ArgoWorkflow教程(四)---Workflow & 日志归档

上一篇我们分析了argo-workflow 中的 artifact,包括 artifact-repository 配置以及 Workflow 中如何使用 artifact。本篇主要分析流水线 GC 以及归档,防止无限占用集群中 etcd 的空间。
1. 概述
因为 ArgoWorkflow 是用 CRD 方式实现的,不需要外部存储服务也可以正常运行:
- 运行记录使用 Workflow CR 对象存储
- 运行日志则存放在 Pod 中,通过 kubectl logs 方式查看
- 因此需要保证 Pod 不被删除,否则就无法查看了
但是也正因为所有数据都存放在集群中,当数据量大之后 etcd 存储压力会很大,最终影响到集群稳定性。
为了解决该问题 ArgoWorkflow 提供了归档功能,将历史数据归档到外部存储,以降低 etcd 的存储压力。
具体实现为:
- 1)将 Workflow 对象会存储到 Postgres(或 MySQL)
- 2)将 Pod 对应的日志会存储到 S3,因为日志数据量可能会比较大,因此没有直接存 PostgresQL。
为了提供归档功能,需要依赖两个存储服务:
- Postgres:外部数据库,用于存储归档后的工作流记录
- minio:提供 S3 存储,用于存储 Workflow 中生成的 artifact 以及已归档工作流的 Pod 日志
因此,如果不需要存储太多 Workflow 记录及日志查看需求的话,就不需要使用归档功能,定时清理集群中的数据即可。
2.Workflow GC
Argo Workflows 有个工作流执行记录(Workflow)的清理机制,也就是 Garbage Collect(GC)。GC 机制可以避免有太多的执行记录, 防止 Kubernetes 的后端存储 Etcd 过载。
开启
我们可以在 ConfigMap 中配置期望保留的工作执行记录数量,这里支持为不同状态的执行记录设定不同的保留数量。
首先查看 argo-server 启动命令中指定的是哪个 Configmap
# kubectl -n argo get deploy argo-workflows-server -oyaml|grep args -A 5
- args:
- server
- --configmap=argo-workflows-workflow-controller-configmap
- --auth-mode=server
- --secure=false
- --loglevel
可以看到,这里是用的argo-workflows-workflow-controller-configmap,那么修改这个即可。
配置如下:
apiVersion: v1
data:
retentionPolicy: |
completed: 3
failed: 3
errored: 3
kind: ConfigMap
metadata:
name: argo-workflows-workflow-controller-configmap
namespace: argo
需要注意的是,这里的清理机制会将多余的 Workflow 资源从 Kubernetes 中删除。如果希望能更多历史记录的话,建议启用并配置好归档功能。
然后重启 argo-workflow-controller 和 argo-server
kubectl -n argo rollout restart deploy argo-workflows-server
kubectl -n argo rollout restart deploy argo-workflows-workflow-controller
测试
运行多个流水线,看下是否会自动清理
for ((i=1; i<=10; i++)); do
cat <<EOF | kubectl create -f -
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world-
spec:
entrypoint: whalesay
templates:
- name: whalesay
container:
image: docker/whalesay
command: [cowsay]
args: ["hello world $i"]
EOF
done
创建了 10 个 Workflow,看一下运行完成后会不会自动清理掉
[root@lixd-argo archive]# k get wf
NAME STATUS AGE MESSAGE
hello-world-6hgb2 Succeeded 74s
hello-world-6pl5w Succeeded 37m
hello-world-9fdmv Running 21s
hello-world-f464p Running 18s
hello-world-kqwk4 Running 16s
hello-world-kxbtk Running 18s
hello-world-p88vd Running 19s
hello-world-q7xbk Running 22s
hello-world-qvv7d Succeeded 10m
hello-world-t94pb Running 23s
hello-world-w79q6 Running 15s
hello-world-wl4vl Running 23s
hello-world-znw7w Running 23s
过一会再看
[root@lixd-argo archive]# k get wf
NAME STATUS AGE MESSAGE
hello-world-f464p Succeeded 102s
hello-world-kqwk4 Succeeded 100s
hello-world-w79q6 Succeeded 99s
可以看到,只保留了 3 条记录,其他的都被清理了,说明 GC 功能 ok。
3. 流水线归档
https://argo-workflows.readthedocs.io/en/stable/workflow-archive/
开启 GC 功能之后,会自动清理 Workflow 以保证 etcd 不被占满,但是也无法查询之前的记录了。
