HADOOP (十一).安装hbase
下载安装包并解压
https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/1.3.1/hbase-1.3.1-bin.tar.gz
…..
[hbase@hadoop1 opt]$ tar -zxvf hbase-1.3.1-bin.tar.gz
设置hbase环境变量
[hbase@hadoop1 opt]$ cd hbase-1.3.1/conf/
[hbase@hadoop1 conf]$ vi hbase-env.sh
#### 看情况设置以下环境变量:
#export JAVA_HOME=/usr/java/jdk1.6.0/
#export HBASE_HEAPSIZE=1G #堆内存
#export HBASE_OPTS="-XX:+UseConcMarkSweepGC" #jvm启动参数
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" #hmaster
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" #hregionserver
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps" #gc相关
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M" #java 参数不太懂,自行修正
…………….
https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/1.3.1/hbase-1.3.1-bin.tar.gz
…..
[hbase@hadoop1 opt]$ tar -zxvf hbase-1.3.1-bin.tar.gz
[hbase@hadoop1 opt]$ cd hbase-1.3.1/conf/
[hbase@hadoop1 conf]$ vi hbase-env.sh
#### 看情况设置以下环境变量:
#export JAVA_HOME=/usr/java/jdk1.6.0/
#export HBASE_HEAPSIZE=1G #堆内存
#export HBASE_OPTS="-XX:+UseConcMarkSweepGC" #jvm启动参数
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" #hmaster
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" #hregionserver
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps" #gc相关
# export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M" #java 参数不太懂,自行修正
…………….参数较多,请逐个检查.
最重要的就是JAVA_HOME,但我在/etc/profile里设置了,这里就不管了.
由于是做实验,这里我就设置一下log目录.关于hbase-evn.sh的设置,以后会详细讲解.
export HBASE_LOG_DIR=/var/log/hbase/
注意:如果没有在/etc/profile中设置HADOOP_CONF_DIR,则需要在hbase-evn.sh中设置HADOOP_CONF_DIR,否则hbase读不到hdfs-site.xml,无法找到hdfs.或者将hdfs-site.xml复制到$HBASE_HOME/conf/下也行.这里的hdfs-site.xml用客户端的配置即可.
配置hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop3,hadoop4,hadoop5</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>HBASE_MANAGES_ZK</name>
<value>false</value>
</property>
</configuration>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop3,hadoop4,hadoop5</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>HBASE_MANAGES_ZK</name>
<value>false</value>
</property>
</configuration>
上面的参数意思分别是:
hbase在hdfs的主目录
zookeeper服务器节点
hbase在zookeeper中的目录
hbase是否是分布式的
是否用hbase自带的zookeeper
启动hbase
首先使用hdfs账号为hbase授权:
[hdfs@hadoop2 root]$ hdfs dfs -mkdir /hbase
[hdfs@hadoop2 root]$ hdfs dfs -chown hbase:hbase /hbase在hadoop1上启动master:
[hbase@hadoop1 hbase-1.3.1]$ bin/hbase-daemon.sh start master在hadoop3 hadoop4 hadoop5上启动hreigonserver:
[hbase@hadoop3 hbase-1.3.1]$ bin/hbase-daemon.sh start regionserver在需要的节点上启动master备份节点:
bin/hbase-daemon.sh start master --backup检测hbase启动情况
1.jps检查
[hbase@hadoop1 hbase-1.3.1]$ jps
25914 HMaster
[hbase@hadoop3 hbase-1.3.1]$ jps
12623 HRegionServe看到master和regionserver都启动了
2.打开hbase web
打开:http://hadoop1:16010/
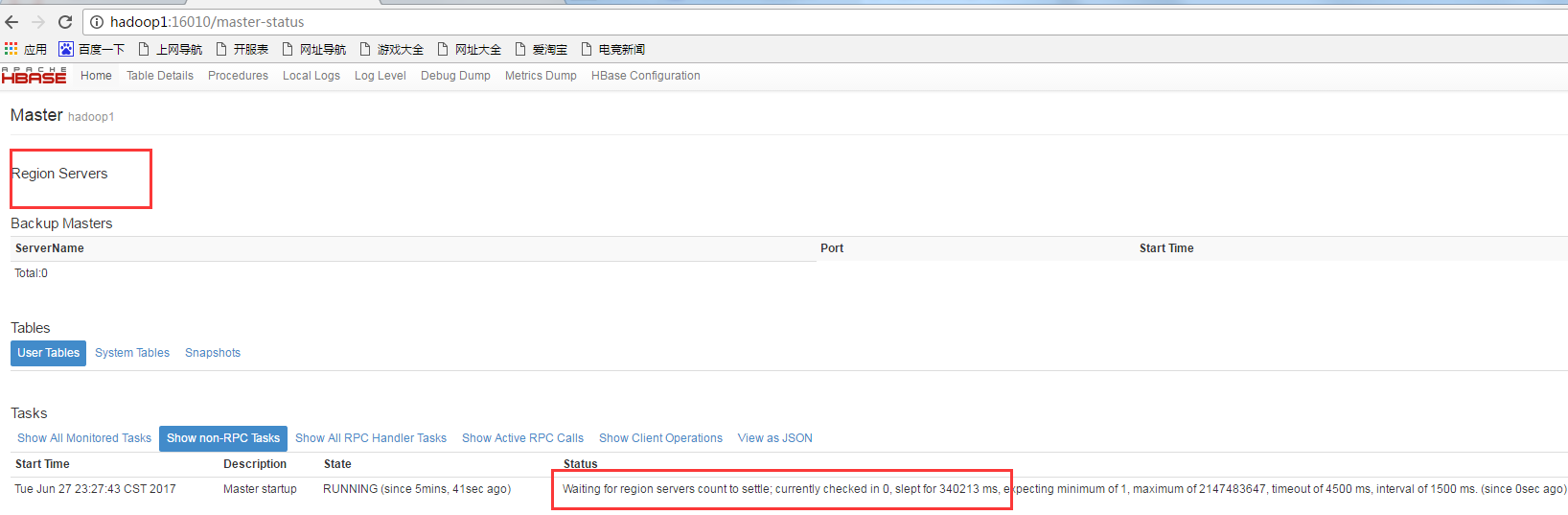
发现没有一个hregoinser连接上master!!!
