wf效能分析
听从了老师的建议我请教了其他的同学,修改了代码实现了功能四,以下是我的效能测试:
1.采用ptime.exe测试的3次截图
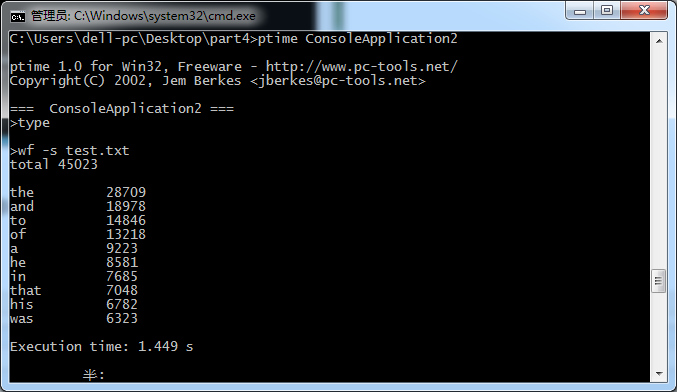
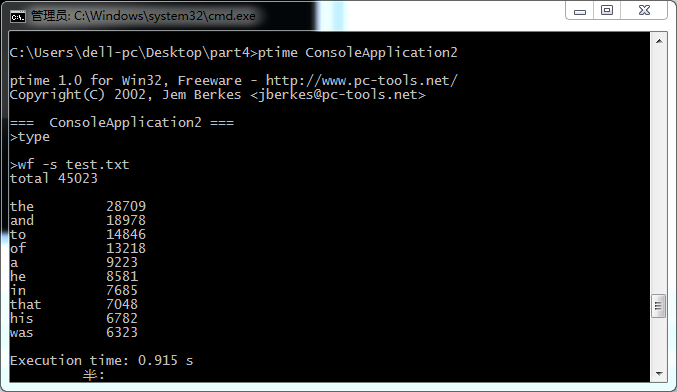
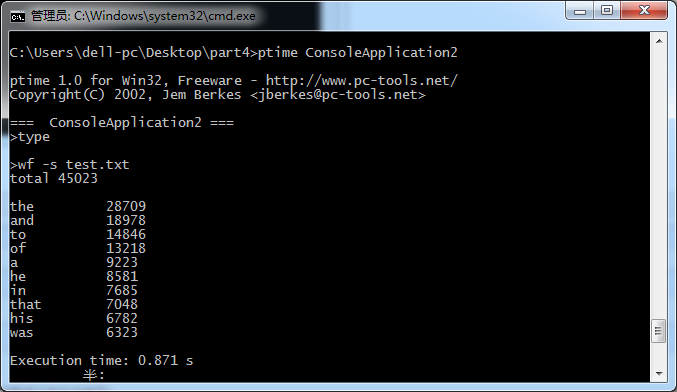
可以看到的是三次执行时间分别为:1.449秒;0.915秒;0.871秒,取平均值为1.078秒
源码地址:https://coding.net/u/yuanyue2017102885/p/wf-part420170926/git
2.采用vs进行效能测试(vs2008无此功能)
要求1 给出你猜测程序的瓶颈。你认为优化会有最佳效果,或者在上周在此处做过优化 (或考虑到优化,因此更差的代码没有写出) 。
答:我认为如果要再次提升运行速度,应该对哈希表处有所改进;看了其他同学的作业,我发现我的程序运行的算是比较快的,原因可能是因为我直接把要测试文档的路径写在了程序里面,但是这样做的缺点就是路径明确,如果其他同学在他们的环境下测试有可能出现找不到文件的情况。
要求2 通过 profile 找出程序的瓶颈。给出程序运行中最花费时间的3个函数(或代码片断)。要求包括截图。 (5分)
答:在程序运行中最花费时间的是main函数(因为我的程序中就一个函数。。。)最耗费时间的应该是哈希表部分,代码片段如下:
static void Main(string[] args)
{
StreamReader ioInput = null;
ioInput = new StreamReader(Console.OpenStandardInput());
string textFileName;
Console.Write(">type ");
textFileName = Console.ReadLine();
StreamReader sreader = new StreamReader(@"C:\Users\dell-pc\desktop\test2.txt");
string afile = sreader.ReadToEnd();
afile = afile.ToLower();//转换为小写字母
//将空格跟标点符号定义出来
char[] c = { ' ', ',', '.', '?', '!', ':', ';', '\'', '\"' };
//分隔char[c]后产生的数组
string[] S = afile.Split(c);
//建立哈希表
Hashtable ha = new Hashtable();
for (int i = ; i < S.Length; i++)
{
if (ha.ContainsKey(S[i]))
{
ha[S[i]] = (int)ha[S[i]] + ;
}
else
{
ha.Add(S[i], );
}
}
string[] arrKey = new string[ha.Count];//存键
int[] arrValue = new int[ha.Count];//存值
ha.Keys.CopyTo(arrKey, );
ha.Values.CopyTo(arrValue, );
Console.WriteLine();
Console.WriteLine(">wf -s test.txt");
Console.WriteLine("total " + ha.Count);
Console.WriteLine();
Array.Sort(arrValue, arrKey);//排序
int n = ;
for (int i = arrKey.Length - ; i >= ; i--)
{
if ((string)arrKey[i] != "")
{
if (n < )
{
//输出前10位多的单词,右对齐
Console.Write(arrKey[i].ToString().PadRight());
Console.WriteLine(arrValue[i].ToString());
n = n + ;
}
}
}
}
要求3 根据瓶颈,"尽力而为"地优化程序性能。 (5分)
答:我觉得自己的程序是比较简洁的,除了输入输出就是主要排序的哈希表部分了,每一条代码都有自己的功能而且我觉得已经无法压缩了。
要求4 再次 profile,给出在 要求1 中的最花费时间的3个函数此时的花费。要求包括截图。(2分)
答:在这篇博文的最开始已经附上了截图,我还求了个平均值1.078s。
要求5 程序运行时间。根据在教师的机器 (Windows8.1) 上运行的速度排名,分为3档。此题得分,第1档20分, 第2档10分,第3档5分。功能测试不能通过的,0分。(20分)