ArgoWorkflow 也提供了流水线归档功能,来解决该问题。
通过将 Workflow 记录到外部 Postgres 数据库来实现持久化,从而满足查询历史记录的需求。
部署 Postgres
首先,简单使用 helm 部署一个 AIO 的Postgres
REGISTRY_NAME=registry-1.docker.io
REPOSITORY_NAME=bitnamicharts
storageClass="local-path"
# postgres 账号的密码
adminPassword="postgresadmin"
helm install pg-aio oci://$REGISTRY_NAME/$REPOSITORY_NAME/postgresql \
--set global.storageClass=$storageClass \
--set global.postgresql.auth.postgresPassword=$adminPassword \
--set global.postgresql.auth.database=argo
配置流水线归档
同样的,在 argo 配置文件中增加 persistence 相关配置即可:
persistence:
archive: true
postgresql:
host: pg-aio-postgresql.default.svc.cluster.local
port: 5432
database: postgres
tableName: argo_workflows
userNameSecret:
name: argo-postgres-config
key: username
passwordSecret:
name: argo-postgres-config
key: password
argo-workflows-workflow-controller-configmap 完整内容如下:
apiVersion: v1
data:
retentionPolicy: |
completed: 3
failed: 3
errored: 3
persistence: |
archive: true
archiveTTL: 180d
postgresql:
host: pg-aio-postgresql.default.svc.cluster.local
port: 5432
database: argo
tableName: argo_workflows
userNameSecret:
name: argo-postgres-config
key: username
passwordSecret:
name: argo-postgres-config
key: password
kind: ConfigMap
metadata:
name: argo-workflows-workflow-controller-configmap
namespace: argo
然后还要创建一个 secret
kubectl create secret generic argo-postgres-config -n argo --from-literal=password=postgresadmin --from-literal=username=postgres
可能还需要给 rbac,否则 Controller 无法查询 secret
kubectl create clusterrolebinding argo-workflow-controller-admin --clusterrole=admin --serviceaccount=argo:argo-workflows-workflow-controller
然后重启 argo-workflow-controller 和 argo-server
kubectl -n argo rollout restart deploy argo-workflows-server
kubectl -n argo rollout restart deploy argo-workflows-workflow-controller
在启用存档的情况下启动工作流控制器时,将在数据库中创建以下表:
argo_workflowsargo_archived_workflowsargo_archived_workflows_labelsschema_history
归档记录 GC
配置文件中的 archiveTTL 用于指定压缩到 Postgres 中的 Workflow 记录存活时间,argo Controller 会根据该配置自动删除到期的记录,若不指定该值则不会删除。
具体如下:
func (r *workflowArchive) DeleteExpiredWorkflows(ttl time.Duration) error {
rs, err := r.session.SQL().
DeleteFrom(archiveTableName).
Where(r.clusterManagedNamespaceAndInstanceID()).
And(fmt.Sprintf("finishedat < current_timestamp - interval '%d' second", int(ttl.Seconds()))).
Exec()
if err != nil {
return err
}
rowsAffected, err := rs.RowsAffected()
if err != nil {
return err
}
log.WithFields(log.Fields{"rowsAffected": rowsAffected}).Info("Deleted archived workflows")
return nil
}
不过删除任务默认每天执行一次,因此就算配置为 1m 分钟也不会立即删除。
func (wfc *WorkflowController) archivedWorkflowGarbageCollector(stopCh <-chan struct{}) {
defer runtimeutil.HandleCrash(runtimeutil.PanicHandlers...)