好吧,打开/var/log/hbase/下的regionserver日志发现:
2017-06-27 23:16:51,039 FATAL [regionserver/hadoop3/192.168.0.12:16020] regionserver.HRegionServer: Master rejected startup because clock is out of sync
org.apache.hadoop.hbase.ClockOutOfSyncException: org.apache.hadoop.hbase.ClockOutOfSyncException: Server hadoop3,16020,1498576600617 has been rejected; Reported time is too far out of sync with master. Time difference of 54158ms > max allowed of 30000ms
at org.apache.hadoop.hbase.master.ServerManager.checkClockSkew(ServerManager.java:410)
at org.apache.hadoop.hbase.master.ServerManager.regionServerStartup(ServerManager.java:276)
at org.apache.hadoop.hbase.master.MasterRpcServices.regionServerStartup(MasterRpcServices.java:363)
at org.apache.hadoop.hbase.protobuf.generated.RegionServerStatusProtos$RegionServerStatusService$2.callBlockingMethod(RegionServerStatusProtos.java:8615)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2339)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:123)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:188)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:168)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:106)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:95)
at org.apache.hadoop.hbase.protobuf.ProtobufUtil.getRemoteException(ProtobufUtil.java:332)
at org.apache.hadoop.hbase.regionserver.HRegionServer.reportForDuty(HRegionServer.java:2337)
at org.apache.hadoop.hbase.regionserver.HRegionServer.run(HRegionServer.java:929)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.apache.hadoop.hbase.ipc.RemoteWithExtrasException(org.apache.hadoop.hbase.ClockOutOfSyncException): org.apache.hadoop.hbase.ClockOutOfSyncException: Server hadoop3,16020,1498576600617 has been rejected; Reported time is too far out of sync with master. T
ime difference of 54158ms > max allowed of 30000ms
at org.apache.hadoop.hbase.master.ServerManager.checkClockSkew(ServerManager.java:410)
at org.apache.hadoop.hbase.master.ServerManager.regionServerStartup(ServerManager.java:276)原因是regionser和master的时间差太多了!又检查了一下,发现机器上的ntp服务挂了!!
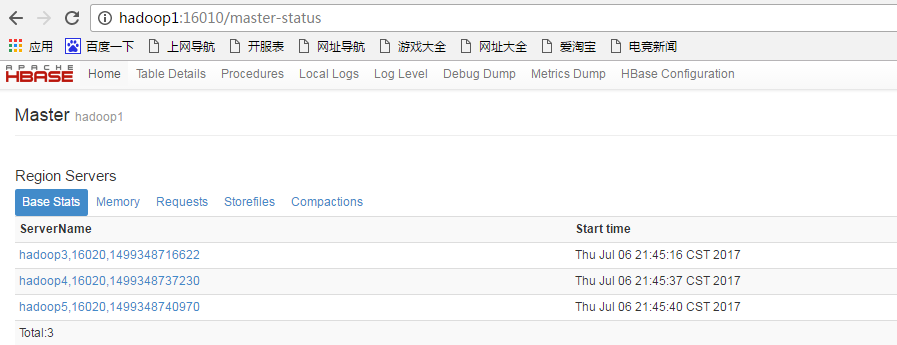
设置各机器的时间:
date -s '2017-07-06 21:36:40'再次启动各进程,打开web页面,发现连接上master了:
测试hbase shell
[hbase@hadoop5 hbase-1.3.1]$ bin/hbase shell
hbase(main):001:0> create 'test','cf1'
0 row(s) in 4.9050 seconds
=> Hbase::Table - test
hbase(main):002:0> list
TABLE
test
hbase(main):004:0> put 'test', 'row1', 'cf1:a', 'value1'
0 row(s) in 0.0170 seconds
hbase(main):005:0> put 'test', 'row2', 'cf1:b', 'value2'
0 row(s) in 0.0090 seconds
hbase(main):012:0* scan test
ArgumentError: wrong number of arguments (0 for 2)
hbase(main):013:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf1:a, timestamp=1499349174471, value=value1
row2 column=cf1:b, timestamp=1499349174533, value=value2
2 row(s) in 0.1140 seconds
[hbase@hadoop5 hbase-1.3.1]$ bin/hbase shell
hbase(main):001:0> create 'test','cf1'
0 row(s) in 4.9050 seconds
=> Hbase::Table - test
hbase(main):002:0> list
TABLE
test
hbase(main):004:0> put 'test', 'row1', 'cf1:a', 'value1'
0 row(s) in 0.0170 seconds
hbase(main):005:0> put 'test', 'row2', 'cf1:b', 'value2'
0 row(s) in 0.0090 seconds
hbase(main):012:0* scan test
ArgumentError: wrong number of arguments (0 for 2)
hbase(main):013:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf1:a, timestamp=1499349174471, value=value1
row2 column=cf1:b, timestamp=1499349174533, value=value2
2 row(s) in 0.1140 seconds
说明hbase能正常使用
HADOOP (十一).安装hbase的更多相关文章
- 从零自学Hadoop(19):HBase介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一篇, ...