答:源码地址:https://coding.net/u/yuanyue2017102885/p/wf-part420170926/git
里面有一个program.cs的源码与consoleapplication2.exe的编译文件,它们是匹配的。
附加:考虑到我的程序是将原路径写在了代码里,这样老师在运行的时候肯定找不到原路径,这样我就没分了,所以我刚才对代码进行了一点修改,使得灵活性更高,但是在进行ptime测试的发现时间比刚才慢了好多,附上我改后的代码,coding.net里面的.cs文件跟.exe文件我也会重新上传,重新测的运行时间如下:
using System;
//using System.Collections.Generic;
//using System.Linq;
using System.Text;
using System.IO;
using System.Collections;
//using System.Text.RegularExpressions;
//using System.Diagnostics;
//using System.ComponentModel; namespace wf
{
class Program
{
static void Main(string[] args)
{
StreamReader ioInput = null;
ioInput = new StreamReader(Console.OpenStandardInput());
string textFileName;
Console.Write(">type ");
textFileName = Console.ReadLine();
string url = System.IO.Path.GetFullPath(textFileName+".txt");
StreamReader sreader = new StreamReader(url);
//StreamReader sreader = new StreamReader(@"C:\Users\dell-pc\desktop\test2.txt");
string afile = sreader.ReadToEnd();
afile = afile.ToLower();//转换为小写字母
//将空格跟标点符号定义出来
char[] c = { ' ', ',', '.', '?', '!', ':', ';', '\'', '\"' };
//分隔char[c]后产生的数组
string[] S = afile.Split(c);
//建立哈希表
Hashtable ha = new Hashtable();
for (int i = ; i < S.Length; i++)
{
if (ha.ContainsKey(S[i]))
{
ha[S[i]] = (int)ha[S[i]] + ;
}
else
{
ha.Add(S[i], );
}
}
string[] arrKey = new string[ha.Count];//存键
int[] arrValue = new int[ha.Count];//存值
ha.Keys.CopyTo(arrKey, );
ha.Values.CopyTo(arrValue, );
Console.WriteLine();
Console.WriteLine(">wf -s >" + textFileName + ".txt");
Console.WriteLine("total " + ha.Count);
Console.WriteLine();
Array.Sort(arrValue, arrKey);//排序
int n = ;
for (int i = arrKey.Length - ; i >= ; i--)
{
if ((string)arrKey[i] != "")
{
if (n < )
{
//输出前10位多的单词,右对齐
Console.Write(arrKey[i].ToString().PadRight());
Console.WriteLine(arrValue[i].ToString());
n = n + ;
}
}
}
}
}
}



删除了一些不必要的引用集,首测6秒多,我继续进行测试选取了其中速度比较快的3组测试数据,分别为:1.620秒;1.968秒;1.369秒。
wf效能分析的更多相关文章
- 《构建之法》教学笔记——Python中的效能分析与几个问题
<构建之法:现代软件工程>中第2章对效能分析进行了介绍,基于的工具是VSTS.由于我教授的学生中只有部分同学选修了C#,若采用书中例子讲解,学生可能理解起来比较困难.不过所有这些学生都学习 ...