periodicity := env.LookupEnvDurationOr("ARCHIVED_WORKFLOW_GC_PERIOD", 24*time.Hour)
if wfc.Config.Persistence == nil {
log.Info("Persistence disabled - so archived workflow GC disabled - you must restart the controller if you enable this")
return
}
if !wfc.Config.Persistence.Archive {
log.Info("Archive disabled - so archived workflow GC disabled - you must restart the controller if you enable this")
return
}
ttl := wfc.Config.Persistence.ArchiveTTL
if ttl == config.TTL(0) {
log.Info("Archived workflows TTL zero - so archived workflow GC disabled - you must restart the controller if you enable this")
return
}
log.WithFields(log.Fields{"ttl": ttl, "periodicity": periodicity}).Info("Performing archived workflow GC")
ticker := time.NewTicker(periodicity)
defer ticker.Stop()
for {
select {
case <-stopCh:
return
case <-ticker.C:
log.Info("Performing archived workflow GC")
err := wfc.wfArchive.DeleteExpiredWorkflows(time.Duration(ttl))
if err != nil {
log.WithField("err", err).Error("Failed to delete archived workflows")
}
}
}
}
需要设置环境变量 ARCHIVED_WORKFLOW_GC_PERIOD 来调整该值,修改 argo-workflows-workflow-controller 增加 env,就像这样:
env:
- name: ARCHIVED_WORKFLOW_GC_PERIOD
value: 1m
测试
接下来创建 Workflow 看下是否测试
for ((i=1; i<=10; i++)); do
cat <<EOF | kubectl create -f -
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world-
spec:
entrypoint: whalesay
templates:
- name: whalesay
container:
image: docker/whalesay
command: [cowsay]
args: ["hello world $i"]
EOF
done
查看下是 postgres 中是否生成归档记录
export POSTGRES_PASSWORD=postgresadmin
kubectl run postgresql-dev-client --rm --tty -i --restart='Never' --namespace default --image docker.io/bitnami/postgresql:14.1.0-debian-10-r80 --env="PGPASSWORD=$POSTGRES_PASSWORD" --command -- psql --host pg-aio-postgresql -U postgres -d argo -p 5432
按 Enter 进入 Pod 后直接查询即可
# 查询表
argo-# \dt
List of relations
Schema | Name | Type | Owner
--------+--------------------------------+-------+----------
public | argo_archived_workflows | table | postgres
public | argo_archived_workflows_labels | table | postgres
public | argo_workflows | table | postgres
public | schema_history | table | postgres
(4 rows)
# 查询记录
argo=# select name,phase from argo_archived_workflows;
name | phase
-------------------+-----------
hello-world-s8v4f | Succeeded
hello-world-6pl5w | Succeeded
hello-world-qvv7d | Succeeded
hello-world-vgjqr | Succeeded
hello-world-g2s8f | Succeeded
hello-world-jghdm | Succeeded
hello-world-fxtvk | Succeeded
hello-world-tlv9k | Succeeded
