Spark,他们都有着各自专注的应用场景.Spark 掀开了内存计算的先河, ...
随机推荐
- java操作svn【svnkit】实操
SVNKit中怎样使用不同的仓库访问协议? 当你下载了最新版的SVNKit二进制文件并且准备使用它时,一个问题出现了,要创建一个库需要做哪些初始化的步骤?直接与Subversion仓库交互已经在低级层 ...
- 【Leetcode】【Medium】Combination Sum II
Given a collection of candidate numbers (C) and a target number (T), find all unique combinations in ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- for循环里面的break;和continue;语句
for循环里面的break;和continue;语句 break语句 哇,我已经找到我要的答案了,我不需要进行更多的循环了! 比如,寻找第一个能被5整除的数: for循环中,如果遇见了break语句, ...
- IntelliJ IDEA下"Cannot resolve symbol 'log'"的解决方法
转自:https://my.oschina.net/greatqing/blog/703989 最近接手了一个Maven项目,IDE使用的是IntelliJ IDEA,导入后可以编译运行.但是输出日志 ...
- Java集合工具类
import java.util.ArrayList; import java.util.Collection; import java.util.List; import java.util.Map ...
- ZT 苍天助曹不助汉哪
诸葛亮能夜观星象,但为什么在上方谷一役中,孔明没有测出突如其来的大雨,却高呼“苍天助曹不助汉哪”断送了自己的性命,这是为什么 谋事在人,成事在天. 雁过留影 3级 2011-04-18 天命不可违 ...
- 深入理解JNI 邓平凡
深入理解JNI 邓凡平 1)使用的时候 :加载libmedia_jni.so 并接着调用JNI_Onload->register_android_media_MediaScanner动态注册JN ...
- php获取视频长度,php.ini配置
php获取视频长度 $long = exec("ffmpeg -i video.mp4 2>&1 | grep 'Duration' | cut -d ' ' -f 4 | s ...
- JavaScript中如何判断两变量是否“相等”?
1 为什么要判断? 可能有些同学看到这个标题就会产生疑惑,为什么我们要判断JavaScript中的两个变量是否相等,JavaScript不是已经提供了双等号“==”以及三等号“===”给我们使用了吗? ...