- 在Hadoop伪分布式模式下安装Hbase
安装环境:Hadoop 1.2.0, Java 1.7.0_21 1.下载/解压 在hbase官网上选择自己要下的hbase版本,我选择的是hbase-0.94.8. 下载后解压到/usr/local ...
- hadoop生态圈安装详解(hadoop+zookeeper+hbase+pig+hive)
-------------------------------------------------------------------* 目录 * I hadoop分布式安装 * II zoo ...
- hadoop安装hbase
1.安装hadoop hadoop安装请参考我的centoos 安装hadoop集群 在安装hadoop的基础上新增了两台slave机器,新增后的配置为 H30(192.168.3.238) mast ...
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置 配置H ...
- 沉淀,再出发——在Hadoop集群之上安装hbase
在Hadoop集群之上安装hbase 一.安装准备 首先我们确保在ubuntu16.04上安装了以下的产品,java1.8及其以上,ssh,hadoop集群,其次,我们需要从hbase的官网上下载并安 ...
- Hadoop 伪分布式上安装 HBase
hbase下载:点此链接 (P.S.下载带bin的) 下载文件放入虚拟机文件夹,打开,放在自己指定的文件夹 -src.tar.gz -C /home/software/ 修改环境配置 gedit / ...
- hadoop备战:hbase的分布式安装经验
配置HBase时,首先考虑的肯定是Hbase版本号与你所装的hadoop版本号是否匹配.这一点我在之前 的博客中已经说明清楚,hadoop版本号与hbase版本号的匹配度,那是官方提供的.以下的实验就 ...
- WIN10下安装HBASE教程
工作需要,现在开始做大数据开发了,通过下面的配置步骤,你可以在win10系统中,部署出一套hadoop+hbase,便于单机测试调试开发. 准备资料: 1. hadoop-2.7.2: https:/ ...
随机推荐
- 如何在 Mac 上卸载 Java?
使用终端卸载 Oracle Java 注:要卸载 Java,您必须具有管理员权限,并且必须以 root 用户身份或者使用 sudo 工具来执行删除命令. 按照下面所示,删除一个目录和一个文件(符号链接 ...
- 学习笔记(1)centos7 下安装nginx
学习笔记(1)centos7 下安装nginx 这里我是通过来自nginx.org的nginx软件包进行安装的. 1.首先为centos设置添加nginx的yum存储库 1.通过vi命令创建一个rep ...
- 原生js实现简单的随机点名系统
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8 ...
- 竞赛题解 - CF Round #524 Div.2
CF Round #524 Div.2 - 竞赛题解 不容易CF有一场下午的比赛,开心的和一个神犇一起报了名 被虐爆--前两题水过去,第三题卡了好久,第四题毫无头绪QwQ Codeforces 传送门 ...
- 复习宝典之SpringMVC
查看更多宝典,请点击<金三银四,你的专属面试宝典> 第七章:SpringMVC MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(co ...
- border-radius__边框圆角
1.四个参数: border-radius: 值1 值2 值3 值4;顺序:从左开始,顺时针顺 div{ width: 200px; height: 100px; background-color: ...
- opencv3 学习四 - 图像减色
程序如下 #include "opencv2/opencv.hpp" using namespace cv; int main() { // 灰度图 Mat original = ...
- 常用贴片三极管型号与丝印的对应关系(SOT23)
个人常用贴片三极管型号与丝印的对应关系(SOT23): 丝印:Y1 型号:8050,NPN型三极管 丝印:Y2 型号:8550,PNP型三极管 丝印:L6 ...
- MySQL集群-PXC搭建以及使用innobackupex工具进行全局备份和增量备份
环境:centos7 vm1:10.154.47.236 vm2:10.154.52.189 vm3:10.105.12.50 目的:pxc使用三个节点构建mysql集群,使用innobackupex ...
- Python语言发展的关键时间节点
1989年:Python想法的产生 1991年:发布最早的Python可用版本 2000年:发布Python2.0 2010年:发布Python2.x系列的最后一个版本,主版本号为2.7 2008年: ...