hello-world-bxcg2 | Succeeded
hello-world-f6mdw | Succeeded
hello-world-dmvj6 | Succeeded
hello-world-btknm | Succeeded
(12 rows)
# \q 退出
argo=# \q
可以看到,Postgres 中已经存储好了归档的 Workflow,这样需要查询历史记录时到 Postgres 查询即可。
将 archiveTTL 修改为 1 分钟,然后重启 argo,等待 1 至2 分钟后,再次查看
argo=# select name,phase from argo_archived_workflows;
name | phase
------+-------
(0 rows)
argo=#
可以看到,所有记录都因为 TTL 被清理了,这样也能保证外部 Postgres 中的数据不会越累积越多。
4. Pod 日志归档
https://argo-workflows.readthedocs.io/en/stable/configure-archive-logs/
流水线归档实现了流水线持久化,即使把集群中的 Workflow 对象删除了,也可以从 Postgres 中查询到记录以及状态等信息。
但是流水线执行的日志却分散在对应 Pod 中的,如果 Pod 被删除了,日志就无法查看了,因此我们还需要做日志归档。
配置 Pod 归档
全局配置
在 argo 配置文件中开启 Pod 日志归档并配置好 S3 信息。
具体配置如下:
和第三篇配置的 artifact 一样,只是多了一个
archiveLogs: true
artifactRepository:
archiveLogs: true
s3:
endpoint: minio.default.svc:9000
bucket: argo
insecure: true
accessKeySecret:
name: my-s3-secret
key: accessKey
secretKeySecret:
name: my-s3-secret
key: secretKey
完整配置如下:
apiVersion: v1
data:
retentionPolicy: |
completed: 3
failed: 3
errored: 3
persistence: |
archive: true
postgresql:
host: pg-aio-postgresql.default.svc.cluster.local
port: 5432
database: argo
tableName: argo_workflows
userNameSecret:
name: argo-postgres-config
key: username
passwordSecret:
name: argo-postgres-config
key: password
artifactRepository: |
archiveLogs: true
s3:
endpoint: minio.default.svc:9000
bucket: argo
insecure: true
accessKeySecret:
name: my-s3-secret
key: accessKey
secretKeySecret:
name: my-s3-secret
key: secretKey
kind: ConfigMap
metadata:
name: argo-workflows-workflow-controller-configmap
namespace: argo
注意:根据第三篇分析 artifact,argo 中关于 artifactRepository 的信息包括三种配置方式:
- 1)全局配置
- 2)命名空间默认配置
- 3)Workflow 中指定配置
这里是用的全局配置方式,如果 Namespace 级别或者 Workflow 级别也配置了 artifactRepository 并指定了不开启日志归档,那么也不会归档的。
然后重启 argo
kubectl -n argo rollout restart deploy argo-workflows-server
kubectl -n argo rollout restart deploy argo-workflows-workflow-controller
在 Workflow & template 中配置
配置整个工作流都需要归档
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: archive-location-
spec:
archiveLogs: true
entrypoint: whalesay
templates:
- name: whalesay
container:
image: docker/whalesay:latest
command: [cowsay]
args: ["hello world"]
配置工作流中的某一个 template 需要归档。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: archive-location-
spec:
entrypoint: whalesay
templates:
- name: whalesay
container:
image: docker/whalesay:latest
command: [cowsay]
args: ["hello world"]
archiveLocation:
archiveLogs: true
小结
3 个地方都可以配置是否归档,就还挺麻烦的,根据官方文档,各个配置优先级如下:
workflow-controller config (on) > workflow spec (on/off) > template (on/off)
| Controller Config Map | Workflow Spec | Template | are we archiving logs? |
|---|---|---|---|
| true | true | true | true |
| true | true | false | true |
| true | false | true | true |
| true | false | false | true |
| false | true | true | true |
| false | true | false | false |
| false | false | true | true |
| false | false | false | false |
对应的代码实现:
// IsArchiveLogs determines if container should archive logs
// priorities: controller(on) > template > workflow > controller(off)
func (woc *wfOperationCtx) IsArchiveLogs(tmpl *wfv1.Template) bool {
archiveLogs := woc.artifactRepository.IsArchiveLogs()
if !archiveLogs {
if woc.execWf.Spec.ArchiveLogs != nil {
archiveLogs = *woc.execWf.Spec.ArchiveLogs
}
if tmpl.ArchiveLocation != nil && tmpl.ArchiveLocation.ArchiveLogs != nil {
archiveLogs = *tmpl.ArchiveLocation.ArchiveLogs
}
}
return archiveLogs
}
建议配置全局的就行了。
测试
接下来创建 Workflow 看下是否测试
cat <<EOF | kubectl create -f -
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world-
spec:
entrypoint: whalesay
templates:
- name: whalesay
container:
image: docker/whalesay
command: [cowsay]
args: ["hello world"]
EOF
等待 Workflow 运行完成
# k get po
NAME READY STATUS RESTARTS AGE
hello-world-6pl5w 0/2 Completed 0 53s
# k get wf
NAME STATUS AGE MESSAGE
hello-world-6pl5w Succeeded 55s
到 S3 查看是否有日志归档文件
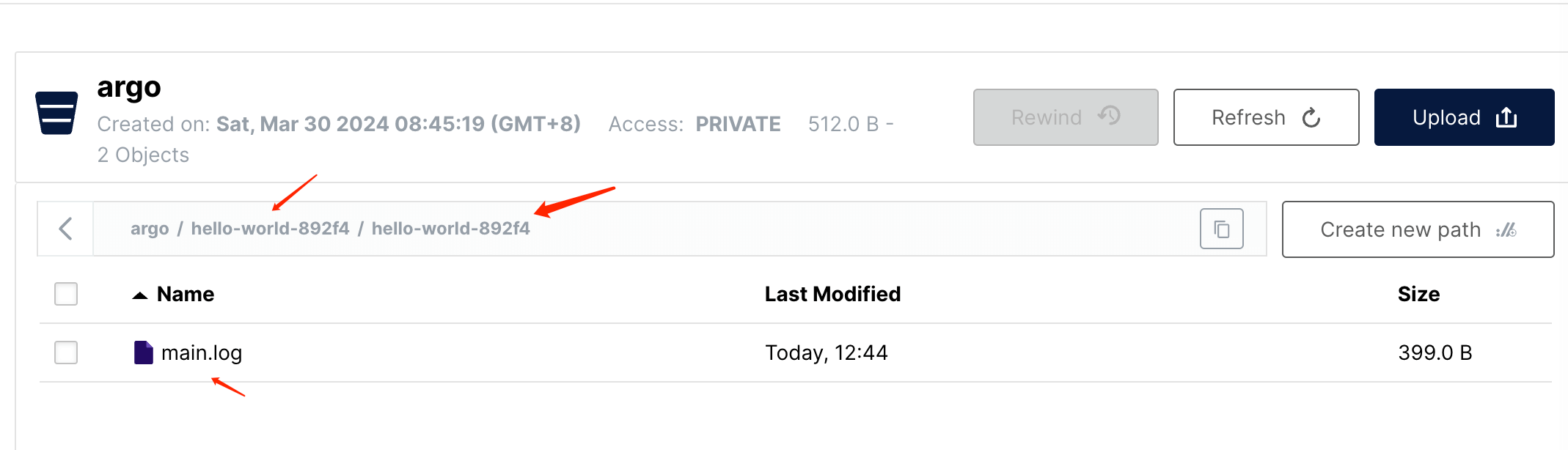
可以看到,在指定 bucket 里已经存储了一个日志文件,以$bucket/$workflowName/$stepName 格式命名。
正常一个 Workflow 都会有多个 Step,每一个 step 分一个目录存储
内容就是 Pod 日志,具体如下:
_____________
< hello world >
-------------
\
\
\
## .
## ## ## ==
## ## ## ## ===
/""""""""""""""""___/ ===
~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
\______ o __/
\ \ __/
\____\______/
5. 小结
【ArgoWorkflow 系列】持续更新中,搜索公众号【探索云原生】订阅,阅读更多文章。

总结一下,本文主要分析了以下 3 部分内容:
- 1)开启 GC,自动清理运行完成的 Workflow 记录,避免占用 etcd 空间
- 2)开启流水线归档,将 Workflow 记录存储到外部 Postgres,便于查询历史记录
- 3)开启 Pod 日志归档,将流水线每一步 Pod 日志记录到 S3,便于查询,否则 Pod 删除就无法查询了
生产使用,一般都建议开启相关的清理和归档功能,如果全存储到 etcd,难免会影响到集群性能和稳定性。
ArgoWorkflow教程(四)---Workflow & 日志归档的更多相关文章
- RMAN详细教程(四):备份脚本实战操作
RMAN详细教程(一):基本命令代码 RMAN详细教程(二):备份.检查.维护.恢复 RMAN详细教程(三):备份脚本的组件和注释 RMAN详细教程(四):备份脚本实战操作 1.为了安全起见,先将数据 ...
- 黄聪:Microsoft Enterprise Library 5.0 系列教程(四) Logging Application Block
原文:黄聪:Microsoft Enterprise Library 5.0 系列教程(四) Logging Application Block 企业库日志应用程序模块工作原理图: 从上图我们可以 ...
- 微信开放平台 公众号第三方平台开发 教程四 代公众号调用接口的SDK和demo
原文:微信开放平台 公众号第三方平台开发 教程四 代公众号调用接口的SDK和demo 教程导航: 微信开放平台 公众号第三方平台开发 教程一 平台介绍 微信开放平台 公众号第三方平台开发 教程二 创建 ...