- python实现四则运算和效能分析
代码github地址:https://github.com/yiduobaozhi/-1 PSP表格: 预测时间(分钟) planning 计划 15 Estimate 估计这个任务需要多少时间 10 ...
- python词频统计及其效能分析
1) 博客开头给出自己的基本信息,格式建议如下: 学号2017****7128 姓名:肖文秀 词频统计及其效能分析仓库:https://gitee.com/aichenxi/word_frequenc ...
- C#词频统计 效能分析
在邹老师的效能分析的建议下对上次写过的词频统计的程序进行分析改进. 效能分析:个人很浅显的认为就是程序的运行效率,代码的执行效率 1.VS 提供了自带的分析工具:performance tool (性 ...
- 第五次作业——python效能分析与几个问题(个人作业)
第五次作业--效能分析与几个问题(个人作业) 前言 阅读了大家对于本课程的目标和规划之后,想必很多同学都跃跃欲试,迫不及待想要提高自身实践能力,那么就从第一个个人项目开始吧,题目要求见下. 阅读 阅读 ...
- 《软件工程和Python》PYTHON效能分析和Django
资料汇总网站:http://www.yzhiliao.com/my/course/55 一..作业下面两个题目任选一题: (1)运用jieba库分词(或者你喜欢的其他库),并把代码发到git上去(不发 ...
- 效能分析——词频统计的java实现方法的第一次改进
java效能分析可以使用JProfiler 词频统计处理的文件为WarAndPeace,大小3282KB约3.3MB,输出结果到文件 在程序本身内开始和结束分别加入时间戳,差值平均为480-490ms ...
- 【week2】 词频统计效能分析
效能统计工具:Jprofiler License Key:L-Larry_Lau@163.com#23874-hrwpdp1sh1wrn#0620 该性能分析工具对服务器进行监听,图一是线程变化图,当 ...
- Application 效能分析有妙招 — 使用 perf 走天下(转载)
转载:http://tech.mozilla.com.tw/posts/1803/application-%E6%95%88%E8%83%BD%E5%88%86%E6%9E%90-%E4%BD%BF% ...
随机推荐
- api帮助文档的制作
在java开发中,往往需要用到别人写的类或是自己写的类被别人拿去用. 而使用类的过程中,类中的方法对使用者而言并不完全透明,这个时候帮助文档可以让我们清楚的了解这个类中的方法该如何调用. 下面简述一下 ...
- ThinkPHP5.1完全开发手册.CHM离线版下载
ThinkPHP5.1完全开发手册.CHM离线版下载 ThinkPHP5.1完全开发手册离线版.CHM下载地址 百度云:链接: https://pan.baidu.com/s/1b4jKJN-8UyI ...
- Python对文件目录的操作
python中对文件.文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块. 得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()返回指定目录下的所有文件和目录 ...
- python中for......else......的使用
for x in range(5): if x == 2: print(x) # break else: print("执行else....") 上述代码:当缺少break关键字时 ...
- Fedora 下面安装FTP服务
1. yum install vsftpd 2. systemctl disable vsftpd.service 3. systemctl stop vsftpd.service 4. system ...
- 【BZOJ4818】序列计数(动态规划,生成函数)
[BZOJ4818]序列计数(生成函数) 题面 BZOJ 题解 显然是求一个多项式的若干次方,并且是循环卷积 或者说他是一个\(dp\)也没有问题 发现项数很少,直接暴力乘就行了(\(FFT\)可能还 ...
- docker 在window 10 专业版的安装 && .net core 在docker的部署
1.如果无法安装Hyper-V,八成是自己的杀毒软件给关了,我的是 电脑管家-启动项里面 给关掉了. 2.如果部署.net core 后 运行 报 An assembly specified in t ...
- 创龙DSP6748开发板上电测试-第一篇
1. 创龙DSP6748开发板测试.2980元的售价很高,我估计新的1200元比较合适,当然创龙定价是按照供需关系的.仿真器XDS100V2卖598元,真是狮子大张口. 2. 上电是5V-2A的电源. ...
- 2019年猪年海报PSD模板-第四部分
14套精美猪年海报,免费猪年海报,下载地址:百度网盘,https://pan.baidu.com/s/1WUO4L5PHIHG5hAurv52_2A
- Xpath语法&示例
一.选取节点常用的路径表达式: 表达式 描述 实例 nodename 选取nodename节点的所有子节点 xpath(‘//div’) 选取了div节点的所有子节点 / 从根节点选取 xpath ...