- Nginx教程(四) Location配置与ReWrite语法
Nginx教程(四) Location配置与ReWrite语法 1 Location语法规则 1.1 Location规则 语法规则: location [=|~|~*|^~] /uri/ {- } ...
- Fastify 系列教程四 (求对象、响应对象和插件)
Fastify 系列教程: Fastify 系列教程一 (路由和日志) Fastify 系列教程二 (中间件.钩子函数和装饰器) Fastify 系列教程三 (验证.序列化和生命周期) Fastify ...
- MySQL5.7 四种日志文件
mysql 日志包括:错误日志,二进制日志,通用查询日志,慢日志等 一:通用查询日志: 记录建立的客户端连接和执行的语句 1)show variables like '%verision%'; 显示数 ...
- Spring Boot 2.X(十四):日志功能 Logback
Logback 简介 Logback 是由 SLF4J 作者开发的新一代日志框架,用于替代 log4j. 主要特点是效率更高,架构设计够通用,适用于不同的环境. Logback 分为三个模块:logb ...
- Nginx教程(四) Location配置与ReWrite语法 (转)
Nginx教程(四) Location配置与ReWrite语法 1 Location语法规则 1.1 Location规则 语法规则: location [=|~|~*|^~] /uri/ {… } ...
- redis学习教程四《管理、备份、客户端连接》
redis学习教程四<管理.备份.客户端连接> 一:Redis服务器命令 Redis服务器命令 下表列出了与Redis服务器相关的一些基本命令. 序号 命令 说明 1 BGREWRITE ...
- CRL快速开发框架系列教程四(删除数据)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
随机推荐
- 推荐王牌远程桌面软件Getscreen,所有的远程桌面软件中使用最简单的一个
今天要推荐的远程桌面软件就是这款叫Getscreen的,推荐理由挺简单: 简单易用:只需要两步就能轻松连上远程桌面 第一步:在需要被远程连接的机器上下载它的Agent程序并启动,点击Send获得一个链 ...
- var 和 let 在 jQuery中的区别
下面通过代码案例来进一步解释 var 和 let 在 jQuery link 函数中的区别: (function ($) { $.fn.link = function () { // Example ...
- oeasy教您玩转vim - 89 - # 高亮细节Highlight
高亮细节 highight 回忆 这个自动命令 autocmd 还是很方便的 打开时.保存时就会有自动执行的操作 自动命令有这么几大元素 {event} 触发事件 {pattern} 文件模式 { ...
- JavaScript '&&' 与 '||' 操作符
"&&" 操作符 1.如果第一个操作数是对象,则返回第二操作数 var res = {} && "Hello";//Hello ...
- Unity入门学习日记(一)
UGUI的初步使用 1. Canvas 使用UI的时候,所有的UI元素都作为Canvas的子节点存在于Canvas中,如果创建UI元素时没有Canvas作为父节点,会自动生成一个Canvas,是一位& ...
- Python和RPA网页自动化-异常处理Try方法
我们在跑自动化时为了捕获和处理异常,会增加异常处理Try方法.下面来看看Python和RPA网页自动化中异常处理Try的用法 1.Python中异常处理try的用法 try: test = " ...
- 从.net开发做到云原生运维(六)——分布式应用运行时Dapr
1. 前言 上一篇文章我们讲了K8s的一些概念,K8s真的是带来了很多新玩法,就像我们今天这篇文章的主角Dapr一样,Dapr也能在K8s里以云原生的方式运行.当然它也可以和容器一起运行,或者是CLI ...
- 大语言模型(LLM)运行报错:module ‘streamlit‘ has no attribute ‘chat_message‘
参考: https://blog.csdn.net/weixin_45748921/article/details/134645308 问题在于版本不匹配,深究一下为什么各个版本软件不匹配,发现原因是 ...
- Ubuntu18.04下 修改conda环境和缓存默认路径
查看conda 的默认环境和缓存默认路径:conda info conda环境和缓存的默认路径(envs directories 和 package cache) envs directories ...
- python中numpy.random.seed设置随机种子是否影响子进程
给出代码: from multiprocessing import Process import numpy as np class NN(Process): def __init__(self, i ...